 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePALM: A Dataset and Baseline for Learning Multi-subject Hand Prior
Nov 07, 2025

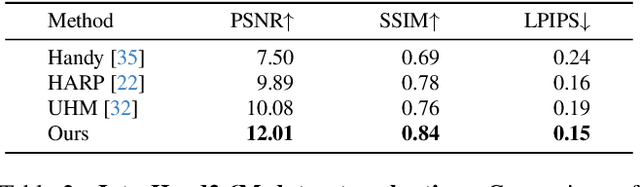
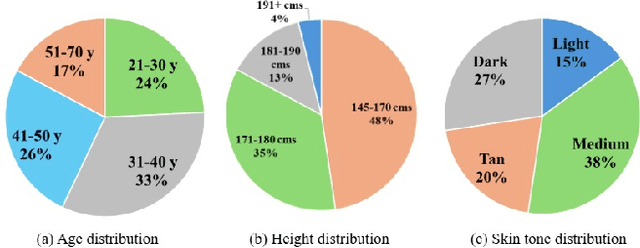
The ability to grasp objects, signal with gestures, and share emotion through touch all stem from the unique capabilities of human hands. Yet creating high-quality personalized hand avatars from images remains challenging due to complex geometry, appearance, and articulation, particularly under unconstrained lighting and limited views. Progress has also been limited by the lack of datasets that jointly provide accurate 3D geometry, high-resolution multiview imagery, and a diverse population of subjects. To address this, we present PALM, a large-scale dataset comprising 13k high-quality hand scans from 263 subjects and 90k multi-view images, capturing rich variation in skin tone, age, and geometry. To show its utility, we present a baseline PALM-Net, a multi-subject prior over hand geometry and material properties learned via physically based inverse rendering, enabling realistic, relightable single-image hand avatar personalization. PALM's scale and diversity make it a valuable real-world resource for hand modeling and related research.
MagicHOI: Leveraging 3D Priors for Accurate Hand-object Reconstruction from Short Monocular Video Clips
Aug 07, 2025



Most RGB-based hand-object reconstruction methods rely on object templates, while template-free methods typically assume full object visibility. This assumption often breaks in real-world settings, where fixed camera viewpoints and static grips leave parts of the object unobserved, resulting in implausible reconstructions. To overcome this, we present MagicHOI, a method for reconstructing hands and objects from short monocular interaction videos, even under limited viewpoint variation. Our key insight is that, despite the scarcity of paired 3D hand-object data, large-scale novel view synthesis diffusion models offer rich object supervision. This supervision serves as a prior to regularize unseen object regions during hand interactions. Leveraging this insight, we integrate a novel view synthesis model into our hand-object reconstruction framework. We further align hand to object by incorporating visible contact constraints. Our results demonstrate that MagicHOI significantly outperforms existing state-of-the-art hand-object reconstruction methods. We also show that novel view synthesis diffusion priors effectively regularize unseen object regions, enhancing 3D hand-object reconstruction.
GraspXL: Generating Grasping Motions for Diverse Objects at Scale
Mar 28, 2024

