 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffordance-Guided Diffusion Prior for 3D Hand Reconstruction
Oct 01, 2025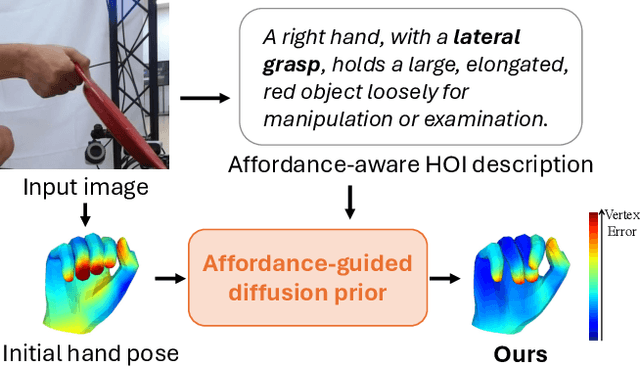
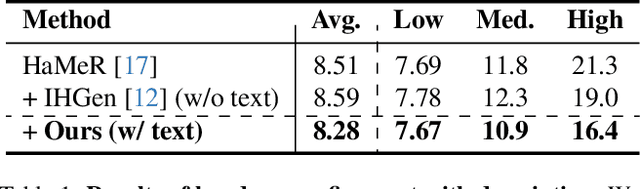
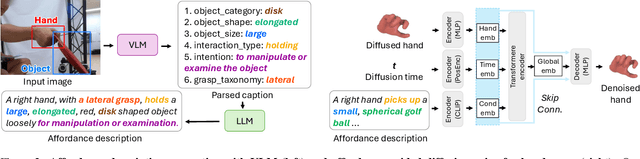
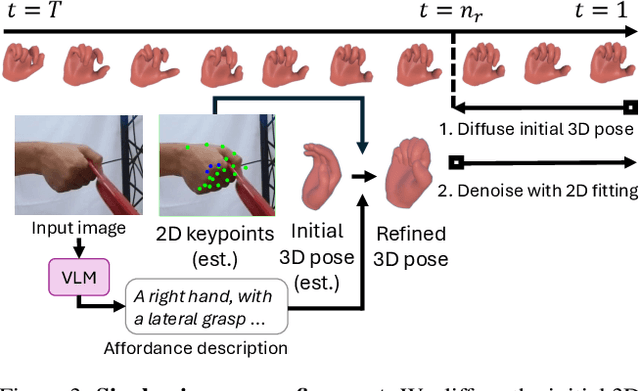
How can we reconstruct 3D hand poses when large portions of the hand are heavily occluded by itself or by objects? Humans often resolve such ambiguities by leveraging contextual knowledge -- such as affordances, where an object's shape and function suggest how the object is typically grasped. Inspired by this observation, we propose a generative prior for hand pose refinement guided by affordance-aware textual descriptions of hand-object interactions (HOI). Our method employs a diffusion-based generative model that learns the distribution of plausible hand poses conditioned on affordance descriptions, which are inferred from a large vision-language model (VLM). This enables the refinement of occluded regions into more accurate and functionally coherent hand poses. Extensive experiments on HOGraspNet, a 3D hand-affordance dataset with severe occlusions, demonstrate that our affordance-guided refinement significantly improves hand pose estimation over both recent regression methods and diffusion-based refinement lacking contextual reasoning.
EmoSign: A Multimodal Dataset for Understanding Emotions in American Sign Language
May 20, 2025Unlike spoken languages where the use of prosodic features to convey emotion is well studied, indicators of emotion in sign language remain poorly understood, creating communication barriers in critical settings. Sign languages present unique challenges as facial expressions and hand movements simultaneously serve both grammatical and emotional functions. To address this gap, we introduce EmoSign, the first sign video dataset containing sentiment and emotion labels for 200 American Sign Language (ASL) videos. We also collect open-ended descriptions of emotion cues. Annotations were done by 3 Deaf ASL signers with professional interpretation experience. Alongside the annotations, we include baseline models for sentiment and emotion classification. This dataset not only addresses a critical gap in existing sign language research but also establishes a new benchmark for understanding model capabilities in multimodal emotion recognition for sign languages. The dataset is made available at https://huggingface.co/datasets/catfang/emosign.
