 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaRec: Adaptive Recommendation with LLMs via Narrative Profiling and Dual-Channel Reasoning
Nov 10, 2025We propose AdaRec, a few-shot in-context learning framework that leverages large language models for an adaptive personalized recommendation. AdaRec introduces narrative profiling, transforming user-item interactions into natural language representations to enable unified task handling and enhance human readability. Centered on a bivariate reasoning paradigm, AdaRec employs a dual-channel architecture that integrates horizontal behavioral alignment, discovering peer-driven patterns, with vertical causal attribution, highlighting decisive factors behind user preferences. Unlike existing LLM-based approaches, AdaRec eliminates manual feature engineering through semantic representations and supports rapid cross-task adaptation with minimal supervision. Experiments on real ecommerce datasets demonstrate that AdaRec outperforms both machine learning models and LLM-based baselines by up to eight percent in few-shot settings. In zero-shot scenarios, it achieves up to a nineteen percent improvement over expert-crafted profiling, showing effectiveness for long-tail personalization with minimal interaction data. Furthermore, lightweight fine-tuning on synthetic data generated by AdaRec matches the performance of fully fine-tuned models, highlighting its efficiency and generalization across diverse tasks.
Segment Discovery: Enhancing E-commerce Targeting
Sep 20, 2024Modern e-commerce services frequently target customers with incentives or interventions to engage them in their products such as games, shopping, video streaming, etc. This customer engagement increases acquisition of more customers and retention of existing ones, leading to more business for the company while improving customer experience. Often, customers are either randomly targeted or targeted based on the propensity of desirable behavior. However, such policies can be suboptimal as they do not target the set of customers who would benefit the most from the intervention and they may also not take account of any constraints. In this paper, we propose a policy framework based on uplift modeling and constrained optimization that identifies customers to target for a use-case specific intervention so as to maximize the value to the business, while taking account of any given constraints. We demonstrate improvement over state-of-the-art targeting approaches using two large-scale experimental studies and a production implementation.
ThaiCoref: Thai Coreference Resolution Dataset
Jun 10, 2024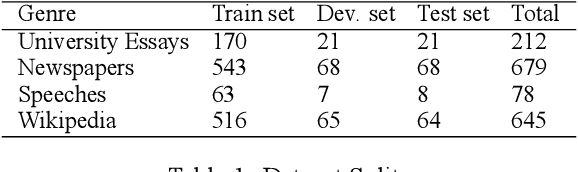
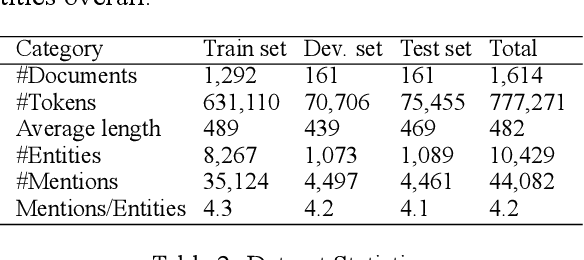
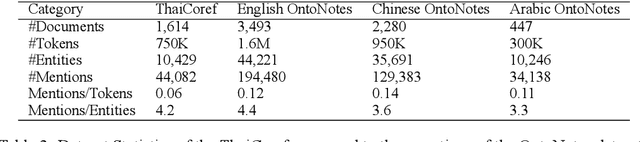
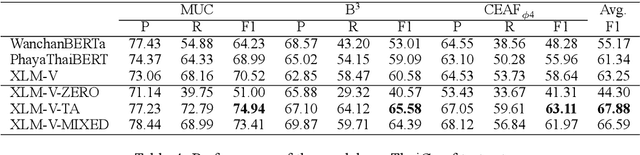
While coreference resolution is a well-established research area in Natural Language Processing (NLP), research focusing on Thai language remains limited due to the lack of large annotated corpora. In this work, we introduce ThaiCoref, a dataset for Thai coreference resolution. Our dataset comprises 777,271 tokens, 44,082 mentions and 10,429 entities across four text genres: university essays, newspapers, speeches, and Wikipedia. Our annotation scheme is built upon the OntoNotes benchmark with adjustments to address Thai-specific phenomena. Utilizing ThaiCoref, we train models employing a multilingual encoder and cross-lingual transfer techniques, achieving a best F1 score of 67.88\% on the test set. Error analysis reveals challenges posed by Thai's unique linguistic features. To benefit the NLP community, we make the dataset and the model publicly available at http://www.github.com/nlp-chula/thai-coref .