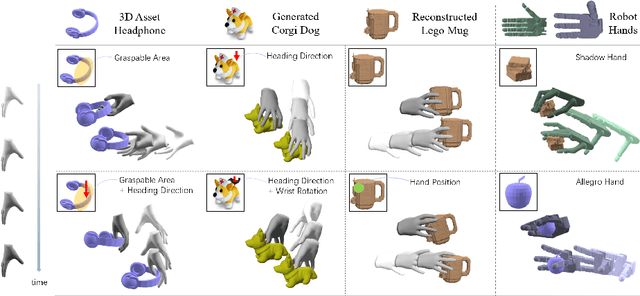
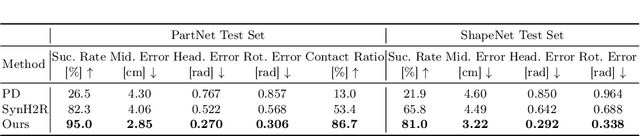
Human hands possess the dexterity to interact with diverse objects such as grasping specific parts of the objects and/or approaching them from desired directions. More importantly, humans can grasp objects of any shape without object-specific skills. Recent works synthesize grasping motions following single objectives such as a desired approach heading direction or a grasping area. Moreover, they usually rely on expensive 3D hand-object data during training and inference, which limits their capability to synthesize grasping motions for unseen objects at scale. In this paper, we unify the generation of hand-object grasping motions across multiple motion objectives, diverse object shapes and dexterous hand morphologies in a policy learning framework GraspXL. The objectives are composed of the graspable area, heading direction during approach, wrist rotation, and hand position. Without requiring any 3D hand-object interaction data, our policy trained with 58 objects can robustly synthesize diverse grasping motions for more than 500k unseen objects with a success rate of 82.2%. At the same time, the policy adheres to objectives, which enables the generation of diverse grasps per object. Moreover, we show that our framework can be deployed to different dexterous hands and work with reconstructed or generated objects. We quantitatively and qualitatively evaluate our method to show the efficacy of our approach. Our model and code will be available.
Benchmarks and Challenges in Pose Estimation for Egocentric Hand Interactions with Objects
Mar 25, 2024
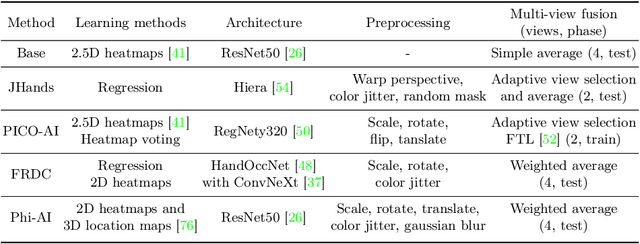
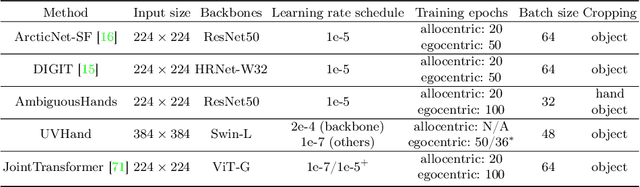
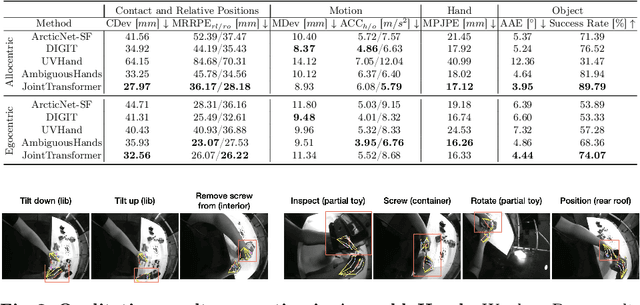
We interact with the world with our hands and see it through our own (egocentric) perspective. A holistic 3D understanding of such interactions from egocentric views is important for tasks in robotics, AR/VR, action recognition and motion generation. Accurately reconstructing such interactions in 3D is challenging due to heavy occlusion, viewpoint bias, camera distortion, and motion blur from the head movement. To this end, we designed the HANDS23 challenge based on the AssemblyHands and ARCTIC datasets with carefully designed training and testing splits. Based on the results of the top submitted methods and more recent baselines on the leaderboards, we perform a thorough analysis on 3D hand(-object) reconstruction tasks. Our analysis demonstrates the effectiveness of addressing distortion specific to egocentric cameras, adopting high-capacity transformers to learn complex hand-object interactions, and fusing predictions from different views. Our study further reveals challenging scenarios intractable with state-of-the-art methods, such as fast hand motion, object reconstruction from narrow egocentric views, and close contact between two hands and objects. Our efforts will enrich the community's knowledge foundation and facilitate future hand studies on egocentric hand-object interactions.
HMP: Hand Motion Priors for Pose and Shape Estimation from Video
Dec 27, 2023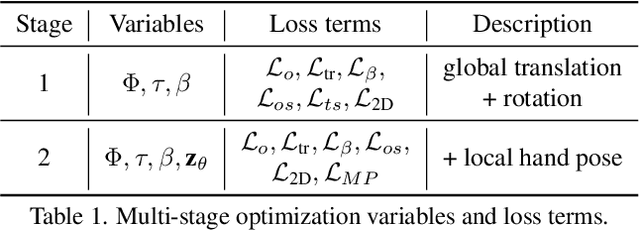
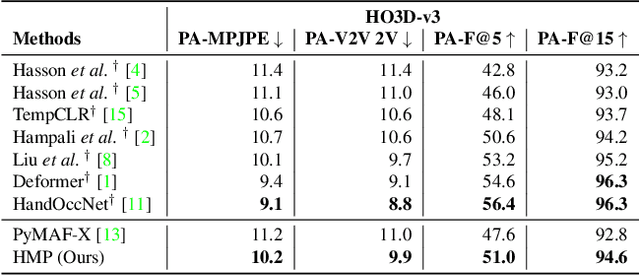