SiMHand: Mining Similar Hands for Large-Scale 3D Hand Pose Pre-training
Feb 21, 2025



We present a framework for pre-training of 3D hand pose estimation from in-the-wild hand images sharing with similar hand characteristics, dubbed SimHand. Pre-training with large-scale images achieves promising results in various tasks, but prior methods for 3D hand pose pre-training have not fully utilized the potential of diverse hand images accessible from in-the-wild videos. To facilitate scalable pre-training, we first prepare an extensive pool of hand images from in-the-wild videos and design our pre-training method with contrastive learning. Specifically, we collect over 2.0M hand images from recent human-centric videos, such as 100DOH and Ego4D. To extract discriminative information from these images, we focus on the similarity of hands: pairs of non-identical samples with similar hand poses. We then propose a novel contrastive learning method that embeds similar hand pairs closer in the feature space. Our method not only learns from similar samples but also adaptively weights the contrastive learning loss based on inter-sample distance, leading to additional performance gains. Our experiments demonstrate that our method outperforms conventional contrastive learning approaches that produce positive pairs sorely from a single image with data augmentation. We achieve significant improvements over the state-of-the-art method (PeCLR) in various datasets, with gains of 15% on FreiHand, 10% on DexYCB, and 4% on AssemblyHands. Our code is available at https://github.com/ut-vision/SiMHand.
Pre-Training for 3D Hand Pose Estimation with Contrastive Learning on Large-Scale Hand Images in the Wild
Sep 15, 2024



We present a contrastive learning framework based on in-the-wild hand images tailored for pre-training 3D hand pose estimators, dubbed HandCLR. Pre-training on large-scale images achieves promising results in various tasks, but prior 3D hand pose pre-training methods have not fully utilized the potential of diverse hand images accessible from in-the-wild videos. To facilitate scalable pre-training, we first prepare an extensive pool of hand images from in-the-wild videos and design our method with contrastive learning. Specifically, we collected over 2.0M hand images from recent human-centric videos, such as 100DOH and Ego4D. To extract discriminative information from these images, we focus on the similarity of hands; pairs of similar hand poses originating from different samples, and propose a novel contrastive learning method that embeds similar hand pairs closer in the latent space. Our experiments demonstrate that our method outperforms conventional contrastive learning approaches that produce positive pairs sorely from a single image with data augmentation. We achieve significant improvements over the state-of-the-art method in various datasets, with gains of 15% on FreiHand, 10% on DexYCB, and 4% on AssemblyHands.
Benchmarks and Challenges in Pose Estimation for Egocentric Hand Interactions with Objects
Mar 25, 2024
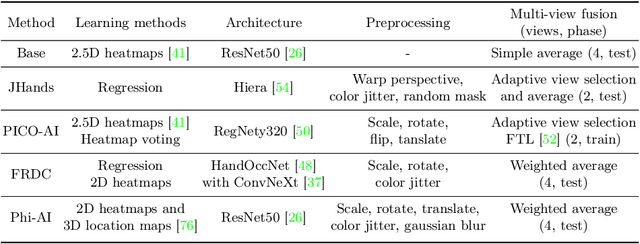
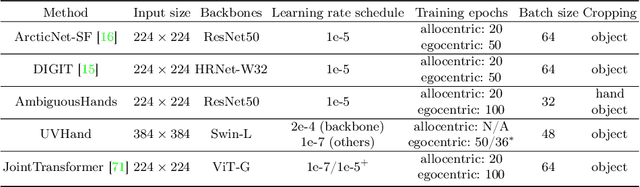
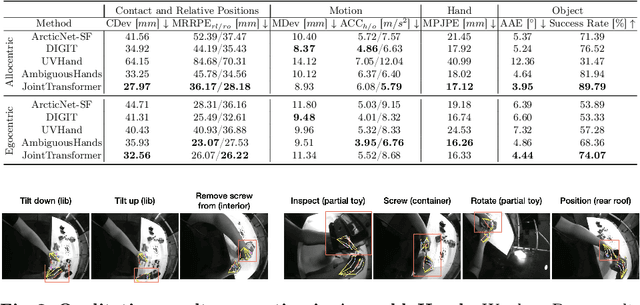
We interact with the world with our hands and see it through our own (egocentric) perspective. A holistic 3D understanding of such interactions from egocentric views is important for tasks in robotics, AR/VR, action recognition and motion generation. Accurately reconstructing such interactions in 3D is challenging due to heavy occlusion, viewpoint bias, camera distortion, and motion blur from the head movement. To this end, we designed the HANDS23 challenge based on the AssemblyHands and ARCTIC datasets with carefully designed training and testing splits. Based on the results of the top submitted methods and more recent baselines on the leaderboards, we perform a thorough analysis on 3D hand(-object) reconstruction tasks. Our analysis demonstrates the effectiveness of addressing distortion specific to egocentric cameras, adopting high-capacity transformers to learn complex hand-object interactions, and fusing predictions from different views. Our study further reveals challenging scenarios intractable with state-of-the-art methods, such as fast hand motion, object reconstruction from narrow egocentric views, and close contact between two hands and objects. Our efforts will enrich the community's knowledge foundation and facilitate future hand studies on egocentric hand-object interactions.
