 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniPhys: Unified Planner and Controller with Diffusion for Flexible Physics-Based Character Control
Apr 17, 2025Generating natural and physically plausible character motion remains challenging, particularly for long-horizon control with diverse guidance signals. While prior work combines high-level diffusion-based motion planners with low-level physics controllers, these systems suffer from domain gaps that degrade motion quality and require task-specific fine-tuning. To tackle this problem, we introduce UniPhys, a diffusion-based behavior cloning framework that unifies motion planning and control into a single model. UniPhys enables flexible, expressive character motion conditioned on multi-modal inputs such as text, trajectories, and goals. To address accumulated prediction errors over long sequences, UniPhys is trained with the Diffusion Forcing paradigm, learning to denoise noisy motion histories and handle discrepancies introduced by the physics simulator. This design allows UniPhys to robustly generate physically plausible, long-horizon motions. Through guided sampling, UniPhys generalizes to a wide range of control signals, including unseen ones, without requiring task-specific fine-tuning. Experiments show that UniPhys outperforms prior methods in motion naturalness, generalization, and robustness across diverse control tasks.
ControlMM: Controllable Masked Motion Generation
Oct 14, 2024Recent advances in motion diffusion models have enabled spatially controllable text-to-motion generation. However, despite achieving acceptable control precision, these models suffer from generation speed and fidelity limitations. To address these challenges, we propose ControlMM, a novel approach incorporating spatial control signals into the generative masked motion model. ControlMM achieves real-time, high-fidelity, and high-precision controllable motion generation simultaneously. Our approach introduces two key innovations. First, we propose masked consistency modeling, which ensures high-fidelity motion generation via random masking and reconstruction, while minimizing the inconsistency between the input control signals and the extracted control signals from the generated motion. To further enhance control precision, we introduce inference-time logit editing, which manipulates the predicted conditional motion distribution so that the generated motion, sampled from the adjusted distribution, closely adheres to the input control signals. During inference, ControlMM enables parallel and iterative decoding of multiple motion tokens, allowing for high-speed motion generation. Extensive experiments show that, compared to the state of the art, ControlMM delivers superior results in motion quality, with better FID scores (0.061 vs 0.271), and higher control precision (average error 0.0091 vs 0.0108). ControlMM generates motions 20 times faster than diffusion-based methods. Additionally, ControlMM unlocks diverse applications such as any joint any frame control, body part timeline control, and obstacle avoidance. Video visualization can be found at https://exitudio.github.io/ControlMM-page
