 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeemg2pose: A Large and Diverse Benchmark for Surface Electromyographic Hand Pose Estimation
Dec 02, 2024



Hands are the primary means through which humans interact with the world. Reliable and always-available hand pose inference could yield new and intuitive control schemes for human-computer interactions, particularly in virtual and augmented reality. Computer vision is effective but requires one or multiple cameras and can struggle with occlusions, limited field of view, and poor lighting. Wearable wrist-based surface electromyography (sEMG) presents a promising alternative as an always-available modality sensing muscle activities that drive hand motion. However, sEMG signals are strongly dependent on user anatomy and sensor placement, and existing sEMG models have required hundreds of users and device placements to effectively generalize. To facilitate progress on sEMG pose inference, we introduce the emg2pose benchmark, the largest publicly available dataset of high-quality hand pose labels and wrist sEMG recordings. emg2pose contains 2kHz, 16 channel sEMG and pose labels from a 26-camera motion capture rig for 193 users, 370 hours, and 29 stages with diverse gestures - a scale comparable to vision-based hand pose datasets. We provide competitive baselines and challenging tasks evaluating real-world generalization scenarios: held-out users, sensor placements, and stages. emg2pose provides the machine learning community a platform for exploring complex generalization problems, holding potential to significantly enhance the development of sEMG-based human-computer interactions.
A Skeleton-Driven Neural Occupancy Representation for Articulated Hands
Sep 23, 2021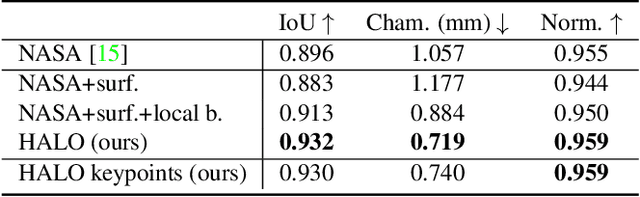
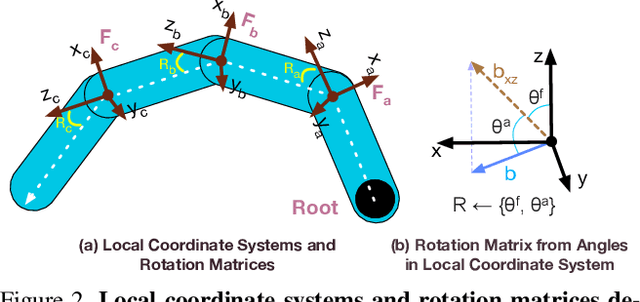

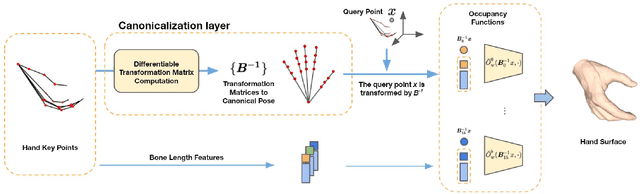
We present Hand ArticuLated Occupancy (HALO), a novel representation of articulated hands that bridges the advantages of 3D keypoints and neural implicit surfaces and can be used in end-to-end trainable architectures. Unlike existing statistical parametric hand models (e.g.~MANO), HALO directly leverages 3D joint skeleton as input and produces a neural occupancy volume representing the posed hand surface. The key benefits of HALO are (1) it is driven by 3D key points, which have benefits in terms of accuracy and are easier to learn for neural networks than the latent hand-model parameters; (2) it provides a differentiable volumetric occupancy representation of the posed hand; (3) it can be trained end-to-end, allowing the formulation of losses on the hand surface that benefit the learning of 3D keypoints. We demonstrate the applicability of HALO to the task of conditional generation of hands that grasp 3D objects. The differentiable nature of HALO is shown to improve the quality of the synthesized hands both in terms of physical plausibility and user preference.