Single-to-Dual-View Adaptation for Egocentric 3D Hand Pose Estimation
Mar 09, 2024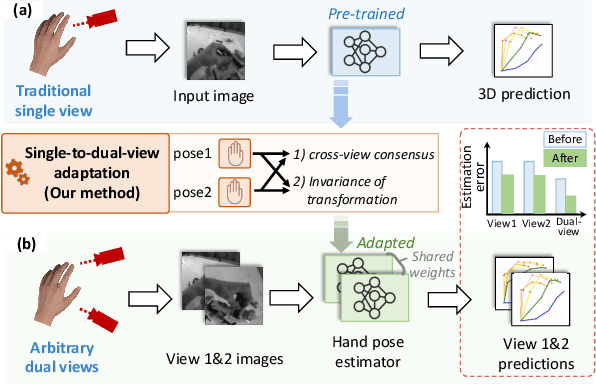

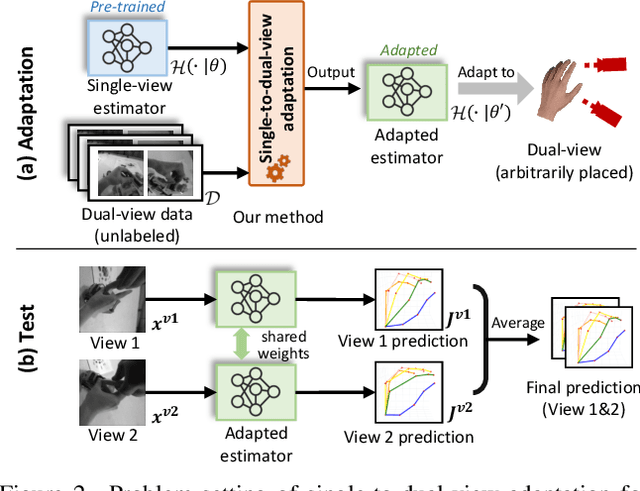
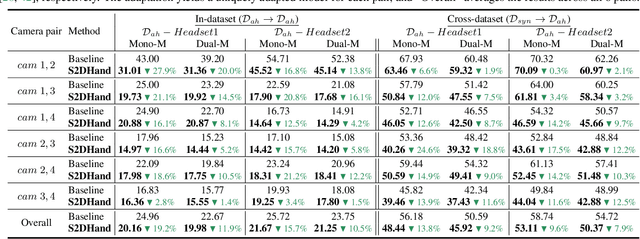
The pursuit of accurate 3D hand pose estimation stands as a keystone for understanding human activity in the realm of egocentric vision. The majority of existing estimation methods still rely on single-view images as input, leading to potential limitations, e.g., limited field-of-view and ambiguity in depth. To address these problems, adding another camera to better capture the shape of hands is a practical direction. However, existing multi-view hand pose estimation methods suffer from two main drawbacks: 1) Requiring multi-view annotations for training, which are expensive. 2) During testing, the model becomes inapplicable if camera parameters/layout are not the same as those used in training. In this paper, we propose a novel Single-to-Dual-view adaptation (S2DHand) solution that adapts a pre-trained single-view estimator to dual views. Compared with existing multi-view training methods, 1) our adaptation process is unsupervised, eliminating the need for multi-view annotation. 2) Moreover, our method can handle arbitrary dual-view pairs with unknown camera parameters, making the model applicable to diverse camera settings. Specifically, S2DHand is built on certain stereo constraints, including pair-wise cross-view consensus and invariance of transformation between both views. These two stereo constraints are used in a complementary manner to generate pseudo-labels, allowing reliable adaptation. Evaluation results reveal that S2DHand achieves significant improvements on arbitrary camera pairs under both in-dataset and cross-dataset settings, and outperforms existing adaptation methods with leading performance. Project page: https://github.com/MickeyLLG/S2DHand.