Thai Universal Dependency Treebank
May 13, 2024Automatic dependency parsing of Thai sentences has been underexplored, as evidenced by the lack of large Thai dependency treebanks with complete dependency structures and the lack of a published systematic evaluation of state-of-the-art models, especially transformer-based parsers. In this work, we address these problems by introducing Thai Universal Dependency Treebank (TUD), a new largest Thai treebank consisting of 3,627 trees annotated in accordance with the Universal Dependencies (UD) framework. We then benchmark dependency parsing models that incorporate pretrained transformers as encoders and train them on Thai-PUD and our TUD. The evaluation results show that most of our models can outperform other models reported in previous papers and provide insight into the optimal choices of components to include in Thai dependency parsers. The new treebank and every model's full prediction generated in our experiment are made available on a GitHub repository for further study.
PyThaiNLP: Thai Natural Language Processing in Python
Dec 07, 2023
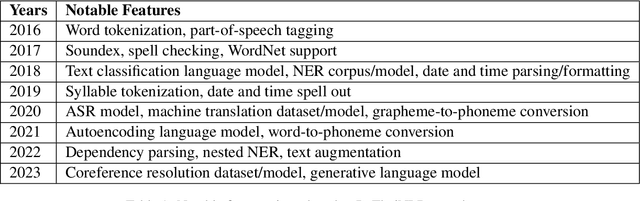
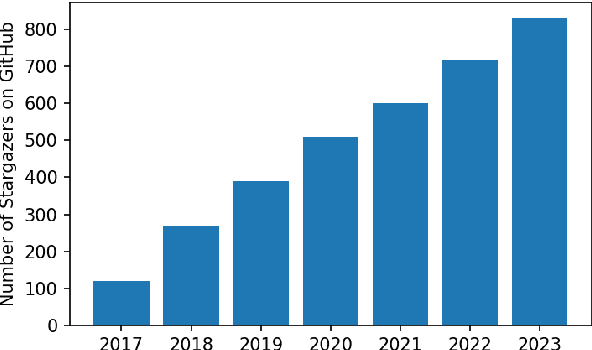
We present PyThaiNLP, a free and open-source natural language processing (NLP) library for Thai language implemented in Python. It provides a wide range of software, models, and datasets for Thai language. We first provide a brief historical context of tools for Thai language prior to the development of PyThaiNLP. We then outline the functionalities it provided as well as datasets and pre-trained language models. We later summarize its development milestones and discuss our experience during its development. We conclude by demonstrating how industrial and research communities utilize PyThaiNLP in their work. The library is freely available at https://github.com/pythainlp/pythainlp.
