 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Extrinsic and Intrinsic Properties for Effective Reasoning with Code Interpreter
Jun 15, 2026Reasoning with a Code Interpreter (CI) has emerged as an effective paradigm for enhancing the reasoning capabilities of large language models (LLMs) through executable computation and iterative verification. Despite its growing adoption, the behavioral properties underlying effective code reasoning remain largely underexplored. In this work, we investigate code reasoning from two distinct perspectives inspired by prior studies of natural language reasoning: extrinsic properties, represented by crucial tokens, and intrinsic properties, represented by code-specific cognitive behaviors. Across multiple LLMs, we find that stronger CI reasoning models consistently exhibit a higher prevalence of crucial tokens and cognitive behaviors, particularly verification, backtracking, and backward chaining. Building on these observations, we examine how these properties can be leveraged during both inference and training. At inference time, appending code-specific crucial tokens improves performance on several reasoning capabilities, including mathematical, ordering, and optimization, while yielding limited benefits elsewhere. At training time, augmenting a state-of-the-art framework with code-specific cognitive behaviors improves supervised fine-tuning and reinforcement learning performance in two of three evaluated models. Further analysis shows that these behaviors reduce overthinking in incorrect responses and improve token efficiency, while also revealing factors that limit gains in a certain model. Our findings provide the first systematic characterization of effective reasoning with CI and demonstrate both the potential and limitations of leveraging key properties to improve CI-based reasoning.
DuDi: Dual-Signal Distillation with Cross-Lingual Verbalizer
Jun 03, 2026Small language models (SLMs) are efficient and scalable, but their multilingual capabilities degrade severely at sub-billion scales, especially for Southeast Asian (SEA) languages. We introduce DuDi, a dual-signal multilingual distillation framework that combines an online sequence-level signal with off-policy and on-policy token-level signals. DuDi further uses a cross-lingual verbalizer to refine teacher feedback and improve teacher-student transferability in multilingual settings. Experiments on SEA-HELM across multiple model families, scales, and teacher-student settings show that DuDi consistently outperforms competitive distillation baselines. Ablations and analyses confirm that sequence-level optimization, token-level supervision, and cross-lingual verbalization provide complementary and transferable learning signals for multilingual SLMs.
SEA-Embedding: Open and Reproducible Text Embeddings for Southeast Asia
Jun 02, 2026Text embeddings are fundamental to many downstream applications, making robustness important for real-world NLP. However, most recent state-of-the-art embedding models are not reproducible because they rely on closed or undisclosed training data, and they remain insufficiently robust for Southeast Asian languages. We present SEA-Embedding, a fully open and reproducible text-embedding pipeline for Southeast Asian languages trained only on publicly available data, and use it to study three core factors of robust embedding design: data composition, training objective, and base encoder initialization. SEA-Embedding achieves state-of-the-art results on SEA-BED while enabling systematic and reproducible analysis of robust text embeddings for the region.
SEA-NLI: Natural Language Inference as a Lens into Southeast Asian Cultural Understanding
Jun 02, 2026Frontier LLMs perform well in Western contexts, but remain poorly tested on underrepresented cultures such as those in Southeast Asia (SEA). Existing NLI benchmarks are largely Western-centric, translation-derived, or monolingual, limiting their ability to measure culturally grounded reasoning. We introduce SEA-NLI, a native, culturally grounded NLI benchmark covering eight SEA countries in English and native regional languages, verified by native speakers. Across 17 encoder and decoder models, we observe a low performance from all models, especially for knowledge-intensive categories such as Languages and Science and Technology. Our analysis shows that failure cases mainly stem from missing SEA cultural knowledge: SEA-adapted models and culture-aware prompting improve performance, while CoT prompting offers limited gains.
A Two-Phase Stability Study of LLM Judges and Bar Council Examiners on Thai Bar-Exam Free-Form Essays
May 25, 2026Free-form legal essay evaluation in NLP treats expert inter-rater stability as a single ceiling number, and treats LLM-judge agreement with that ceiling as evidence of judge stability. We test both assumptions on the Thai bar examination through an identical-inputs protocol: three Bar Council-trained examiners (A, B, C) and a 26-LLM judge panel score the same 15 cross-graded answers from the same four inputs (question, official Bar Council grading regulation, gold answer, candidate answer). The headline finding is asymmetric. On 10 of 15 cells where the rubric prescribes both axes, all 29 raters converge in a tight band: panel agreement is universal. On the remaining 5 cells where the rubric does not prescribe how to grade a correct final answer that omits a decisive statutory citation, the human panel splits between two coherent readings (B/C majority at the upper rubric band, score $6$--$8$; A minority at the lower band, score $1$--$2$). The LLM judge population does not split symmetrically: 22 of 26 LLMs score in or near B/C's contested band, 3 sit in the regulation-silent middle gap, and only 1 (GPT-5.4 Nano) approaches A's band without consistently scoring within it. \emph{Zero LLMs in our 26-judge panel reproduce the minority human reading on the contested cells.} The B/C-direction cluster spans every model size, vendor, and price tier we tested. An instrumented three-LLM anchor sub-panel (Claude 4.6 Opus, Gemini 3.1 Pro, GPT-5.4 Pro) carries determinism probes, input ablations, and bootstrap CIs, and reaches anchor panel $α= 0.77$ on the 15 cells against human-panel $α= 0.36$. The high LLM-panel $α$ reflects systematic convergence on the majority reading rather than balanced reproduction of both readings; a benchmark that selects its LLM judge by maximising agreement with a human reference panel will inherit this asymmetry by construction.