Optimizing Diffusion Noise Can Serve As Universal Motion Priors
Dec 19, 2023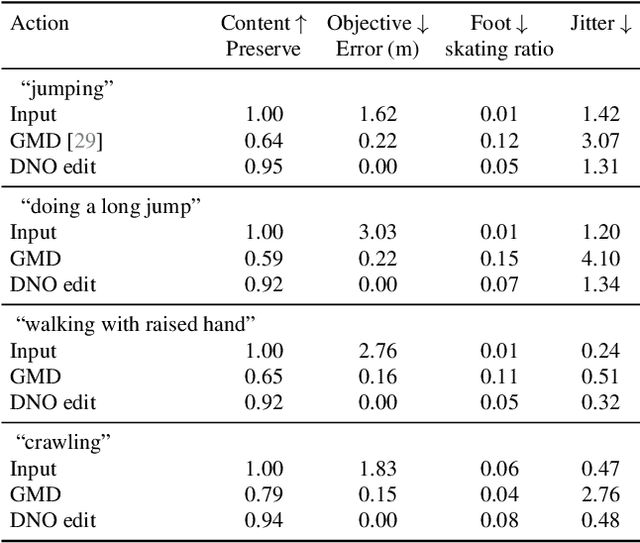
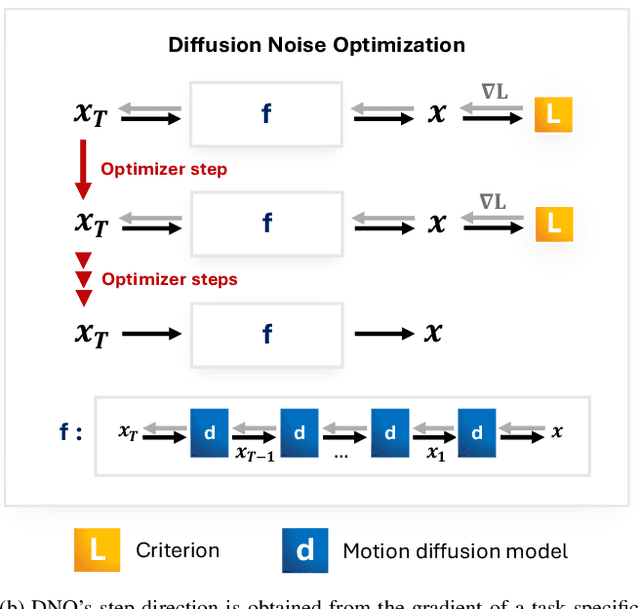
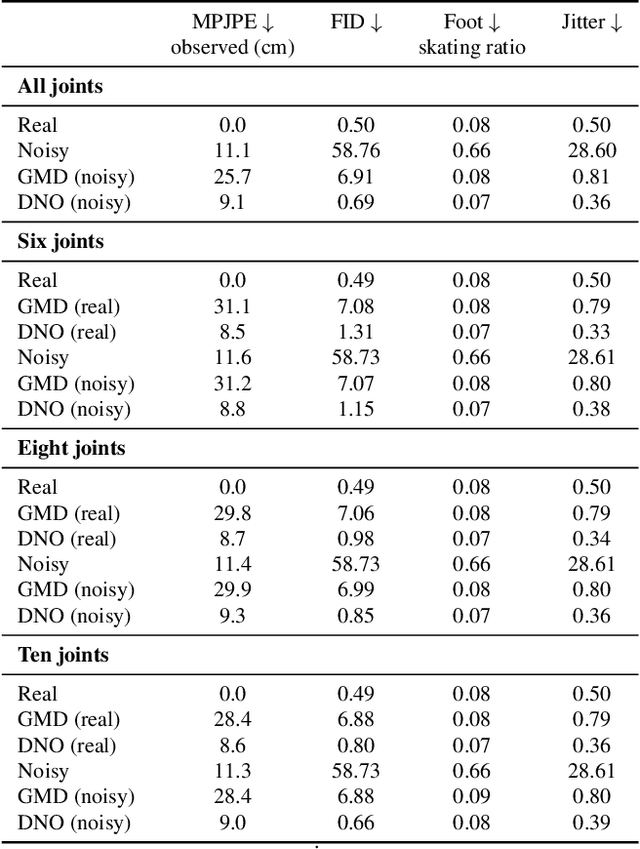

We propose Diffusion Noise Optimization (DNO), a new method that effectively leverages existing motion diffusion models as motion priors for a wide range of motion-related tasks. Instead of training a task-specific diffusion model for each new task, DNO operates by optimizing the diffusion latent noise of an existing pre-trained text-to-motion model. Given the corresponding latent noise of a human motion, it propagates the gradient from the target criteria defined on the motion space through the whole denoising process to update the diffusion latent noise. As a result, DNO supports any use cases where criteria can be defined as a function of motion. In particular, we show that, for motion editing and control, DNO outperforms existing methods in both achieving the objective and preserving the motion content. DNO accommodates a diverse range of editing modes, including changing trajectory, pose, joint locations, or avoiding newly added obstacles. In addition, DNO is effective in motion denoising and completion, producing smooth and realistic motion from noisy and partial inputs. DNO achieves these results at inference time without the need for model retraining, offering great versatility for any defined reward or loss function on the motion representation.
GMD: Controllable Human Motion Synthesis via Guided Diffusion Models
May 21, 2023



Denoising diffusion models have shown great promise in human motion synthesis conditioned on natural language descriptions. However, it remains a challenge to integrate spatial constraints, such as pre-defined motion trajectories and obstacles, which is essential for bridging the gap between isolated human motion and its surrounding environment. To address this issue, we propose Guided Motion Diffusion (GMD), a method that incorporates spatial constraints into the motion generation process. Specifically, we propose an effective feature projection scheme that largely enhances the coherency between spatial information and local poses. Together with a new imputation formulation, the generated motion can reliably conform to spatial constraints such as global motion trajectories. Furthermore, given sparse spatial constraints (e.g. sparse keyframes), we introduce a new dense guidance approach that utilizes the denoiser of diffusion models to turn a sparse signal into denser signals, effectively guiding the generation motion to the given constraints. The extensive experiments justify the development of GMD, which achieves a significant improvement over state-of-the-art methods in text-based motion generation while being able to control the synthesized motions with spatial constraints.