Exo2EgoDVC: Dense Video Captioning of Egocentric Procedural Activities Using Web Instructional Videos
Nov 29, 2023



We propose a novel benchmark for cross-view knowledge transfer of dense video captioning, adapting models from web instructional videos with exocentric views to an egocentric view. While dense video captioning (predicting time segments and their captions) is primarily studied with exocentric videos (e.g., YouCook2), benchmarks with egocentric videos are restricted due to data scarcity. To overcome the limited video availability, transferring knowledge from abundant exocentric web videos is demanded as a practical approach. However, learning the correspondence between exocentric and egocentric views is difficult due to their dynamic view changes. The web videos contain mixed views focusing on either human body actions or close-up hand-object interactions, while the egocentric view is constantly shifting as the camera wearer moves. This necessitates the in-depth study of cross-view transfer under complex view changes. In this work, we first create a real-life egocentric dataset (EgoYC2) whose captions are shared with YouCook2, enabling transfer learning between these datasets assuming their ground-truth is accessible. To bridge the view gaps, we propose a view-invariant learning method using adversarial training in both the pre-training and fine-tuning stages. While the pre-training is designed to learn invariant features against the mixed views in the web videos, the view-invariant fine-tuning further mitigates the view gaps between both datasets. We validate our proposed method by studying how effectively it overcomes the view change problem and efficiently transfers the knowledge to the egocentric domain. Our benchmark pushes the study of the cross-view transfer into a new task domain of dense video captioning and will envision methodologies to describe egocentric videos in natural language.
Generative Hierarchical Temporal Transformer for Hand Action Recognition and Motion Prediction
Nov 29, 2023



We present a novel framework that concurrently tackles hand action recognition and 3D future hand motion prediction. While previous works focus on either recognition or prediction, we propose a generative Transformer VAE architecture to jointly capture both aspects, facilitating realistic motion prediction by leveraging the short-term hand motion and long-term action consistency observed across timestamps.To ensure faithful representation of the semantic dependency and different temporal granularity of hand pose and action, our framework is decomposed into two cascaded VAE blocks. The lower pose block models short-span poses, while the upper action block models long-span action. These are connected by a mid-level feature that represents sub-second series of hand poses.Our framework is trained across multiple datasets, where pose and action blocks are trained separately to fully utilize pose-action annotations of different qualities. Evaluations show that on multiple datasets, the joint modeling of recognition and prediction improves over separate solutions, and the semantic and temporal hierarchy enables long-term pose and action modeling.
AssemblyHands: Towards Egocentric Activity Understanding via 3D Hand Pose Estimation
Apr 24, 2023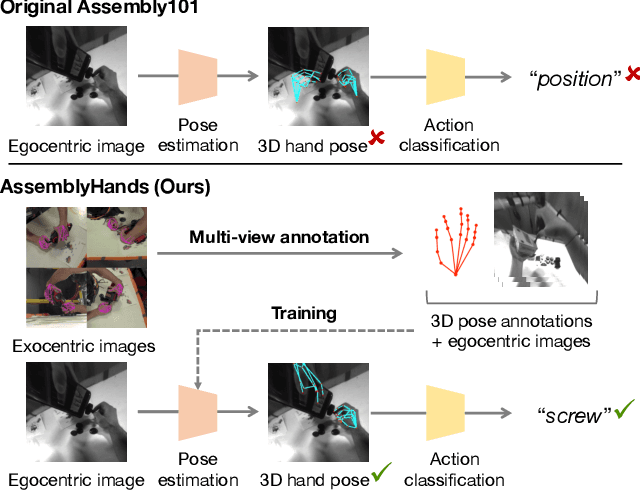
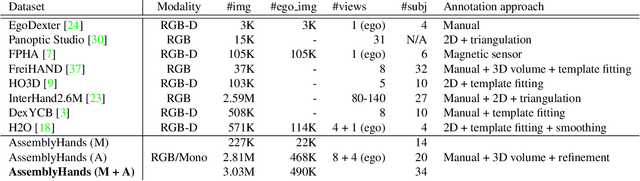
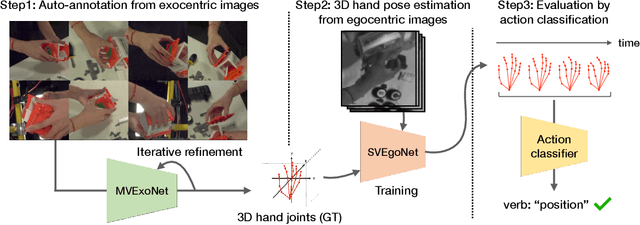
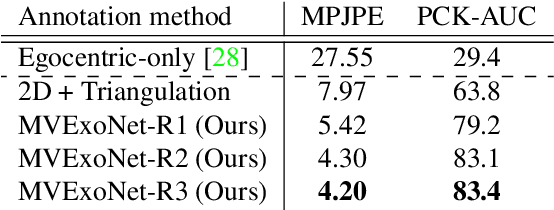
We present AssemblyHands, a large-scale benchmark dataset with accurate 3D hand pose annotations, to facilitate the study of egocentric activities with challenging hand-object interactions. The dataset includes synchronized egocentric and exocentric images sampled from the recent Assembly101 dataset, in which participants assemble and disassemble take-apart toys. To obtain high-quality 3D hand pose annotations for the egocentric images, we develop an efficient pipeline, where we use an initial set of manual annotations to train a model to automatically annotate a much larger dataset. Our annotation model uses multi-view feature fusion and an iterative refinement scheme, and achieves an average keypoint error of 4.20 mm, which is 85% lower than the error of the original annotations in Assembly101. AssemblyHands provides 3.0M annotated images, including 490K egocentric images, making it the largest existing benchmark dataset for egocentric 3D hand pose estimation. Using this data, we develop a strong single-view baseline of 3D hand pose estimation from egocentric images. Furthermore, we design a novel action classification task to evaluate predicted 3D hand poses. Our study shows that having higher-quality hand poses directly improves the ability to recognize actions.