MultiLexNorm++: A Unified Benchmark and a Generative Model for Lexical Normalization for Asian Languages
Jan 23, 2026Social media data has been of interest to Natural Language Processing (NLP) practitioners for over a decade, because of its richness in information, but also challenges for automatic processing. Since language use is more informal, spontaneous, and adheres to many different sociolects, the performance of NLP models often deteriorates. One solution to this problem is to transform data to a standard variant before processing it, which is also called lexical normalization. There has been a wide variety of benchmarks and models proposed for this task. The MultiLexNorm benchmark proposed to unify these efforts, but it consists almost solely of languages from the Indo-European language family in the Latin script. Hence, we propose an extension to MultiLexNorm, which covers 5 Asian languages from different language families in 4 different scripts. We show that the previous state-of-the-art model performs worse on the new languages and propose a new architecture based on Large Language Models (LLMs), which shows more robust performance. Finally, we analyze remaining errors, revealing future directions for this task.
Evaluating Perspectival Biases in Cross-Modal Retrieval
Nov 03, 2025Multimodal retrieval systems are expected to operate in a semantic space, agnostic to the language or cultural origin of the query. In practice, however, retrieval outcomes systematically reflect perspectival biases: deviations shaped by linguistic prevalence and cultural associations. We study two such biases. First, prevalence bias refers to the tendency to favor entries from prevalent languages over semantically faithful entries in image-to-text retrieval. Second, association bias refers to the tendency to favor images culturally associated with the query over semantically correct ones in text-to-image retrieval. Results show that explicit alignment is a more effective strategy for mitigating prevalence bias. However, association bias remains a distinct and more challenging problem. These findings suggest that achieving truly equitable multimodal systems requires targeted strategies beyond simple data scaling and that bias arising from cultural association may be treated as a more challenging problem than one arising from linguistic prevalence.
Distilling Multilingual Vision-Language Models: When Smaller Models Stay Multilingual
Oct 30, 2025Vision-language models (VLMs) exhibit uneven performance across languages, a problem that is often exacerbated when the model size is reduced. While Knowledge distillation (KD) demonstrates promising results in transferring knowledge from larger to smaller VLMs, applying KD in multilingualism is an underexplored area. This paper presents a controlled empirical study of KD behavior across five distillation approaches, isolating their effects on cross-lingual representation consistency and downstream performance stability under model compression. We study five distillation formulations across CLIP and SigLIP2, and evaluate them on in-domain retrieval and out-of-domain visual QA. We find that some configurations preserve or even improve multilingual retrieval robustness despite halving model size, but others fail to maintain cross-task stability, exposing design-sensitive trade-offs that aggregate accuracy alone does not reveal.
WangchanThaiInstruct: An instruction-following Dataset for Culture-Aware, Multitask, and Multi-domain Evaluation in Thai
Aug 21, 2025Large language models excel at instruction-following in English, but their performance in low-resource languages like Thai remains underexplored. Existing benchmarks often rely on translations, missing cultural and domain-specific nuances needed for real-world use. We present WangchanThaiInstruct, a human-authored Thai dataset for evaluation and instruction tuning, covering four professional domains and seven task types. Created through a multi-stage quality control process with annotators, domain experts, and AI researchers, WangchanThaiInstruct supports two studies: (1) a zero-shot evaluation showing performance gaps on culturally and professionally specific tasks, and (2) an instruction tuning study with ablations isolating the effect of native supervision. Models fine-tuned on WangchanThaiInstruct outperform those using translated data in both in-domain and out-of-domain benchmarks. These findings underscore the need for culturally and professionally grounded instruction data to improve LLM alignment in low-resource, linguistically diverse settings.
SEA-BED: Southeast Asia Embedding Benchmark
Aug 17, 2025
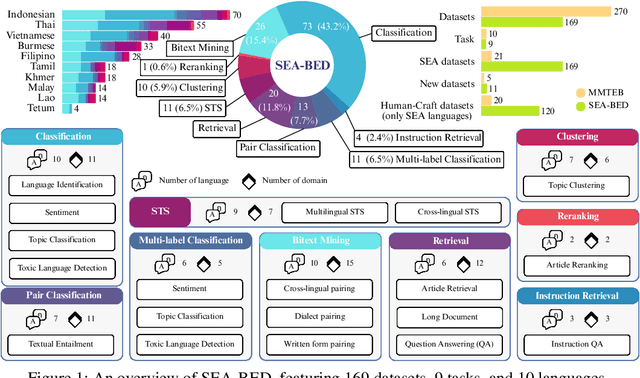


Sentence embeddings are essential for NLP tasks such as semantic search, re-ranking, and textual similarity. Although multilingual benchmarks like MMTEB broaden coverage, Southeast Asia (SEA) datasets are scarce and often machine-translated, missing native linguistic properties. With nearly 700 million speakers, the SEA region lacks a region-specific embedding benchmark. We introduce SEA-BED, the first large-scale SEA embedding benchmark with 169 datasets across 9 tasks and 10 languages, where 71% are formulated by humans, not machine generation or translation. We address three research questions: (1) which SEA languages and tasks are challenging, (2) whether SEA languages show unique performance gaps globally, and (3) how human vs. machine translations affect evaluation. We evaluate 17 embedding models across six studies, analyzing task and language challenges, cross-benchmark comparisons, and translation trade-offs. Results show sharp ranking shifts, inconsistent model performance among SEA languages, and the importance of human-curated datasets for low-resource languages like Burmese.