 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillCraft: Can LLM Agents Learn to Use Tools Skillfully?
Feb 28, 2026Real-world tool-using agents operate over long-horizon workflows with recurring structure and diverse demands, where effective behavior requires not only invoking atomic tools but also abstracting, and reusing higher-level tool compositions. However, existing benchmarks mainly measure instance-level success under static tool sets, offering limited insight into agents' ability to acquire such reusable skills. We address this gap by introducing SkillCraft, a benchmark explicitly stress-test agent ability to form and reuse higher-level tool compositions, where we call Skills. SkillCraft features realistic, highly compositional tool-use scenarios with difficulty scaled along both quantitative and structural dimensions, designed to elicit skill abstraction and cross-task reuse. We further propose a lightweight evaluation protocol that enables agents to auto-compose atomic tools into executable Skills, cache and reuse them inside and across tasks, thereby improving efficiency while accumulating a persistent library of reusable skills. Evaluating state-of-the-art agents on SkillCraft, we observe substantial efficiency gains, with token usage reduced by up to 80% by skill saving and reuse. Moreover, success rate strongly correlates with tool composition ability at test time, underscoring compositional skill acquisition as a core capability.
Bring Reason to Vision: Understanding Perception and Reasoning through Model Merging
May 08, 2025Vision-Language Models (VLMs) combine visual perception with the general capabilities, such as reasoning, of Large Language Models (LLMs). However, the mechanisms by which these two abilities can be combined and contribute remain poorly understood. In this work, we explore to compose perception and reasoning through model merging that connects parameters of different models. Unlike previous works that often focus on merging models of the same kind, we propose merging models across modalities, enabling the incorporation of the reasoning capabilities of LLMs into VLMs. Through extensive experiments, we demonstrate that model merging offers a successful pathway to transfer reasoning abilities from LLMs to VLMs in a training-free manner. Moreover, we utilize the merged models to understand the internal mechanism of perception and reasoning and how merging affects it. We find that perception capabilities are predominantly encoded in the early layers of the model, whereas reasoning is largely facilitated by the middle-to-late layers. After merging, we observe that all layers begin to contribute to reasoning, whereas the distribution of perception abilities across layers remains largely unchanged. These observations shed light on the potential of model merging as a tool for multimodal integration and interpretation.
SkyLadder: Better and Faster Pretraining via Context Window Scheduling
Mar 19, 2025



Recent advancements in LLM pretraining have featured ever-expanding context windows to process longer sequences. However, our pilot study reveals that models pretrained with shorter context windows consistently outperform their long-context counterparts under a fixed token budget. This finding motivates us to explore an optimal context window scheduling strategy to better balance long-context capability with pretraining efficiency. To this end, we propose SkyLadder, a simple yet effective approach that implements a short-to-long context window transition. SkyLadder preserves strong standard benchmark performance, while matching or exceeding baseline results on long context tasks. Through extensive experiments, we pre-train 1B-parameter models (up to 32K context) and 3B-parameter models (8K context) on 100B tokens, demonstrating that SkyLadder yields consistent gains of up to 3.7% on common benchmarks, while achieving up to 22% faster training speeds compared to baselines. The code is at https://github.com/sail-sg/SkyLadder.
Why Is Spatial Reasoning Hard for VLMs? An Attention Mechanism Perspective on Focus Areas
Mar 04, 2025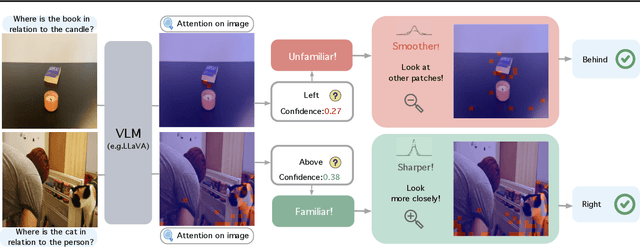

