 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Perspectival Biases in Cross-Modal Retrieval
Nov 03, 2025Multimodal retrieval systems are expected to operate in a semantic space, agnostic to the language or cultural origin of the query. In practice, however, retrieval outcomes systematically reflect perspectival biases: deviations shaped by linguistic prevalence and cultural associations. We study two such biases. First, prevalence bias refers to the tendency to favor entries from prevalent languages over semantically faithful entries in image-to-text retrieval. Second, association bias refers to the tendency to favor images culturally associated with the query over semantically correct ones in text-to-image retrieval. Results show that explicit alignment is a more effective strategy for mitigating prevalence bias. However, association bias remains a distinct and more challenging problem. These findings suggest that achieving truly equitable multimodal systems requires targeted strategies beyond simple data scaling and that bias arising from cultural association may be treated as a more challenging problem than one arising from linguistic prevalence.
SEA-BED: Southeast Asia Embedding Benchmark
Aug 17, 2025
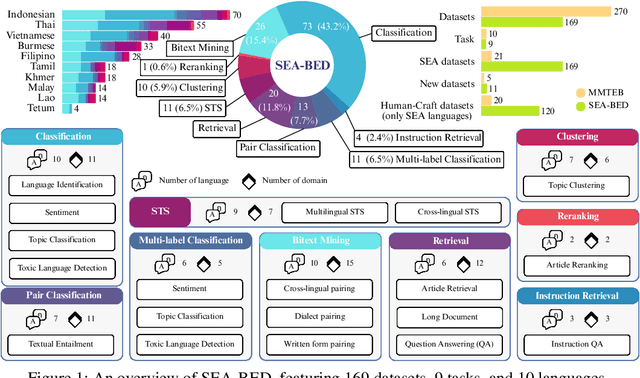


Sentence embeddings are essential for NLP tasks such as semantic search, re-ranking, and textual similarity. Although multilingual benchmarks like MMTEB broaden coverage, Southeast Asia (SEA) datasets are scarce and often machine-translated, missing native linguistic properties. With nearly 700 million speakers, the SEA region lacks a region-specific embedding benchmark. We introduce SEA-BED, the first large-scale SEA embedding benchmark with 169 datasets across 9 tasks and 10 languages, where 71% are formulated by humans, not machine generation or translation. We address three research questions: (1) which SEA languages and tasks are challenging, (2) whether SEA languages show unique performance gaps globally, and (3) how human vs. machine translations affect evaluation. We evaluate 17 embedding models across six studies, analyzing task and language challenges, cross-benchmark comparisons, and translation trade-offs. Results show sharp ranking shifts, inconsistent model performance among SEA languages, and the importance of human-curated datasets for low-resource languages like Burmese.
SEADialogues: A Multilingual Culturally Grounded Multi-turn Dialogue Dataset on Southeast Asian Languages
Aug 09, 2025Although numerous datasets have been developed to support dialogue systems, most existing chit-chat datasets overlook the cultural nuances inherent in natural human conversations. To address this gap, we introduce SEADialogues, a culturally grounded dialogue dataset centered on Southeast Asia, a region with over 700 million people and immense cultural diversity. Our dataset features dialogues in eight languages from six Southeast Asian countries, many of which are low-resource despite having sizable speaker populations. To enhance cultural relevance and personalization, each dialogue includes persona attributes and two culturally grounded topics that reflect everyday life in the respective communities. Furthermore, we release a multi-turn dialogue dataset to advance research on culturally aware and human-centric large language models, including conversational dialogue agents.
Amplifying Artifacts with Speech Enhancement in Voice Anti-spoofing
Jun 13, 2025



Spoofed utterances always contain artifacts introduced by generative models. While several countermeasures have been proposed to detect spoofed utterances, most primarily focus on architectural improvements. In this work, we investigate how artifacts remain hidden in spoofed speech and how to enhance their presence. We propose a model-agnostic pipeline that amplifies artifacts using speech enhancement and various types of noise. Our approach consists of three key steps: noise addition, noise extraction, and noise amplification. First, we introduce noise into the raw speech. Then, we apply speech enhancement to extract the entangled noise and artifacts. Finally, we amplify these extracted features. Moreover, our pipeline is compatible with different speech enhancement models and countermeasure architectures. Our method improves spoof detection performance by up to 44.44\% on ASVspoof2019 and 26.34\% on ASVspoof2021.
Explainable Depression Detection using Masked Hard Instance Mining
May 30, 2025This paper addresses the critical need for improved explainability in text-based depression detection. While offering predictive outcomes, current solutions often overlook the understanding of model predictions which can hinder trust in the system. We propose the use of Masked Hard Instance Mining (MHIM) to enhance the explainability in the depression detection task. MHIM strategically masks attention weights within the model, compelling it to distribute attention across a wider range of salient features. We evaluate MHIM on two datasets representing distinct languages: Thai (Thai-Maywe) and English (DAIC-WOZ). Our results demonstrate that MHIM significantly improves performance in terms of both prediction accuracy and explainability metrics.
Decom-Renorm-Merge: Model Merging on the Right Space Improves Multitasking
May 29, 2025In the era of large-scale training, model merging has evolved into a tool for creating multitasking models efficiently. It enables the knowledge of models to be fused, without the need for heavy computation as required in traditional multitask learning. Existing merging methods often assume that entries at identical positions in weight matrices serve the same function, enabling straightforward entry-wise comparison and merging. However, this assumption overlooks the complexity of finetuned neural networks, where neurons may develop distinct feature compositions, making direct entry-wise merging problematic. We present Decom-Renorm-Merge (DRM), a simple yet effective approach that leverages Singular Value Decomposition to decompose and coordinate weight matrices into an aligned joint space, where entry-wise merging becomes possible. We showcase the effectiveness of DRM across various settings ranging from smaller encoder-based such as ViT and DeBERTa, encoder-decoder-based such as T5, and larger decoder-based such as Llama3.1-8B. Our experimental results show that DRM outperforms several state-of-the-art merging techniques across full finetuning and low-rank adaptation settings. Moreover, our analysis reveals renormalization as the crucial component for creating a robust and even joint space for merging, significantly contributing to the method's performance.
Towards Better Understanding of Program-of-Thought Reasoning in Cross-Lingual and Multilingual Environments
Feb 25, 2025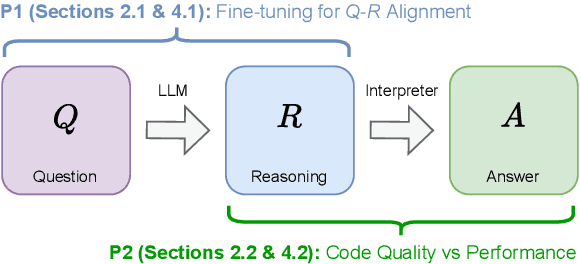