Learning to Disambiguate Strongly Interacting Hands via Probabilistic Per-pixel Part Segmentation
Jul 01, 2021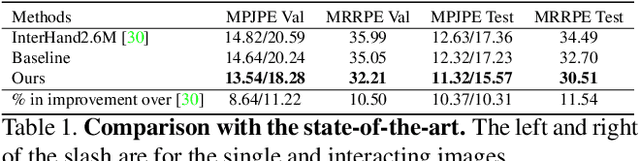
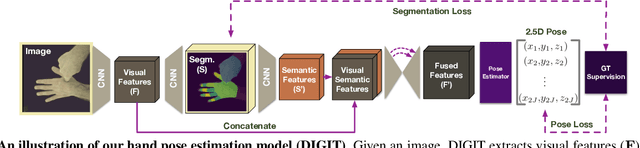

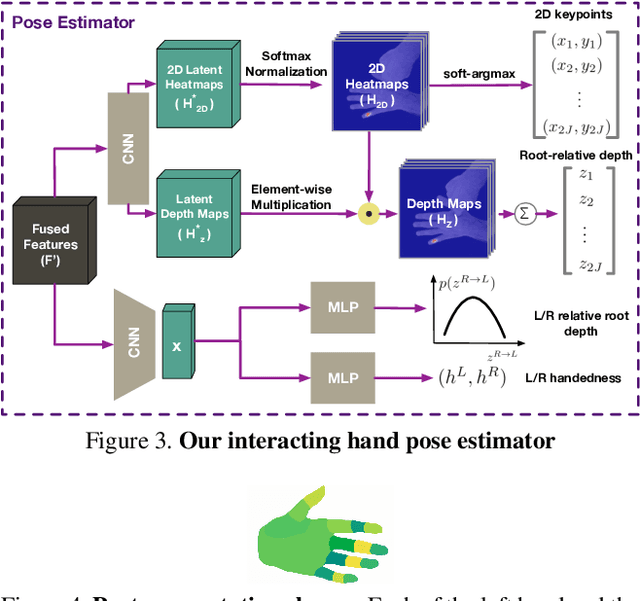
In natural conversation and interaction, our hands often overlap or are in contact with each other. Due to the homogeneous appearance of hands, this makes estimating the 3D pose of interacting hands from images difficult. In this paper we demonstrate that self-similarity, and the resulting ambiguities in assigning pixel observations to the respective hands and their parts, is a major cause of the final 3D pose error. Motivated by this insight, we propose DIGIT, a novel method for estimating the 3D poses of two interacting hands from a single monocular image. The method consists of two interwoven branches that process the input imagery into a per-pixel semantic part segmentation mask and a visual feature volume. In contrast to prior work, we do not decouple the segmentation from the pose estimation stage, but rather leverage the per-pixel probabilities directly in the downstream pose estimation task. To do so, the part probabilities are merged with the visual features and processed via fully-convolutional layers. We experimentally show that the proposed approach achieves new state-of-the-art performance on the InterHand2.6M dataset for both single and interacting hands across all metrics. We provide detailed ablation studies to demonstrate the efficacy of our method and to provide insights into how the modelling of pixel ownership affects single and interacting hand pose estimation. Our code will be released for research purposes.
Self-Supervised 3D Hand Pose Estimation from monocular RGB via Contrastive Learning
Jun 30, 2021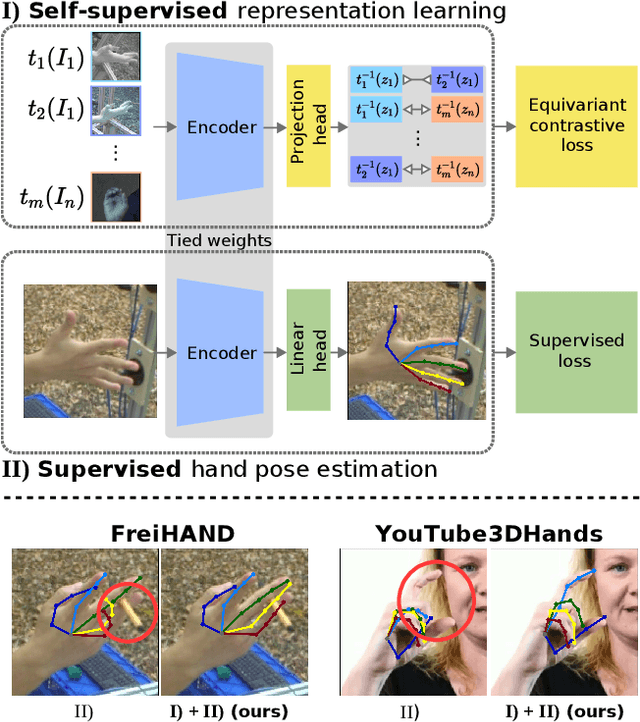
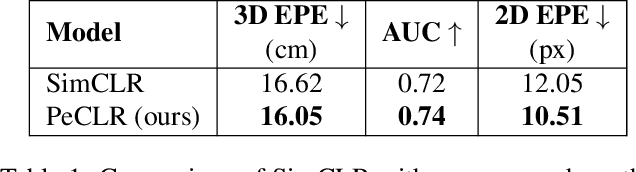
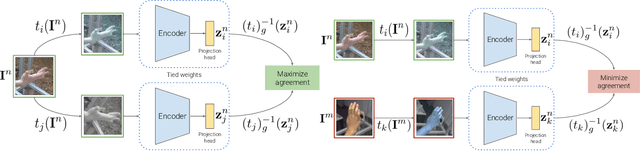
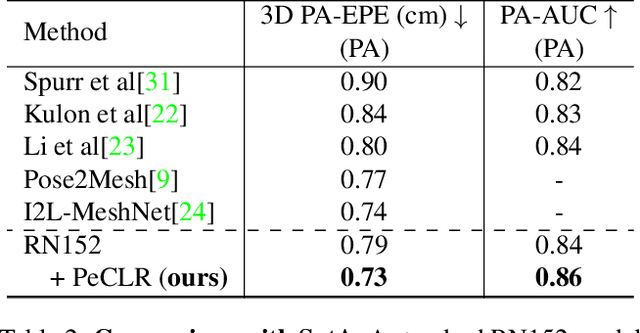
Acquiring accurate 3D annotated data for hand pose estimation is a notoriously difficult problem. This typically requires complex multi-camera setups and controlled conditions, which in turn creates a domain gap that is hard to bridge to fully unconstrained settings. Encouraged by the success of contrastive learning on image classification tasks, we propose a