Efficient Annotation and Learning for 3D Hand Pose Estimation: A Survey
Jun 07, 2022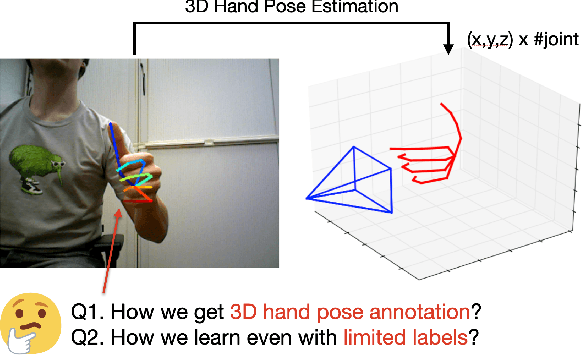
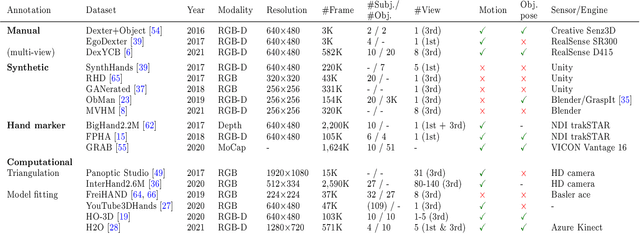
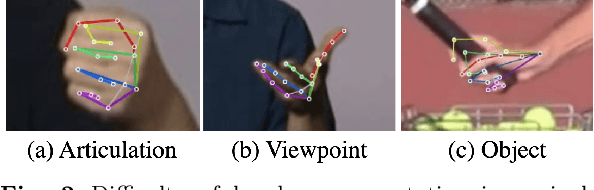
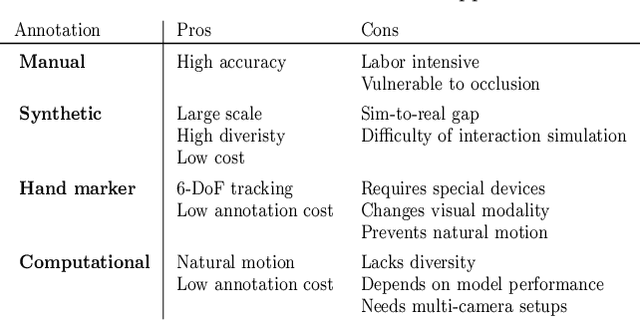
In this survey, we present comprehensive analysis of 3D hand pose estimation from the perspective of efficient annotation and learning. In particular, we study recent approaches for 3D hand pose annotation and learning methods with limited annotated data. In 3D hand pose estimation, collecting 3D hand pose annotation is a key step in developing hand pose estimators and their applications, such as video understanding, AR/VR, and robotics. However, acquiring annotated 3D hand poses is cumbersome, e.g., due to the difficulty of accessing 3D information and occlusion. Motivated by elucidating how recent works address the annotation issue, we investigated annotation methods classified as manual, synthetic-model-based, hand-sensor-based, and computational approaches. Since these annotation methods are not always available on a large scale, we examined methods of learning 3D hand poses when we do not have enough annotated data, namely self-supervised pre-training, semi-supervised learning, and domain adaptation. Based on the analysis of these efficient annotation and learning, we further discuss limitations and possible future directions of this field.