Understanding how humans interact with the world necessitates accurate 3D hand pose estimation, a task complicated by the hand's high degree of articulation, frequent occlusions, self-occlusions, and rapid motions. While most existing methods rely on single-image inputs, videos have useful cues to address aforementioned issues. However, existing video-based 3D hand datasets are insufficient for training feedforward models to generalize to in-the-wild scenarios. On the other hand, we have access to large human motion capture datasets which also include hand motions, e.g. AMASS. Therefore, we develop a generative motion prior specific for hands, trained on the AMASS dataset which features diverse and high-quality hand motions. This motion prior is then employed for video-based 3D hand motion estimation following a latent optimization approach. Our integration of a robust motion prior significantly enhances performance, especially in occluded scenarios. It produces stable, temporally consistent results that surpass conventional single-frame methods. We demonstrate our method's efficacy via qualitative and quantitative evaluations on the HO3D and DexYCB datasets, with special emphasis on an occlusion-focused subset of HO3D. Code is available at https://hmp.is.tue.mpg.de
HOLD: Category-agnostic 3D Reconstruction of Interacting Hands and Objects from Video
Nov 30, 2023

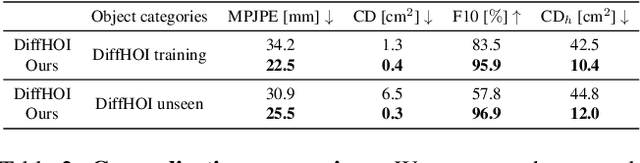
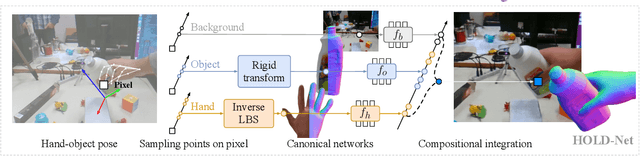
Since humans interact with diverse objects every day, the holistic 3D capture of these interactions is important to understand and model human behaviour. However, most existing methods for hand-object reconstruction from RGB either assume pre-scanned object templates or heavily rely on limited 3D hand-object data, restricting their ability to scale and generalize to more unconstrained interaction settings. To this end, we introduce HOLD -- the first category-agnostic method that reconstructs an articulated hand and object jointly from a monocular interaction video. We develop a compositional articulated implicit model that can reconstruct disentangled 3D hand and object from 2D images. We also further incorporate hand-object constraints to improve hand-object poses and consequently the reconstruction quality. Our method does not rely on 3D hand-object annotations while outperforming fully-supervised baselines in both in-the-lab and challenging in-the-wild settings. Moreover, we qualitatively show its robustness in reconstructing from in-the-wild videos. Code: https://github.com/zc-alexfan/hold
ArtiGrasp: Physically Plausible Synthesis of Bi-Manual Dexterous Grasping and Articulation
Sep 07, 2023