new self-supervised method for the structured regression task of 3D hand pose estimation. Contrastive learning makes use of unlabeled data for the purpose of representation learning via a loss formulation that encourages the learned feature representations to be invariant under any image transformation. For 3D hand pose estimation, it too is desirable to have invariance to appearance transformation such as color jitter. However, the task requires equivariance under affine transformations, such as rotation and translation. To address this issue, we propose an equivariant contrastive objective and demonstrate its effectiveness in the context of 3D hand pose estimation. We experimentally investigate the impact of invariant and equivariant contrastive objectives and show that learning equivariant features leads to better representations for the task of 3D hand pose estimation. Furthermore, we show that a standard ResNet-152, trained on additional unlabeled data, attains an improvement of $7.6\%$ in PA-EPE on FreiHAND and thus achieves state-of-the-art performance without any task specific, specialized architectures.
Adversarial Motion Modelling helps Semi-supervised Hand Pose Estimation
Jun 10, 2021
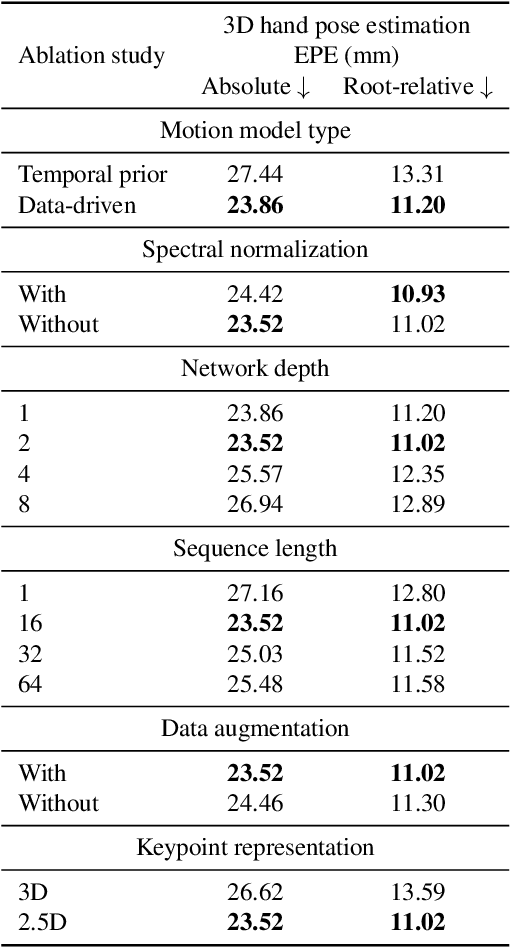
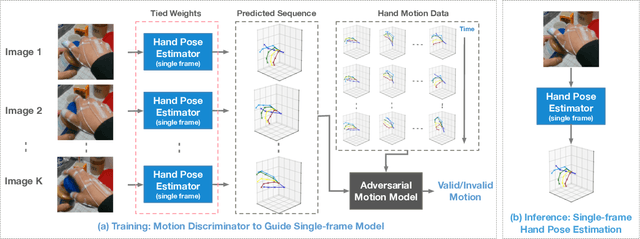

Hand pose estimation is difficult due to different environmental conditions, object- and self-occlusion as well as diversity in hand shape and appearance. Exhaustively covering this wide range of factors in fully annotated datasets has remained impractical, posing significant challenges for generalization of supervised methods. Embracing this challenge, we propose to combine ideas from adversarial training and motion modelling to tap into unlabeled videos. To this end we propose what to the best of our knowledge is the first motion model for hands and show that an adversarial formulation leads to better generalization properties of the hand pose estimator via semi-supervised training on unlabeled video sequences. In this setting, the pose predictor must produce a valid sequence of hand poses, as determined by a discriminative adversary. This adversary reasons both on the structural as well as temporal domain, effectively exploiting the spatio-temporal structure in the task. The main advantage of