 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSailor2: Sailing in South-East Asia with Inclusive Multilingual LLMs
Feb 18, 2025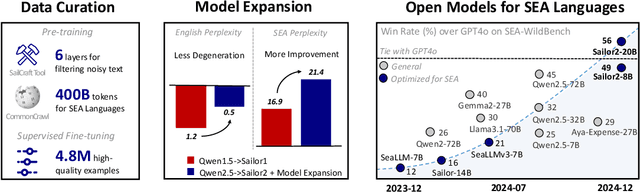
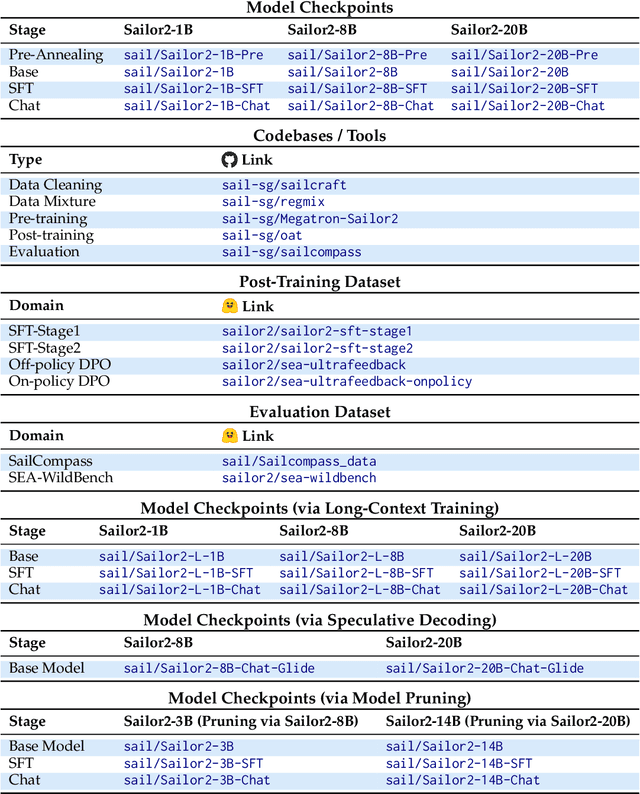

Sailor2 is a family of cutting-edge multilingual language models for South-East Asian (SEA) languages, available in 1B, 8B, and 20B sizes to suit diverse applications. Building on Qwen2.5, Sailor2 undergoes continuous pre-training on 500B tokens (400B SEA-specific and 100B replay tokens) to support 13 SEA languages while retaining proficiency in Chinese and English. Sailor2-20B model achieves a 50-50 win rate against GPT-4o across SEA languages. We also deliver a comprehensive cookbook on how to develop the multilingual model in an efficient manner, including five key aspects: data curation, pre-training, post-training, model customization and evaluation. We hope that Sailor2 model (Apache 2.0 license) will drive language development in the SEA region, and Sailor2 cookbook will inspire researchers to build more inclusive LLMs for other under-served languages.
WangchanLion and WangchanX MRC Eval
Mar 24, 2024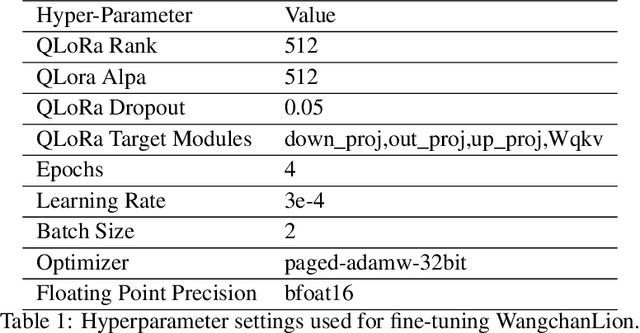

