 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhantom Menace: Exploring and Enhancing the Robustness of VLA Models against Physical Sensor Attacks
Nov 13, 2025Vision-Language-Action (VLA) models revolutionize robotic systems by enabling end-to-end perception-to-action pipelines that integrate multiple sensory modalities, such as visual signals processed by cameras and auditory signals captured by microphones. This multi-modality integration allows VLA models to interpret complex, real-world environments using diverse sensor data streams. Given the fact that VLA-based systems heavily rely on the sensory input, the security of VLA models against physical-world sensor attacks remains critically underexplored. To address this gap, we present the first systematic study of physical sensor attacks against VLAs, quantifying the influence of sensor attacks and investigating the defenses for VLA models. We introduce a novel ``Real-Sim-Real'' framework that automatically simulates physics-based sensor attack vectors, including six attacks targeting cameras and two targeting microphones, and validates them on real robotic systems. Through large-scale evaluations across various VLA architectures and tasks under varying attack parameters, we demonstrate significant vulnerabilities, with susceptibility patterns that reveal critical dependencies on task types and model designs. We further develop an adversarial-training-based defense that enhances VLA robustness against out-of-distribution physical perturbations caused by sensor attacks while preserving model performance. Our findings expose an urgent need for standardized robustness benchmarks and mitigation strategies to secure VLA deployments in safety-critical environments.
Learn to Reason Efficiently with Adaptive Length-based Reward Shaping
May 21, 2025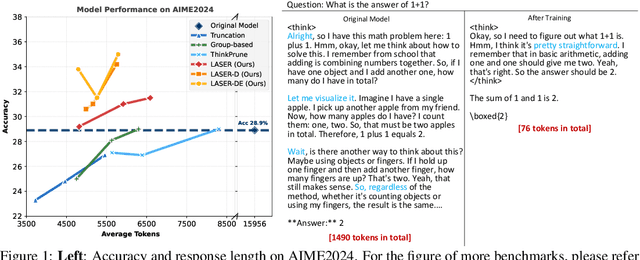
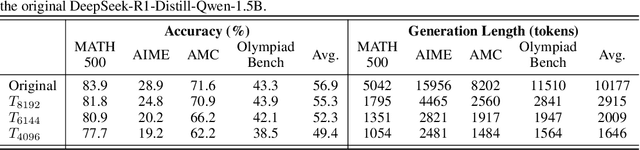
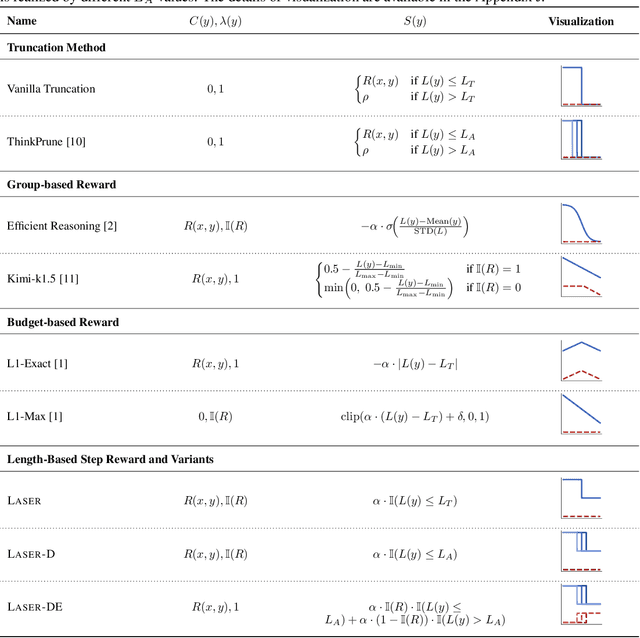
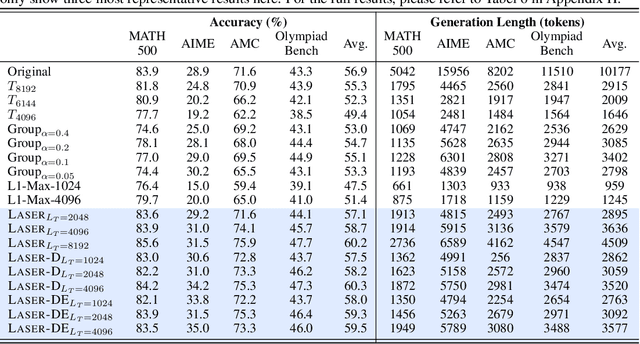
Large Reasoning Models (LRMs) have shown remarkable capabilities in solving complex problems through reinforcement learning (RL), particularly by generating long reasoning traces. However, these extended outputs often exhibit substantial redundancy, which limits the efficiency of LRMs. In this paper, we investigate RL-based approaches to promote reasoning efficiency. Specifically, we first present a unified framework that formulates various efficient reasoning methods through the lens of length-based reward shaping. Building on this perspective, we propose a novel Length-bAsed StEp Reward shaping method (LASER), which employs a step function as the reward, controlled by a target length. LASER surpasses previous methods, achieving a superior Pareto-optimal balance between performance and efficiency. Next, we further extend LASER based on two key intuitions: (1) The reasoning behavior of the model evolves during training, necessitating reward specifications that are also adaptive and dynamic; (2) Rather than uniformly encouraging shorter or longer chains of thought (CoT), we posit that length-based reward shaping should be difficulty-aware i.e., it should penalize lengthy CoTs more for easy queries. This approach is expected to facilitate a combination of fast and slow thinking, leading to a better overall tradeoff. The resulting method is termed LASER-D (Dynamic and Difficulty-aware). Experiments on DeepSeek-R1-Distill-Qwen-1.5B, DeepSeek-R1-Distill-Qwen-7B, and DeepSeek-R1-Distill-Qwen-32B show that our approach significantly enhances both reasoning performance and response length efficiency. For instance, LASER-D and its variant achieve a +6.1 improvement on AIME2024 while reducing token usage by 63%. Further analysis reveals our RL-based compression produces more concise reasoning patterns with less redundant "self-reflections". Resources are at https://github.com/hkust-nlp/Laser.
Why Is Spatial Reasoning Hard for VLMs? An Attention Mechanism Perspective on Focus Areas
Mar 04, 2025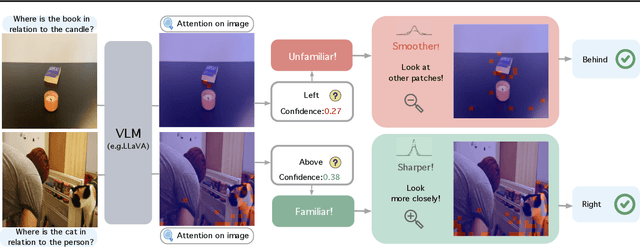