HARP: Personalized Hand Reconstruction from a Monocular RGB Video
Dec 30, 2022



We present HARP (HAnd Reconstruction and Personalization), a personalized hand avatar creation approach that takes a short monocular RGB video of a human hand as input and reconstructs a faithful hand avatar exhibiting a high-fidelity appearance and geometry. In contrast to the major trend of neural implicit representations, HARP models a hand with a mesh-based parametric hand model, a vertex displacement map, a normal map, and an albedo without any neural components. As validated by our experiments, the explicit nature of our representation enables a truly scalable, robust, and efficient approach to hand avatar creation. HARP is optimized via gradient descent from a short sequence captured by a hand-held mobile phone and can be directly used in AR/VR applications with real-time rendering capability. To enable this, we carefully design and implement a shadow-aware differentiable rendering scheme that is robust to high degree articulations and self-shadowing regularly present in hand motion sequences, as well as challenging lighting conditions. It also generalizes to unseen poses and novel viewpoints, producing photo-realistic renderings of hand animations performing highly-articulated motions. Furthermore, the learned HARP representation can be used for improving 3D hand pose estimation quality in challenging viewpoints. The key advantages of HARP are validated by the in-depth analyses on appearance reconstruction, novel-view and novel pose synthesis, and 3D hand pose refinement. It is an AR/VR-ready personalized hand representation that shows superior fidelity and scalability.
A Skeleton-Driven Neural Occupancy Representation for Articulated Hands
Sep 23, 2021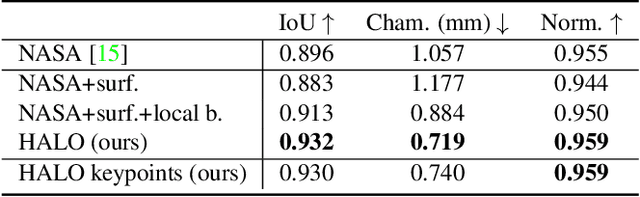
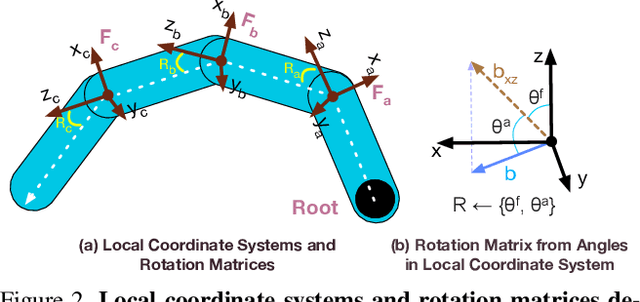

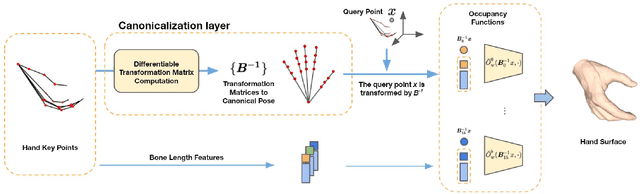
We present Hand ArticuLated Occupancy (HALO), a novel representation of articulated hands that bridges the advantages of 3D keypoints and neural implicit surfaces and can be used in end-to-end trainable architectures. Unlike existing statistical parametric hand models (e.g.~MANO), HALO directly leverages 3D joint skeleton as input and produces a neural occupancy volume representing the posed hand surface. The key benefits of HALO are (1) it is driven by 3D key points, which have benefits in terms of accuracy and are easier to learn for neural networks than the latent hand-model parameters; (2) it provides a differentiable volumetric occupancy representation of the posed hand; (3) it can be trained end-to-end, allowing the formulation of losses on the hand surface that benefit the learning of 3D keypoints. We demonstrate the applicability of HALO to the task of conditional generation of hands that grasp 3D objects. The differentiable nature of HALO is shown to improve the quality of the synthesized hands both in terms of physical plausibility and user preference.