our approach is that we can make use of unpaired videos and joint sequence data both of which are much easier to attain than paired training data. We perform extensive evaluation, investigating essential components needed for the proposed framework and empirically demonstrate in two challenging settings that the proposed approach leads to significant improvements in pose estimation accuracy. In the lowest label setting, we attain an improvement of $40\%$ in absolute mean joint error.
Measuring Generalisation to Unseen Viewpoints, Articulations, Shapes and Objects for 3D Hand Pose Estimation under Hand-Object Interaction
Mar 30, 2020
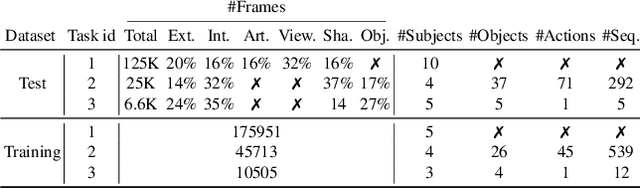
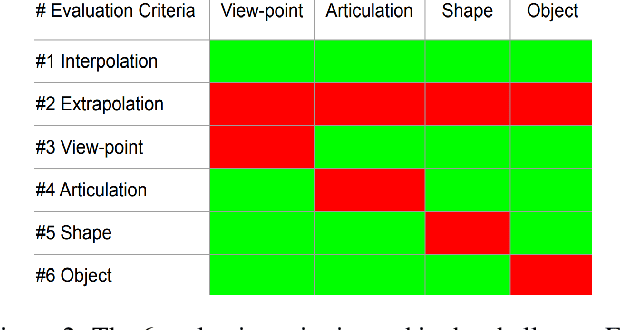
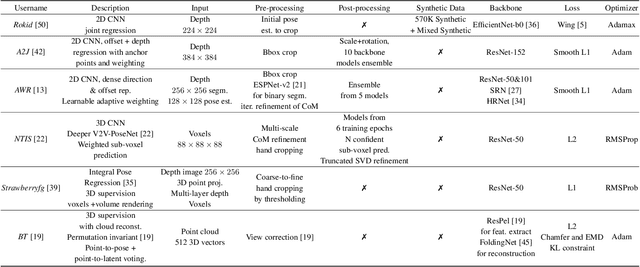
In this work, we study how well different type of approaches generalise in the task of 3D hand pose estimation under hand-object interaction and single hand scenarios. We show that the accuracy of state-of-the-art methods can drop, and that they fail mostly on poses absent from the training set. Unfortunately, since the space of hand poses is highly dimensional, it is inherently not feasible to cover the whole space densely, despite recent efforts in collecting large-scale training datasets. This sampling problem is even more severe when hands are interacting with objects and/or inputs are RGB rather than depth images, as RGB images also vary with lighting conditions and colors. To address these issues, we designed a public challenge to evaluate the abilities of current 3D hand pose estimators~(HPEs) to interpolate and extrapolate the poses of a training set. More exactly, our challenge is designed (a) to evaluate the influence of both depth and color modalities on 3D hand pose estimation, under the presence or absence of objects; (b) to assess the generalisation abilities \wrt~four main axes: shapes, articulations, viewpoints, and objects; (c) to explore the use of a synthetic hand model to fill the gaps of current datasets. Through the challenge, the overall accuracy has dramatically improved over the baseline, especially on extrapolation tasks, from 27mm to 13mm mean joint error. Our analyses highlight the impacts of: Data pre-processing, ensemble approaches, the use of MANO model, and different HPE methods/backbones.
