 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Extrinsic and Intrinsic Properties for Effective Reasoning with Code Interpreter
Jun 15, 2026Reasoning with a Code Interpreter (CI) has emerged as an effective paradigm for enhancing the reasoning capabilities of large language models (LLMs) through executable computation and iterative verification. Despite its growing adoption, the behavioral properties underlying effective code reasoning remain largely underexplored. In this work, we investigate code reasoning from two distinct perspectives inspired by prior studies of natural language reasoning: extrinsic properties, represented by crucial tokens, and intrinsic properties, represented by code-specific cognitive behaviors. Across multiple LLMs, we find that stronger CI reasoning models consistently exhibit a higher prevalence of crucial tokens and cognitive behaviors, particularly verification, backtracking, and backward chaining. Building on these observations, we examine how these properties can be leveraged during both inference and training. At inference time, appending code-specific crucial tokens improves performance on several reasoning capabilities, including mathematical, ordering, and optimization, while yielding limited benefits elsewhere. At training time, augmenting a state-of-the-art framework with code-specific cognitive behaviors improves supervised fine-tuning and reinforcement learning performance in two of three evaluated models. Further analysis shows that these behaviors reduce overthinking in incorrect responses and improve token efficiency, while also revealing factors that limit gains in a certain model. Our findings provide the first systematic characterization of effective reasoning with CI and demonstrate both the potential and limitations of leveraging key properties to improve CI-based reasoning.
SEA-NLI: Natural Language Inference as a Lens into Southeast Asian Cultural Understanding
Jun 02, 2026Frontier LLMs perform well in Western contexts, but remain poorly tested on underrepresented cultures such as those in Southeast Asia (SEA). Existing NLI benchmarks are largely Western-centric, translation-derived, or monolingual, limiting their ability to measure culturally grounded reasoning. We introduce SEA-NLI, a native, culturally grounded NLI benchmark covering eight SEA countries in English and native regional languages, verified by native speakers. Across 17 encoder and decoder models, we observe a low performance from all models, especially for knowledge-intensive categories such as Languages and Science and Technology. Our analysis shows that failure cases mainly stem from missing SEA cultural knowledge: SEA-adapted models and culture-aware prompting improve performance, while CoT prompting offers limited gains.
WangchanThaiInstruct: An instruction-following Dataset for Culture-Aware, Multitask, and Multi-domain Evaluation in Thai
Aug 21, 2025Large language models excel at instruction-following in English, but their performance in low-resource languages like Thai remains underexplored. Existing benchmarks often rely on translations, missing cultural and domain-specific nuances needed for real-world use. We present WangchanThaiInstruct, a human-authored Thai dataset for evaluation and instruction tuning, covering four professional domains and seven task types. Created through a multi-stage quality control process with annotators, domain experts, and AI researchers, WangchanThaiInstruct supports two studies: (1) a zero-shot evaluation showing performance gaps on culturally and professionally specific tasks, and (2) an instruction tuning study with ablations isolating the effect of native supervision. Models fine-tuned on WangchanThaiInstruct outperform those using translated data in both in-domain and out-of-domain benchmarks. These findings underscore the need for culturally and professionally grounded instruction data to improve LLM alignment in low-resource, linguistically diverse settings.
Crowdsource, Crawl, or Generate? Creating SEA-VL, a Multicultural Vision-Language Dataset for Southeast Asia
Mar 10, 2025



Southeast Asia (SEA) is a region of extraordinary linguistic and cultural diversity, yet it remains significantly underrepresented in vision-language (VL) research. This often results in artificial intelligence (AI) models that fail to capture SEA cultural nuances. To fill this gap, we present SEA-VL, an open-source initiative dedicated to developing high-quality, culturally relevant data for SEA languages. By involving contributors from SEA countries, SEA-VL aims to ensure better cultural relevance and diversity, fostering greater inclusivity of underrepresented languages in VL research. Beyond crowdsourcing, our initiative goes one step further in the exploration of the automatic collection of culturally relevant images through crawling and image generation. First, we find that image crawling achieves approximately ~85% cultural relevance while being more cost- and time-efficient than crowdsourcing. Second, despite the substantial progress in generative vision models, synthetic images remain unreliable in accurately reflecting SEA cultures. The generated images often fail to reflect the nuanced traditions and cultural contexts of the region. Collectively, we gather 1.28M SEA culturally-relevant images, more than 50 times larger than other existing datasets. Through SEA-VL, we aim to bridge the representation gap in SEA, fostering the development of more inclusive AI systems that authentically represent diverse cultures across SEA.