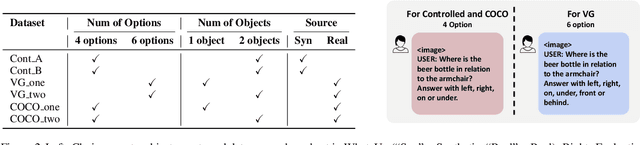

Large Vision Language Models (VLMs) have long struggled with spatial reasoning tasks. Surprisingly, even simple spatial reasoning tasks, such as recognizing "under" or "behind" relationships between only two objects, pose significant challenges for current VLMs. In this work, we study the spatial reasoning challenge from the lens of mechanistic interpretability, diving into the model's internal states to examine the interactions between image and text tokens. By tracing attention distribution over the image through out intermediate layers, we observe that successful spatial reasoning correlates strongly with the model's ability to align its attention distribution with actual object locations, particularly differing between familiar and unfamiliar spatial relationships. Motivated by these findings, we propose ADAPTVIS based on inference-time confidence scores to sharpen the attention on highly relevant regions when confident, while smoothing and broadening the attention window to consider a wider context when confidence is lower. This training-free decoding method shows significant improvement (e.g., up to a 50 absolute point improvement) on spatial reasoning benchmarks such as WhatsUp and VSR with negligible cost. We make code and data publicly available for research purposes at https://github.com/shiqichen17/AdaptVis.
Sailor2: Sailing in South-East Asia with Inclusive Multilingual LLMs
Feb 18, 2025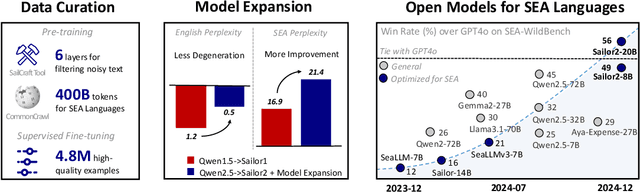
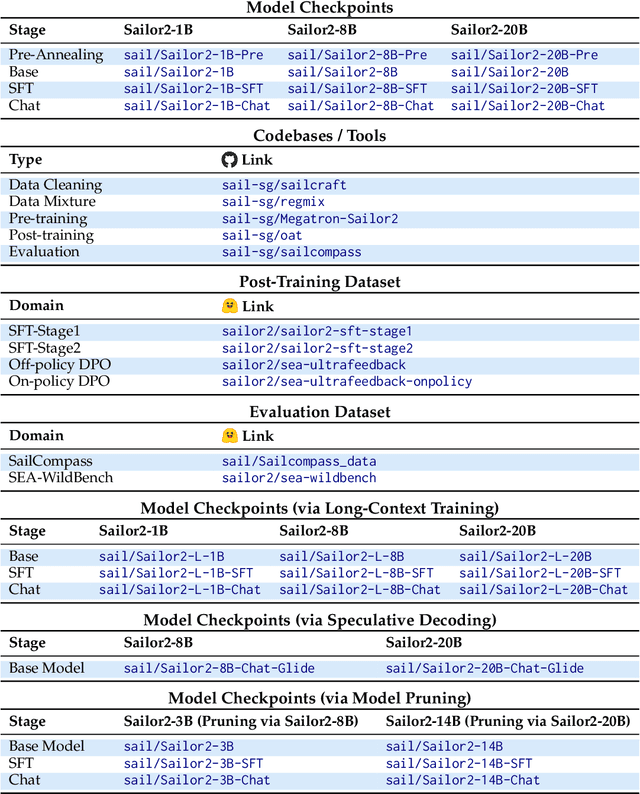

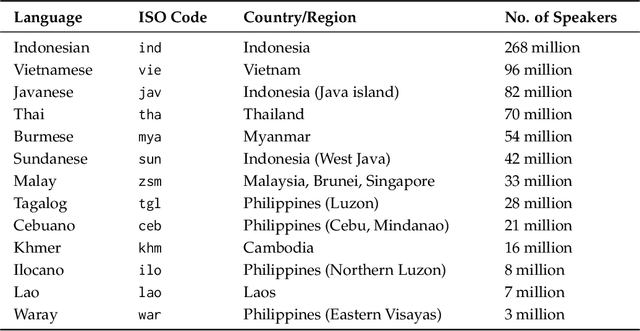
Sailor2 is a family of cutting-edge multilingual language models for South-East Asian (SEA) languages, available in 1B, 8B, and 20B sizes to suit diverse applications. Building on Qwen2.5, Sailor2 undergoes continuous pre-training on 500B tokens (400B SEA-specific and 100B replay tokens) to support 13 SEA languages while retaining proficiency in Chinese and English. Sailor2-20B model achieves a 50-50 win rate against GPT-4o across SEA languages. We also deliver a comprehensive cookbook on how to develop the multilingual model in an efficient manner, including five key aspects: data curation, pre-training, post-training, model customization and evaluation. We hope that Sailor2 model (Apache 2.0 license) will drive language development in the SEA region, and Sailor2 cookbook will inspire researchers to build more inclusive LLMs for other under-served languages.
When Precision Meets Position: BFloat16 Breaks Down RoPE in Long-Context Training
Nov 20, 2024



Extending context window sizes allows large language models (LLMs) to process longer sequences and handle more complex tasks. Rotary Positional Embedding (RoPE) has become the de facto standard due to its relative positional encoding properties that benefit long-context training. However, we observe that using RoPE with BFloat16 format results in numerical issues, causing it to deviate from its intended relative positional encoding, especially in long-context scenarios. This issue arises from BFloat16's limited precision and accumulates as context length increases, with the first token contributing significantly to this problem. To address this, we develop AnchorAttention, a plug-and-play attention method that alleviates numerical issues caused by BFloat16, improves long-context capabilities, and speeds up training. AnchorAttention reduces unnecessary attention computations, maintains semantic coherence, and boosts computational efficiency by treating the first token as a shared anchor with a consistent position ID, making it visible to all documents within the training context. Experiments on three types of LLMs demonstrate that AnchorAttention significantly improves long-context performance and reduces training time by over 50\% compared to standard full attention mechanisms, while preserving the original LLM's capabilities on general tasks. Our code is available at https://github.com/haonan3/AnchorContext.
CCSBench: Evaluating Compositional Controllability in LLMs for Scientific Document Summarization
Oct 16, 2024
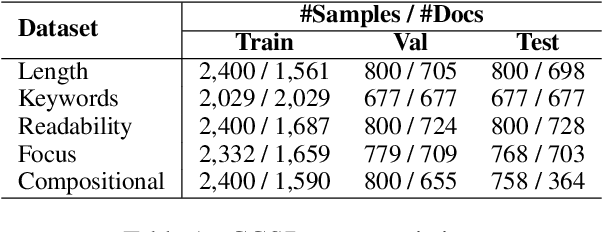
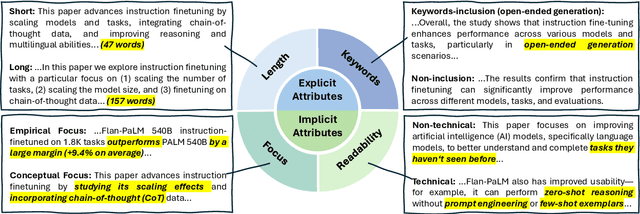