Weakly Supervised 3D Hand Pose Estimation via Biomechanical Constraints
Mar 20, 2020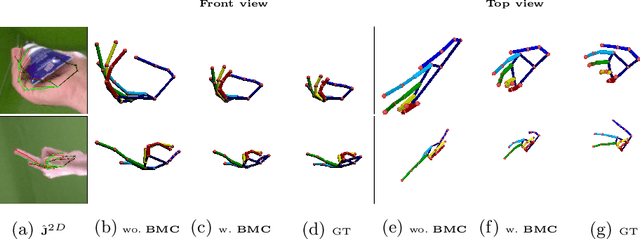



Estimating 3D hand pose from 2D images is a difficult, inverse problem due to the inherent scale and depth ambiguities. Current state-of-the-art methods train fully supervised deep neural networks with 3D ground-truth data. However, acquiring 3D annotations is expensive, typically requiring calibrated multi-view setups or labor intensive manual annotations. While annotations of 2D keypoints are much easier to obtain, how to efficiently leverage such weakly-supervised data to improve the task of 3D hand pose prediction remains an important open question. The key difficulty stems from the fact that direct application of additional 2D supervision mostly benefits the 2D proxy objective but does little to alleviate the depth and scale ambiguities. Embracing this challenge we propose a set of novel losses. We show by extensive experiments that our proposed constraints significantly reduce the depth ambiguity and allow the network to more effectively leverage additional 2D annotated images. For example, on the challenging freiHAND dataset using additional 2D annotation without our proposed biomechanical constraints reduces the depth error by only $15\%$, whereas the error is reduced significantly by $50\%$ when the proposed biomechanical constraints are used.
Photo-realistic Monocular Gaze Redirection using Generative Adversarial Networks
Mar 29, 2019
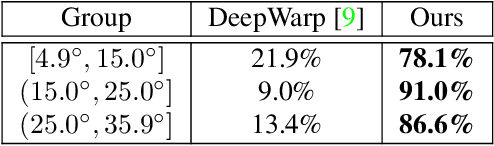
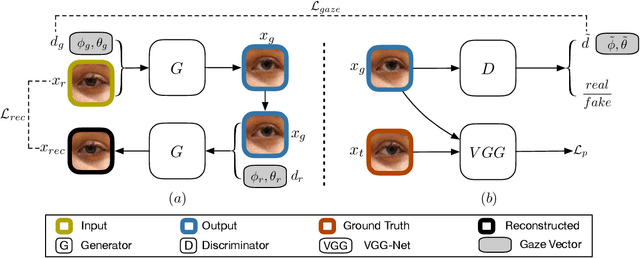
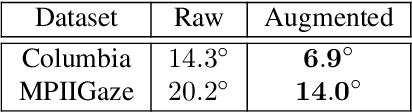
Gaze redirection is the task of changing the gaze to a desired direction for a given monocular eye patch image. Many applications such as videoconferencing, films and games, and generation of training data for gaze estimation require redirecting the gaze, without distorting the appearance of the area surrounding the eye and while producing photo-realistic images. Existing methods lack the ability to generate perceptually plausible images. In this work, we present a novel method to alleviate this problem by leveraging generative adversarial training to synthesize an eye image conditioned on a target gaze direction. Our method ensures perceptual similarity and consistency of synthesized images to the real images. Furthermore, a gaze estimation loss is used to control the gaze direction accurately. To attain high-quality images, we incorporate perceptual and cycle consistency losses into our architecture. In extensive evaluations we show that the proposed method outperforms state-of-the-art approaches in terms of both image quality and redirection precision. Finally, we show that generated images can bring significant improvement for the gaze estimation task if used to augment real training data.