We present ArtiGrasp, a novel method to synthesize bi-manual hand-object interactions that include grasping and articulation. This task is challenging due to the diversity of the global wrist motions and the precise finger control that are necessary to articulate objects. ArtiGrasp leverages reinforcement learning and physics simulations to train a policy that controls the global and local hand pose. Our framework unifies grasping and articulation within a single policy guided by a single hand pose reference. Moreover, to facilitate the training of the precise finger control required for articulation, we present a learning curriculum with increasing difficulty. It starts with single-hand manipulation of stationary objects and continues with multi-agent training including both hands and non-stationary objects. To evaluate our method, we introduce Dynamic Object Grasping and Articulation, a task that involves bringing an object into a target articulated pose. This task requires grasping, relocation, and articulation. We show our method's efficacy towards this task. We further demonstrate that our method can generate motions with noisy hand-object pose estimates from an off-the-shelf image-based regressor.
Articulated Objects in Free-form Hand Interaction
Apr 28, 2022



We use our hands to interact with and to manipulate objects. Articulated objects are especially interesting since they often require the full dexterity of human hands to manipulate them. To understand, model, and synthesize such interactions, automatic and robust methods that reconstruct hands and articulated objects in 3D from a color image are needed. Existing methods for estimating 3D hand and object pose from images focus on rigid objects. In part, because such methods rely on training data and no dataset of articulated object manipulation exists. Consequently, we introduce ARCTIC - the first dataset of free-form interactions of hands and articulated objects. ARCTIC has 1.2M images paired with accurate 3D meshes for both hands and for objects that move and deform over time. The dataset also provides hand-object contact information. To show the value of our dataset, we perform two novel tasks on ARCTIC: (1) 3D reconstruction of two hands and an articulated object in interaction; (2) an estimation of dense hand-object relative distances, which we call interaction field estimation. For the first task, we present ArcticNet, a baseline method for the task of jointly reconstructing two hands and an articulated object from an RGB image. For interaction field estimation, we predict the relative distances from each hand vertex to the object surface, and vice versa. We introduce InterField, the first method that estimates such distances from a single RGB image. We provide qualitative and quantitative experiments for both tasks, and provide detailed analysis on the data. Code and data will be available at https://arctic.is.tue.mpg.de.
A Skeleton-Driven Neural Occupancy Representation for Articulated Hands
Sep 23, 2021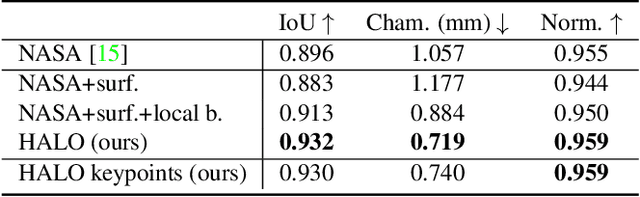
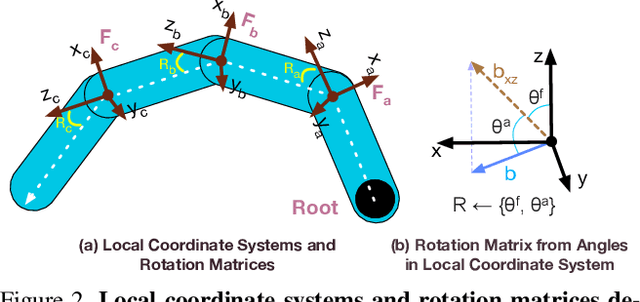