Grasping Field: Learning Implicit Representations for Human Grasps
Aug 12, 2020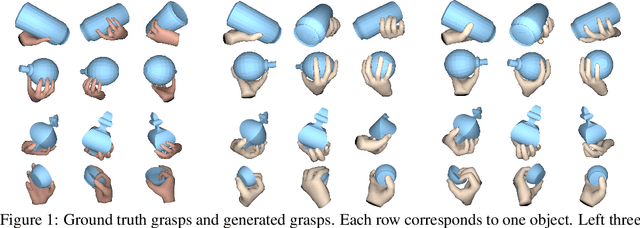
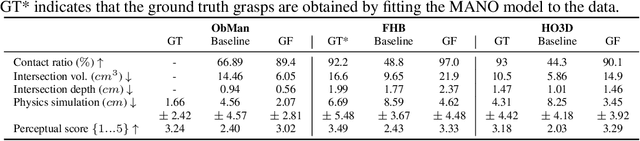
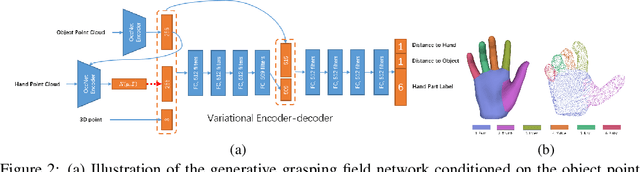
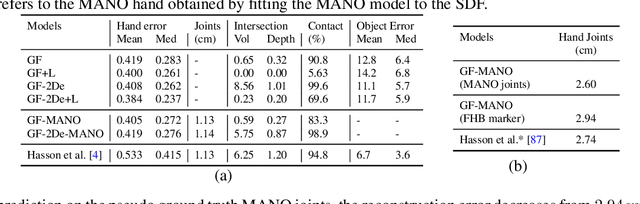
In recent years, substantial progress has been made on robotic grasping of household objects. Yet, human grasps are still difficult to synthesize realistically. There are several key reasons: (1) the human hand has many degrees of freedom (more than robotic manipulators); (2) the synthesized hand should conform naturally to the object surface; and (3) it must interact with the object in a semantically and physical plausible manner. To make progress in this direction, we draw inspiration from the recent progress on learning-based implicit representations for 3D object reconstruction. Specifically, we propose an expressive representation for human grasp modelling that is efficient and easy to integrate with deep neural networks. Our insight is that every point in a three-dimensional space can be characterized by the signed distances to the surface of the hand and the object, respectively. Consequently, the hand, the object, and the contact area can be represented by implicit surfaces in a common space, in which the proximity between the hand and the object can be modelled explicitly. We name this 3D to 2D mapping as Grasping Field, parameterize it with a deep neural network, and learn it from data. We demonstrate that the proposed grasping field is an effective and expressive representation for human grasp generation. Specifically, our generative model is able to synthesize high-quality human grasps, given only on a 3D object point cloud. The extensive experiments demonstrate that our generative model compares favorably with a strong baseline. Furthermore, based on the grasping field representation, we propose a deep network for the challenging task of 3D hand and object reconstruction from a single RGB image. Our method improves the physical plausibility of the 3D hand-object reconstruction task over baselines.
