 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan General-Purpose Large Language Models Generalize to English-Thai Machine Translation ?
Oct 22, 2024


Large language models (LLMs) perform well on common tasks but struggle with generalization in low-resource and low-computation settings. We examine this limitation by testing various LLMs and specialized translation models on English-Thai machine translation and code-switching datasets. Our findings reveal that under more strict computational constraints, such as 4-bit quantization, LLMs fail to translate effectively. In contrast, specialized models, with comparable or lower computational requirements, consistently outperform LLMs. This underscores the importance of specialized models for maintaining performance under resource constraints.
Addressing Topic Leakage in Cross-Topic Evaluation for Authorship Verification
Jul 27, 2024Authorship verification (AV) aims to identify whether a pair of texts has the same author. We address the challenge of evaluating AV models' robustness against topic shifts. The conventional evaluation assumes minimal topic overlap between training and test data. However, we argue that there can still be topic leakage in test data, causing misleading model performance and unstable rankings. To address this, we propose an evaluation method called Heterogeneity-Informed Topic Sampling (HITS), which creates a smaller dataset with a heterogeneously distributed topic set. Our experimental results demonstrate that HITS-sampled datasets yield a more stable ranking of models across random seeds and evaluation splits. Our contributions include: 1. An analysis of causes and effects of topic leakage. 2. A demonstration of the HITS in reducing the effects of topic leakage, and 3. The Robust Authorship Verification bENchmark (RAVEN) that allows topic shortcut test to uncover AV models' reliance on topic-specific features.
ThaiCoref: Thai Coreference Resolution Dataset
Jun 10, 2024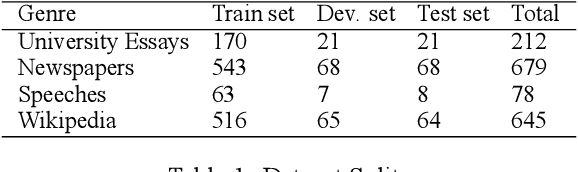
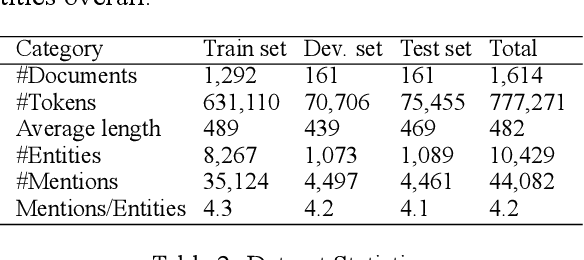
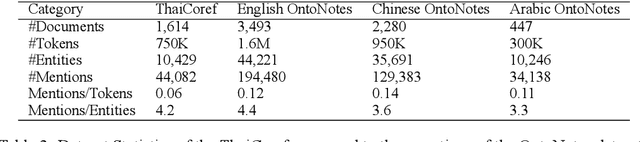
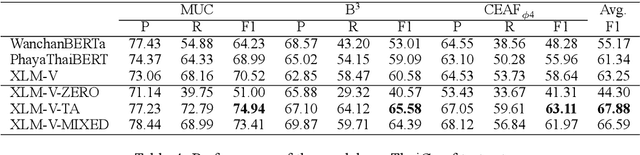
While coreference resolution is a well-established research area in Natural Language Processing (NLP), research focusing on Thai language remains limited due to the lack of large annotated corpora. In this work, we introduce ThaiCoref, a dataset for Thai coreference resolution. Our dataset comprises 777,271 tokens, 44,082 mentions and 10,429 entities across four text genres: university essays, newspapers, speeches, and Wikipedia. Our annotation scheme is built upon the OntoNotes benchmark with adjustments to address Thai-specific phenomena. Utilizing ThaiCoref, we train models employing a multilingual encoder and cross-lingual transfer techniques, achieving a best F1 score of 67.88\% on the test set. Error analysis reveals challenges posed by Thai's unique linguistic features. To benefit the NLP community, we make the dataset and the model publicly available at http://www.github.com/nlp-chula/thai-coref .