WangchanBERTa: Pretraining transformer-based Thai Language Models
Jan 24, 2021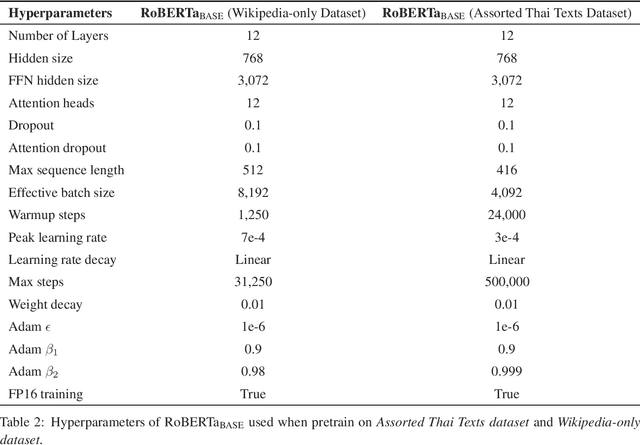
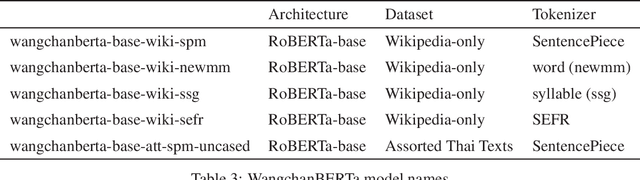
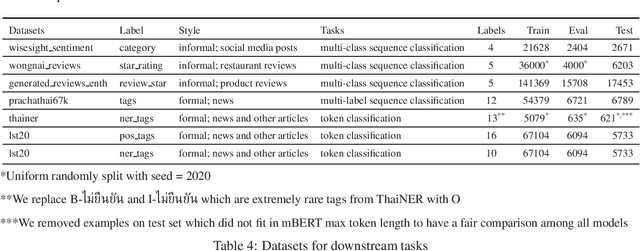
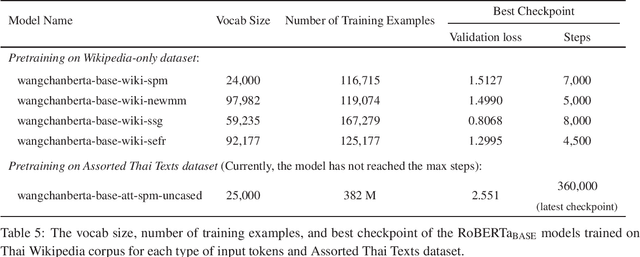
Transformer-based language models, more specifically BERT-based architectures have achieved state-of-the-art performance in many downstream tasks. However, for a relatively low-resource language such as Thai, the choices of models are limited to training a BERT-based model based on a much smaller dataset or finetuning multi-lingual models, both of which yield suboptimal downstream performance. Moreover, large-scale multi-lingual pretraining does not take into account language-specific features for Thai. To overcome these limitations, we pretrain a language model based on RoBERTa-base architecture on a large, deduplicated, cleaned training set (78GB in total size), curated from diverse domains of social media posts, news articles and other publicly available datasets. We apply text processing rules that are specific to Thai most importantly preserving spaces, which are important chunk and sentence boundaries in Thai before subword tokenization. We also experiment with word-level, syllable-level and SentencePiece tokenization with a smaller dataset to explore the effects on tokenization on downstream performance. Our model wangchanberta-base-att-spm-uncased trained on the 78.5GB dataset outperforms strong baselines (NBSVM, CRF and ULMFit) and multi-lingual models (XLMR and mBERT) on both sequence classification and token classification tasks in human-annotated, mono-lingual contexts.