Towards Better Understanding of Program-of-Thought Reasoning in Cross-Lingual and Multilingual Environments
Feb 25, 2025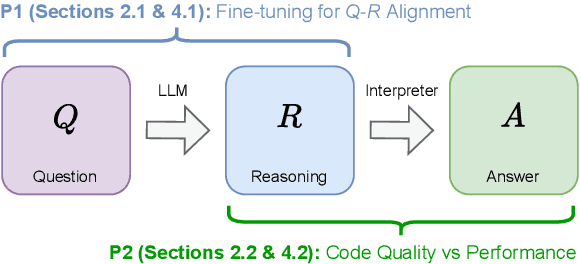

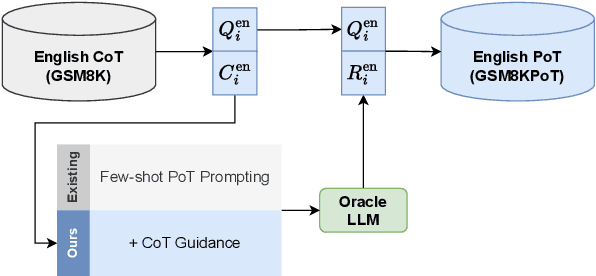

Multi-step reasoning is essential for large language models (LLMs), yet multilingual performance remains challenging. While Chain-of-Thought (CoT) prompting improves reasoning, it struggles with non-English languages due to the entanglement of reasoning and execution. Program-of-Thought (PoT) prompting separates reasoning from execution, offering a promising alternative but shifting the challenge to generating programs from non-English questions. We propose a framework to evaluate PoT by separating multilingual reasoning from code execution to examine (i) the impact of fine-tuning on question-reasoning alignment and (ii) how reasoning quality affects answer correctness. Our findings demonstrate that PoT fine-tuning substantially enhances multilingual reasoning, outperforming CoT fine-tuned models. We further demonstrate a strong correlation between reasoning quality (measured through code quality) and answer accuracy, highlighting its potential as a test-time performance improvement heuristic.
Seed-Free Synthetic Data Generation Framework for Instruction-Tuning LLMs: A Case Study in Thai
Nov 23, 2024We present a synthetic data approach for instruction-tuning large language models (LLMs) for low-resource languages in a data-efficient manner, specifically focusing on Thai. We identify three key properties that contribute to the effectiveness of instruction-tuning datasets: fluency, diversity, and cultural context. We propose a seed-data-free framework for generating synthetic instruction-tuning data that incorporates these essential properties. Our framework employs an LLM to generate diverse topics, retrieve relevant contexts from Wikipedia, and create instructions for various tasks, such as question answering, summarization, and conversation. The experimental results show that our best-performing synthetic dataset, which incorporates all three key properties, achieves competitive performance using only 5,000 instructions when compared to state-of-the-art Thai LLMs trained on hundreds of thousands of instructions. Our code and dataset are publicly available at https://github.com/parinzee/seed-free-synthetic-instruct.
Addressing Topic Leakage in Cross-Topic Evaluation for Authorship Verification
Jul 27, 2024Authorship verification (AV) aims to identify whether a pair of texts has the same author. We address the challenge of evaluating AV models' robustness against topic shifts. The conventional evaluation assumes minimal topic overlap between training and test data. However, we argue that there can still be topic leakage in test data, causing misleading model performance and unstable rankings. To address this, we propose an evaluation method called Heterogeneity-Informed Topic Sampling (HITS), which creates a smaller dataset with a heterogeneously distributed topic set. Our experimental results demonstrate that HITS-sampled datasets yield a more stable ranking of models across random seeds and evaluation splits. Our contributions include: 1. An analysis of causes and effects of topic leakage. 2. A demonstration of the HITS in reducing the effects of topic leakage, and 3. The Robust Authorship Verification bENchmark (RAVEN) that allows topic shortcut test to uncover AV models' reliance on topic-specific features.
