 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Disambiguate Strongly Interacting Hands via Probabilistic Per-pixel Part Segmentation
Paper and Code
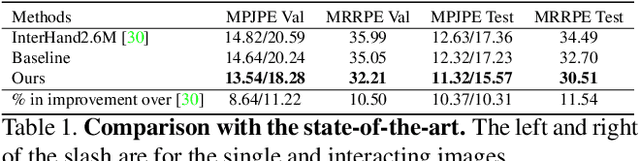
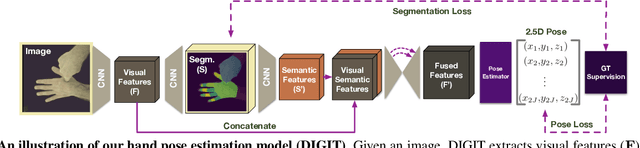

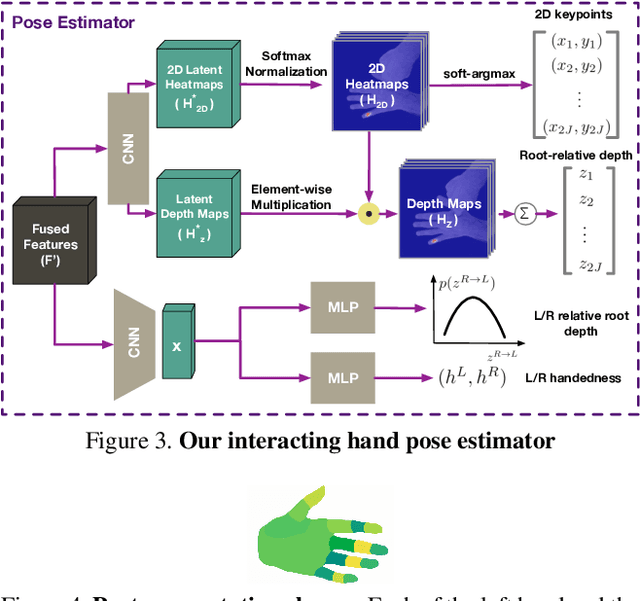
In natural conversation and interaction, our hands often overlap or are in contact with each other. Due to the homogeneous appearance of hands, this makes estimating the 3D pose of interacting hands from images difficult. In this paper we demonstrate that self-similarity, and the resulting ambiguities in assigning pixel observations to the respective hands and their parts, is a major cause of the final 3D pose error. Motivated by this insight, we propose DIGIT, a novel method for estimating the 3D poses of two interacting hands from a single monocular image. The method consists of two interwoven branches that process the input imagery into a per-pixel semantic part segmentation mask and a visual feature volume. In contrast to prior work, we do not decouple the segmentation from the pose estimation stage, but rather leverage the per-pixel probabilities directly in the downstream pose estimation task. To do so, the part probabilities are merged with the visual features and processed via fully-convolutional layers. We experimentally show that the proposed approach achieves new state-of-the-art performance on the InterHand2.6M dataset for both single and interacting hands across all metrics. We provide detailed ablation studies to demonstrate the efficacy of our method and to provide insights into how the modelling of pixel ownership affects single and interacting hand pose estimation. Our code will be released for research purposes.