scb-mt-en-th-2020: A Large English-Thai Parallel Corpus
Jul 07, 2020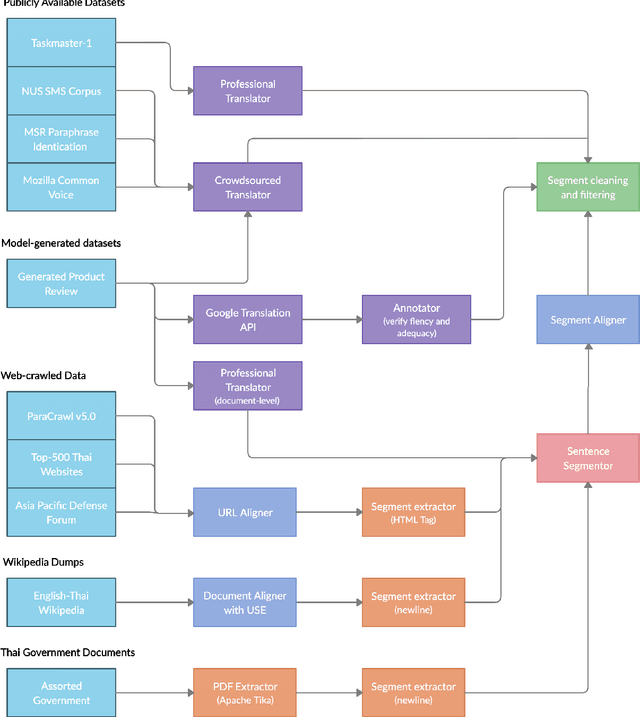
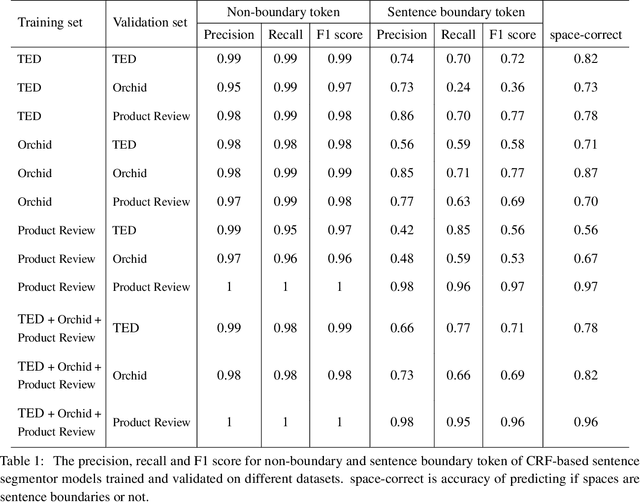
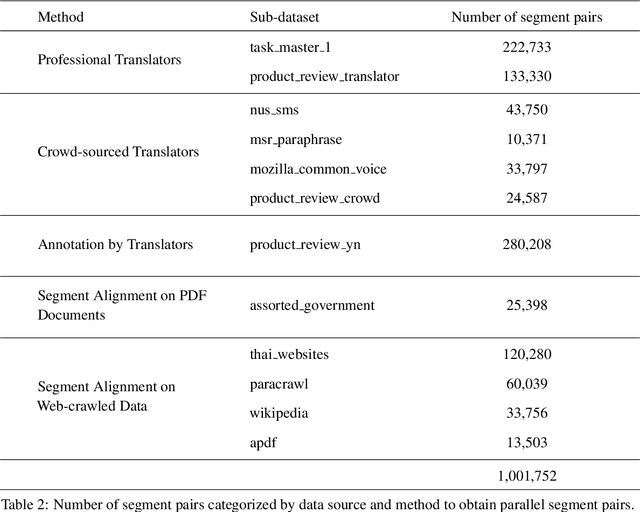
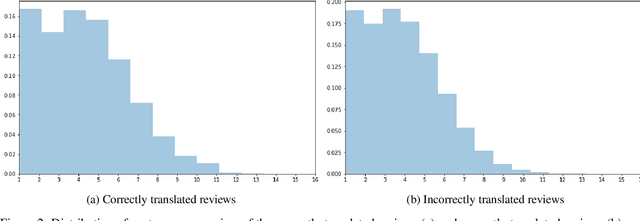
The primary objective of our work is to build a large-scale English-Thai dataset for machine translation. We construct an English-Thai machine translation dataset with over 1 million segment pairs, curated from various sources, namely news, Wikipedia articles, SMS messages, task-based dialogs, web-crawled data and government documents. Methodology for gathering data, building parallel texts and removing noisy sentence pairs are presented in a reproducible manner. We train machine translation models based on this dataset. Our models' performance are comparable to that of Google Translation API (as of May 2020) for Thai-English and outperform Google when the Open Parallel Corpus (OPUS) is included in the training data for both Thai-English and English-Thai translation. The dataset, pre-trained models, and source code to reproduce our work are available for public use.