WangchanLion and WangchanX MRC Eval
Mar 24, 2024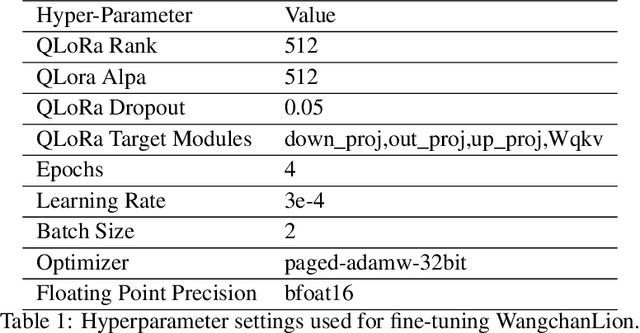

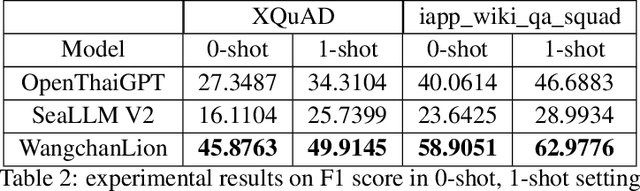
This technical report describes the development of WangchanLion, an instruction fine-tuned model focusing on Machine Reading Comprehension (MRC) in the Thai language. Our model is based on SEA-LION and a collection of instruction following datasets. To promote open research and reproducibility, we publically release all training data, code, and the final model weights under the Apache-2 license. To assess the contextual understanding capability, we conducted extensive experimental studies using two Thai MRC datasets, XQuAD and Iapp_wiki_qa_squad. Experimental results demonstrate the model's ability to comprehend the context and produce an answer faithful to the reference one in 0-shot and 1-shot settings. In addition, our evaluation goes beyond the traditional MRC. We propose a new evaluation scheme assessing the answer's correctness, helpfulness, conciseness, and contextuality. Evaluation results provide insight into how we can improve our model in the future. Our code is public at https://github.com/vistec-AI/WangchanLion.
PyThaiNLP: Thai Natural Language Processing in Python
Dec 07, 2023
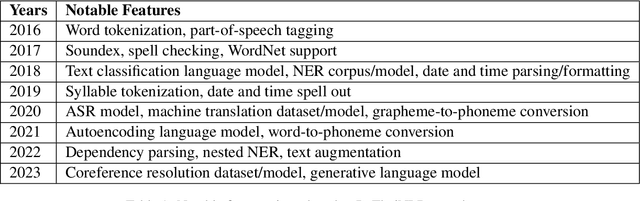
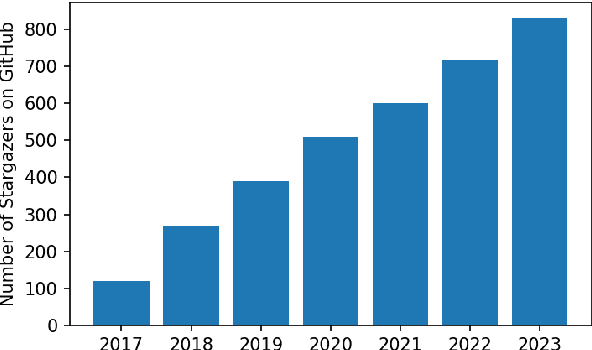
We present PyThaiNLP, a free and open-source natural language processing (NLP) library for Thai language implemented in Python. It provides a wide range of software, models, and datasets for Thai language. We first provide a brief historical context of tools for Thai language prior to the development of PyThaiNLP. We then outline the functionalities it provided as well as datasets and pre-trained language models. We later summarize its development milestones and discuss our experience during its development. We conclude by demonstrating how industrial and research communities utilize PyThaiNLP in their work. The library is freely available at https://github.com/pythainlp/pythainlp.
An Efficient Self-Supervised Cross-View Training For Sentence Embedding
Nov 06, 2023Self-supervised sentence representation learning is the task of constructing an embedding space for sentences without relying on human annotation efforts. One straightforward approach is to finetune a pretrained language model (PLM) with a representation learning method such as contrastive learning. While this approach achieves impressive performance on larger PLMs, the performance rapidly degrades as the number of parameters decreases. In this paper, we propose a framework called Self-supervised Cross-View Training (SCT) to narrow the performance gap between large and small PLMs. To evaluate the effectiveness of SCT, we compare it to 5 baseline and state-of-the-art competitors on seven Semantic Textual Similarity (STS) benchmarks using 5 PLMs with the number of parameters ranging from 4M to 340M. The experimental results show that STC outperforms the competitors for PLMs with less than 100M parameters in 18 of 21 cases.