Reducing Spelling Inconsistencies in Code-Switching ASR using Contextualized CTC Loss
May 16, 2020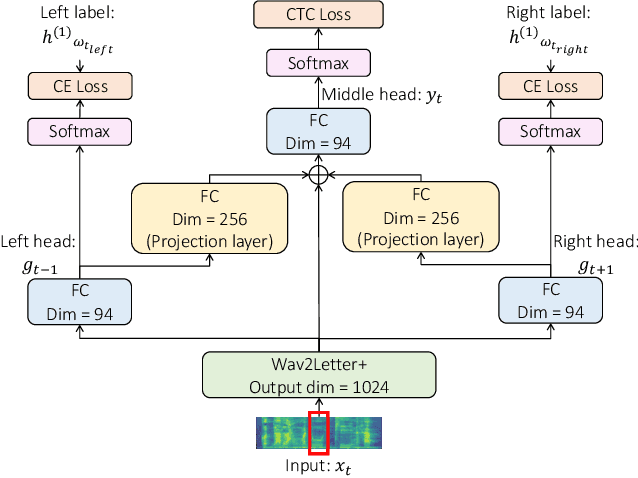
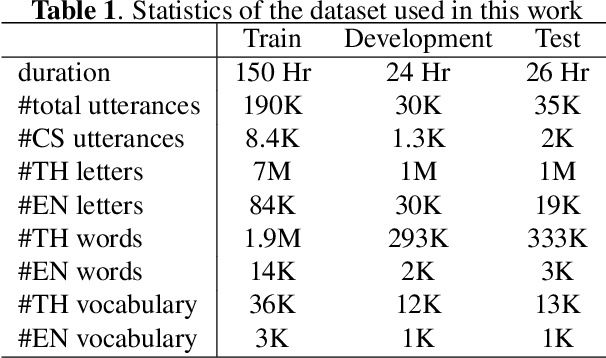
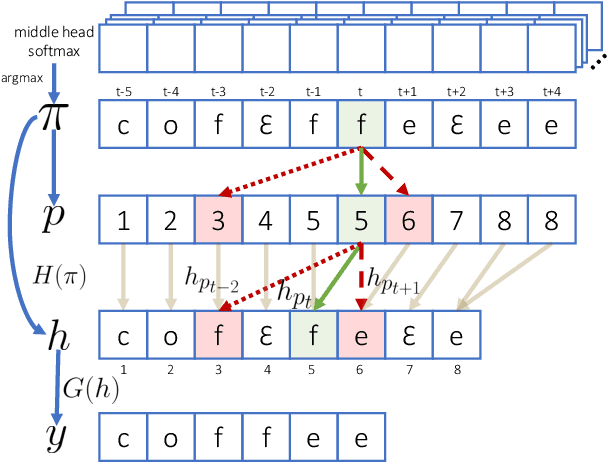
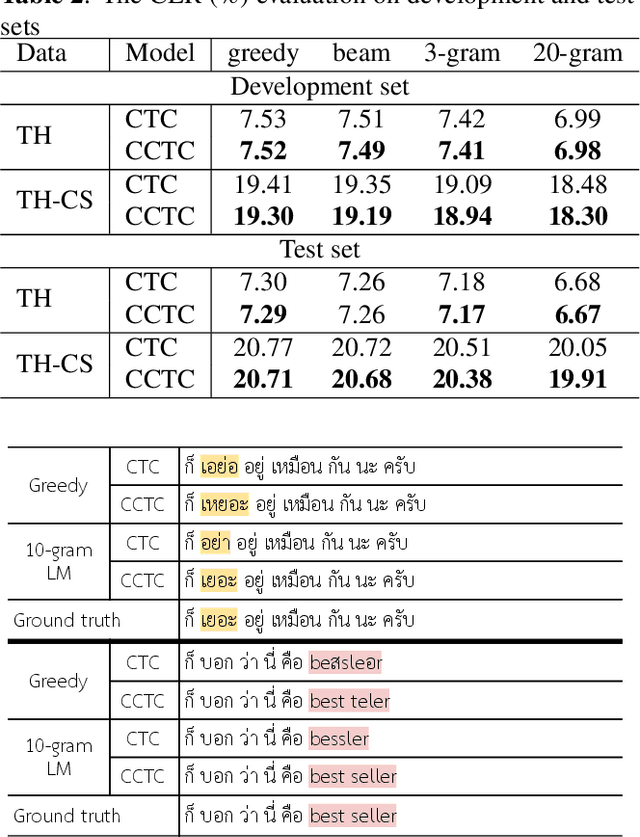
Code-Switching (CS) remains a challenge for Automatic Speech Recognition (ASR), especially character-based models. With the combined choice of characters from multiple languages, the outcome from character-based models suffers from phoneme duplication, resulting in language-inconsistent spellings. We propose Contextualized Connectionist Temporal Classification (CCTC) loss to encourage spelling consistencies of a character-based non-autoregressive ASR which allows for faster inference. The CCTC loss conditions the main prediction on the predicted contexts to ensure language consistency in the spellings. In contrast to existing CTC-based approaches, CCTC loss does not require frame-level alignments, since the context ground truth is obtained from the model's estimated path. Compared to the same model trained with regular CTC loss, our method consistently improved the ASR performance on both CS and monolingual corpora.