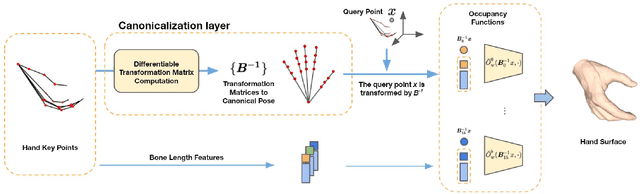
We present Hand ArticuLated Occupancy (HALO), a novel representation of articulated hands that bridges the advantages of 3D keypoints and neural implicit surfaces and can be used in end-to-end trainable architectures. Unlike existing statistical parametric hand models (e.g.~MANO), HALO directly leverages 3D joint skeleton as input and produces a neural occupancy volume representing the posed hand surface. The key benefits of HALO are (1) it is driven by 3D key points, which have benefits in terms of accuracy and are easier to learn for neural networks than the latent hand-model parameters; (2) it provides a differentiable volumetric occupancy representation of the posed hand; (3) it can be trained end-to-end, allowing the formulation of losses on the hand surface that benefit the learning of 3D keypoints. We demonstrate the applicability of HALO to the task of conditional generation of hands that grasp 3D objects. The differentiable nature of HALO is shown to improve the quality of the synthesized hands both in terms of physical plausibility and user preference.
Learning to Disambiguate Strongly Interacting Hands via Probabilistic Per-pixel Part Segmentation
Jul 01, 2021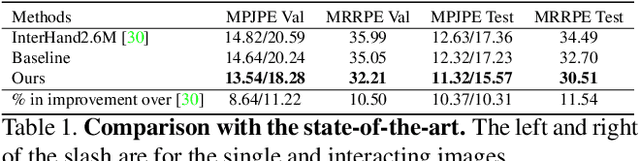
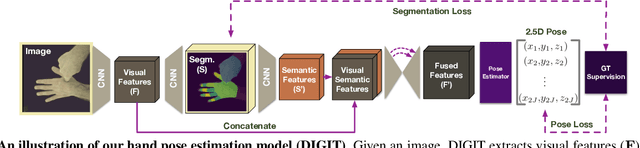

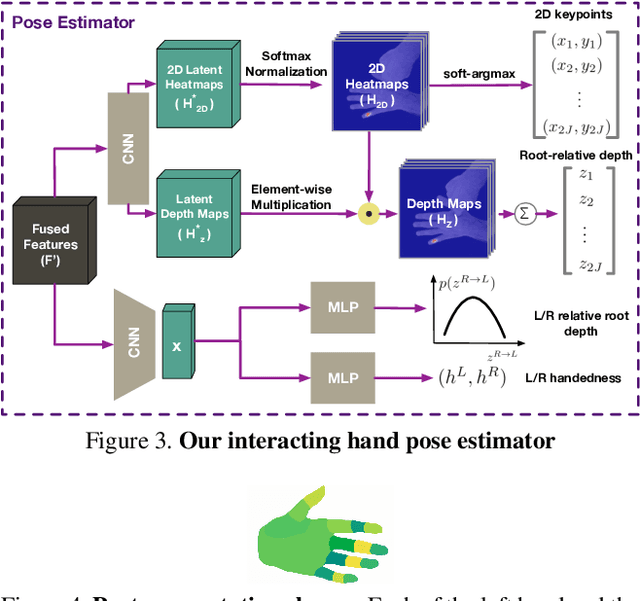
In natural conversation and interaction, our hands often overlap or are in contact with each other. Due to the homogeneous appearance of hands, this makes estimating the 3D pose of interacting hands from images difficult. In this paper we demonstrate that self-similarity, and the resulting ambiguities in assigning pixel observations to the respective hands and their parts, is a major cause of the final 3D pose error. Motivated by this insight, we propose DIGIT, a novel method for estimating the 3D poses of two interacting hands from a single monocular image. The method consists of two interwoven branches that process the input imagery into a per-pixel semantic part segmentation mask and a visual feature volume. In contrast to prior work, we do not decouple the segmentation from the pose estimation stage, but rather leverage the per-pixel probabilities directly in the downstream pose estimation task. To do so, the part probabilities are merged with the visual features and processed via fully-convolutional layers. We experimentally show that the proposed approach achieves new state-of-the-art performance on the InterHand2.6M dataset for both single and interacting hands across all metrics. We provide detailed ablation studies to demonstrate the efficacy of our method and to provide insights into how the modelling of pixel ownership affects single and interacting hand pose estimation. Our code will be released for research purposes.