To broaden the dissemination of scientific knowledge to diverse audiences, scientific document summarization must simultaneously control multiple attributes such as length and empirical focus. However, existing research typically focuses on controlling single attributes, leaving the compositional control of multiple attributes underexplored. To address this gap, we introduce CCSBench, a benchmark for compositional controllable summarization in the scientific domain. Our benchmark enables fine-grained control over both explicit attributes (e.g., length), which are objective and straightforward, and implicit attributes (e.g., empirical focus), which are more subjective and conceptual. We conduct extensive experiments on GPT-4, LLaMA2, and other popular LLMs under various settings. Our findings reveal significant limitations in large language models' ability to balance trade-offs between control attributes, especially implicit ones that require deeper understanding and abstract reasoning.
Beyond Memorization: The Challenge of Random Memory Access in Language Models
Mar 13, 2024



Recent developments in Language Models (LMs) have shown their effectiveness in NLP tasks, particularly in knowledge-intensive tasks. However, the mechanisms underlying knowledge storage and memory access within their parameters remain elusive. In this paper, we investigate whether a generative LM (e.g., GPT-2) is able to access its memory sequentially or randomly. Through carefully-designed synthetic tasks, covering the scenarios of full recitation, selective recitation and grounded question answering, we reveal that LMs manage to sequentially access their memory while encountering challenges in randomly accessing memorized content. We find that techniques including recitation and permutation improve the random memory access capability of LMs. Furthermore, by applying this intervention to realistic scenarios of open-domain question answering, we validate that enhancing random access by recitation leads to notable improvements in question answering. The code to reproduce our experiments can be found at https://github.com/sail-sg/lm-random-memory-access.
Translating Natural Language to Planning Goals with Large-Language Models
Feb 10, 2023
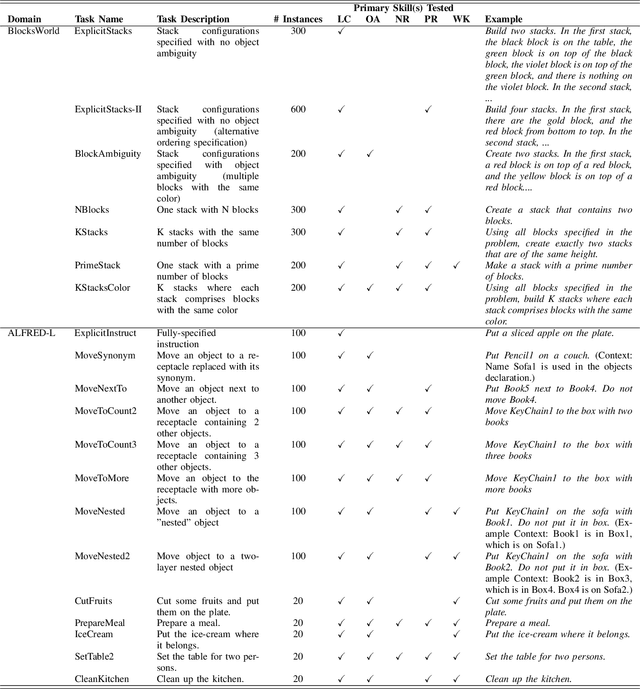


Recent large language models (LLMs) have demonstrated remarkable performance on a variety of natural language processing (NLP) tasks, leading to intense excitement about their applicability across various domains. Unfortunately, recent work has also shown that LLMs are unable to perform accurate reasoning nor solve planning problems, which may limit their usefulness for robotics-related tasks. In this work, our central question is whether LLMs are able to translate goals specified in natural language to a structured planning language. If so, LLM can act as a natural interface between the planner and human users; the translated goal can be handed to domain-independent AI planners that are very effective at planning. Our empirical results on GPT 3.5 variants show that LLMs are much better suited towards translation rather than planning. We find that LLMs are able to leverage commonsense knowledge and reasoning to furnish missing details from under-specified goals (as is often the case in natural language). However, our experiments also reveal that LLMs can fail to generate goals in tasks that involve numerical or physical (e.g., spatial) reasoning, and that LLMs are sensitive to the prompts used. As such, these models are promising for translation to structured planning languages, but care should be taken in their use.