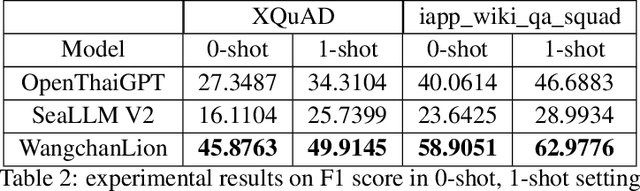
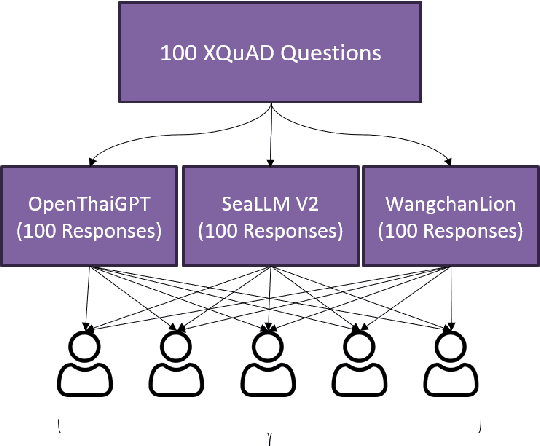
This technical report describes the development of WangchanLion, an instruction fine-tuned model focusing on Machine Reading Comprehension (MRC) in the Thai language. Our model is based on SEA-LION and a collection of instruction following datasets. To promote open research and reproducibility, we publically release all training data, code, and the final model weights under the Apache-2 license. To assess the contextual understanding capability, we conducted extensive experimental studies using two Thai MRC datasets, XQuAD and Iapp_wiki_qa_squad. Experimental results demonstrate the model's ability to comprehend the context and produce an answer faithful to the reference one in 0-shot and 1-shot settings. In addition, our evaluation goes beyond the traditional MRC. We propose a new evaluation scheme assessing the answer's correctness, helpfulness, conciseness, and contextuality. Evaluation results provide insight into how we can improve our model in the future. Our code is public at https://github.com/vistec-AI/WangchanLion.
PyThaiNLP: Thai Natural Language Processing in Python
Dec 07, 2023
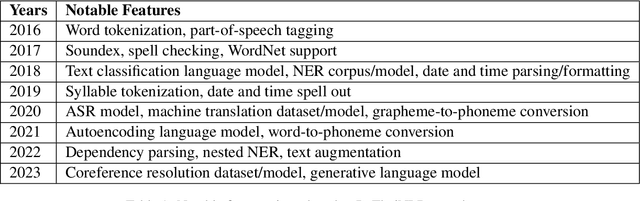
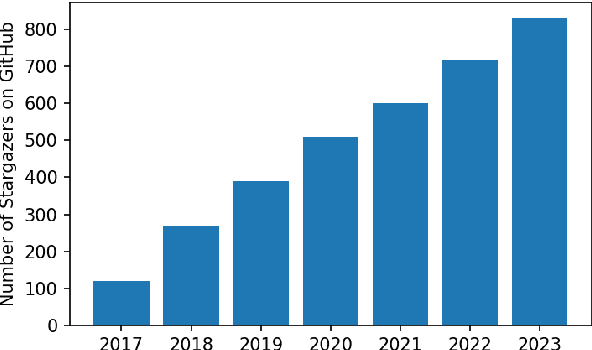
We present PyThaiNLP, a free and open-source natural language processing (NLP) library for Thai language implemented in Python. It provides a wide range of software, models, and datasets for Thai language. We first provide a brief historical context of tools for Thai language prior to the development of PyThaiNLP. We then outline the functionalities it provided as well as datasets and pre-trained language models. We later summarize its development milestones and discuss our experience during its development. We conclude by demonstrating how industrial and research communities utilize PyThaiNLP in their work. The library is freely available at https://github.com/pythainlp/pythainlp.
Thai Wav2Vec2.0 with CommonVoice V8
Aug 09, 2022

Recently, Automatic Speech Recognition (ASR), a system that converts audio into text, has caught a lot of attention in the machine learning community. Thus, a lot of publicly available models were released in HuggingFace. However, most of these ASR models are available in English; only a minority of the models are available in Thai. Additionally, most of the Thai ASR models are closed-sourced, and the performance of existing open-sourced models lacks robustness. To address this problem, we train a new ASR model on a pre-trained XLSR-Wav2Vec model with the Thai CommonVoice corpus V8 and train a trigram language model to boost the performance of our ASR model. We hope that our models will be beneficial to individuals and the ASR community in Thailand.