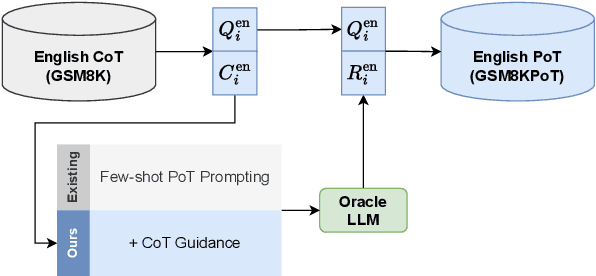

Multi-step reasoning is essential for large language models (LLMs), yet multilingual performance remains challenging. While Chain-of-Thought (CoT) prompting improves reasoning, it struggles with non-English languages due to the entanglement of reasoning and execution. Program-of-Thought (PoT) prompting separates reasoning from execution, offering a promising alternative but shifting the challenge to generating programs from non-English questions. We propose a framework to evaluate PoT by separating multilingual reasoning from code execution to examine (i) the impact of fine-tuning on question-reasoning alignment and (ii) how reasoning quality affects answer correctness. Our findings demonstrate that PoT fine-tuning substantially enhances multilingual reasoning, outperforming CoT fine-tuned models. We further demonstrate a strong correlation between reasoning quality (measured through code quality) and answer accuracy, highlighting its potential as a test-time performance improvement heuristic.
Mitigating Language Bias in Cross-Lingual Job Retrieval: A Recruitment Platform Perspective
Feb 05, 2025Understanding the textual components of resumes and job postings is critical for improving job-matching accuracy and optimizing job search systems in online recruitment platforms. However, existing works primarily focus on analyzing individual components within this information, requiring multiple specialized tools to analyze each aspect. Such disjointed methods could potentially hinder overall generalizability in recruitment-related text processing. Therefore, we propose a unified sentence encoder that utilized multi-task dual-encoder framework for jointly learning multiple component into the unified sentence encoder. The results show that our method outperforms other state-of-the-art models, despite its smaller model size. Moreover, we propose a novel metric, Language Bias Kullback-Leibler Divergence (LBKL), to evaluate language bias in the encoder, demonstrating significant bias reduction and superior cross-lingual performance.
Learning Job Title Representation from Job Description Aggregation Network
Jun 12, 2024



Learning job title representation is a vital process for developing automatic human resource tools. To do so, existing methods primarily rely on learning the title representation through skills extracted from the job description, neglecting the rich and diverse content within. Thus, we propose an alternative framework for learning job titles through their respective job description (JD) and utilize a Job Description Aggregator component to handle the lengthy description and bidirectional contrastive loss to account for the bidirectional relationship between the job title and its description. We evaluated the performance of our method on both in-domain and out-of-domain settings, achieving a superior performance over the skill-based approach.
Thunder : Unified Regression-Diffusion Speech Enhancement with a Single Reverse Step using Brownian Bridge
Jun 10, 2024


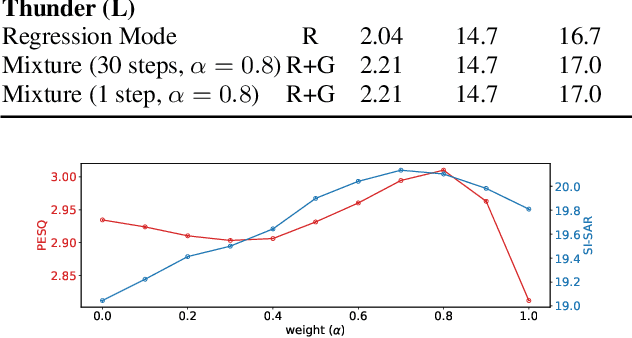
Diffusion-based speech enhancement has shown promising results, but can suffer from a slower inference time. Initializing the diffusion process with the enhanced audio generated by a regression-based model can be used to reduce the computational steps required. However, these approaches often necessitate a regression model, further increasing the system's complexity. We propose Thunder, a unified regression-diffusion model that utilizes the Brownian bridge process which can allow the model to act in both modes. The regression mode can be accessed by setting the diffusion time step closed to 1. However, the standard score-based diffusion modeling does not perform well in this setup due to gradient instability. To mitigate this problem, we modify the diffusion model to predict the clean speech instead of the score function, achieving competitive performance with a more compact model size and fewer reverse steps.