Deep Pictorial Gaze Estimation
Jul 26, 2018
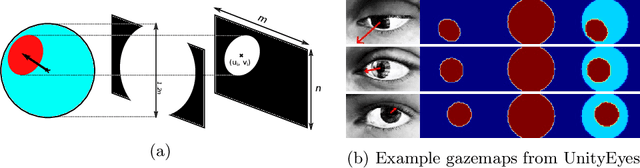
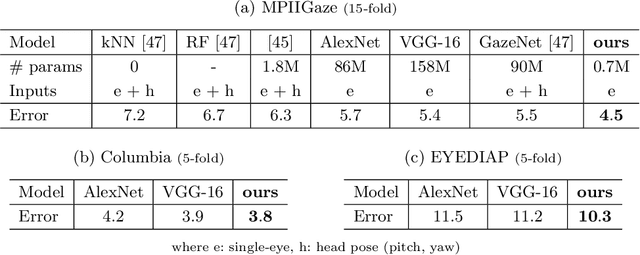
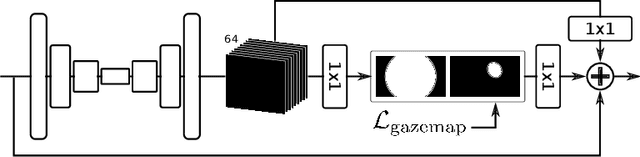
Estimating human gaze from natural eye images only is a challenging task. Gaze direction can be defined by the pupil- and the eyeball center where the latter is unobservable in 2D images. Hence, achieving highly accurate gaze estimates is an ill-posed problem. In this paper, we introduce a novel deep neural network architecture specifically designed for the task of gaze estimation from single eye input. Instead of directly regressing two angles for the pitch and yaw of the eyeball, we regress to an intermediate pictorial representation which in turn simplifies the task of 3D gaze direction estimation. Our quantitative and qualitative results show that our approach achieves higher accuracies than the state-of-the-art and is robust to variation in gaze, head pose and image quality.
Cross-modal Deep Variational Hand Pose Estimation
Mar 30, 2018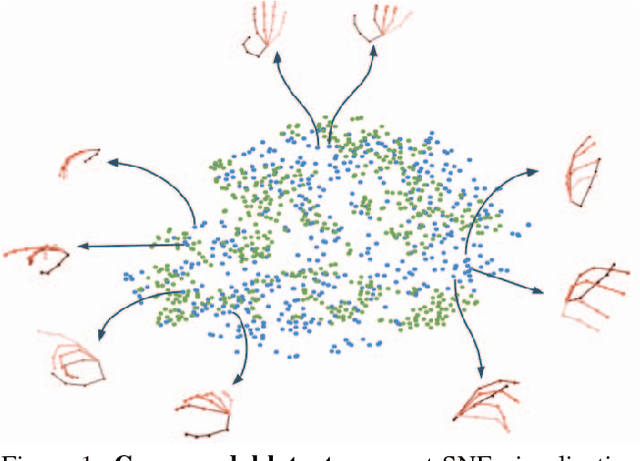
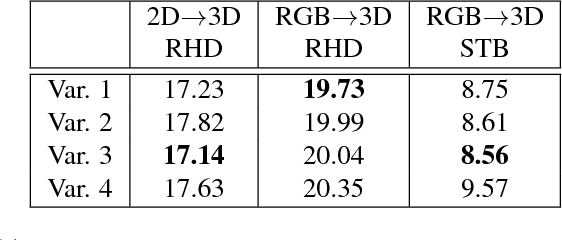
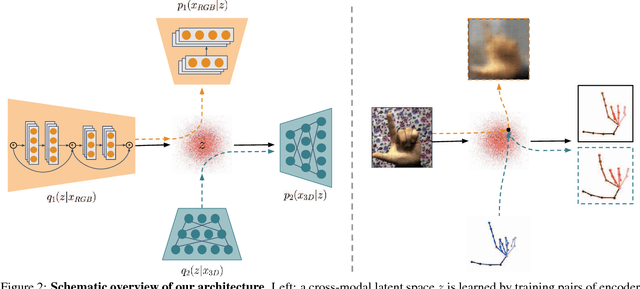

The human hand moves in complex and high-dimensional ways, making estimation of 3D hand pose configurations from images alone a challenging task. In this work we propose a method to learn a statistical hand model represented by a cross-modal trained latent space via a generative deep neural network. We derive an objective function from the variational lower bound of the VAE framework and jointly optimize the resulting cross-modal KL-divergence and the posterior reconstruction objective, naturally admitting a training regime that leads to a coherent latent space across multiple modalities such as RGB images, 2D keypoint detections or 3D hand configurations. Additionally, it grants a straightforward way of using semi-supervision. This latent space can be directly used to estimate 3D hand poses from RGB images, outperforming the state-of-the art in different settings. Furthermore, we show that our proposed method can be used without changes on depth images and performs comparably to specialized methods. Finally, the model is fully generative and can synthesize consistent pairs of hand configurations across modalities. We evaluate our method on both RGB and depth datasets and analyze the latent space qualitatively.