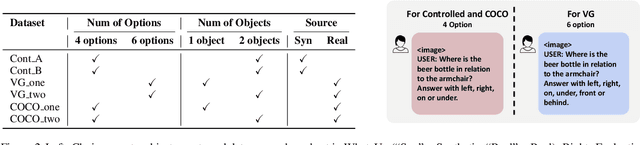

Large Vision Language Models (VLMs) have long struggled with spatial reasoning tasks. Surprisingly, even simple spatial reasoning tasks, such as recognizing "under" or "behind" relationships between only two objects, pose significant challenges for current VLMs. In this work, we study the spatial reasoning challenge from the lens of mechanistic interpretability, diving into the model's internal states to examine the interactions between image and text tokens. By tracing attention distribution over the image through out intermediate layers, we observe that successful spatial reasoning correlates strongly with the model's ability to align its attention distribution with actual object locations, particularly differing between familiar and unfamiliar spatial relationships. Motivated by these findings, we propose ADAPTVIS based on inference-time confidence scores to sharpen the attention on highly relevant regions when confident, while smoothing and broadening the attention window to consider a wider context when confidence is lower. This training-free decoding method shows significant improvement (e.g., up to a 50 absolute point improvement) on spatial reasoning benchmarks such as WhatsUp and VSR with negligible cost. We make code and data publicly available for research purposes at https://github.com/shiqichen17/AdaptVis.
Image-of-Thought Prompting for Visual Reasoning Refinement in Multimodal Large Language Models
May 22, 2024



Recent advancements in Chain-of-Thought (CoT) and related rationale-based works have significantly improved the performance of Large Language Models (LLMs) in complex reasoning tasks. With the evolution of Multimodal Large Language Models (MLLMs), enhancing their capability to tackle complex multimodal reasoning problems is a crucial frontier. However, incorporating multimodal rationales in CoT has yet to be thoroughly investigated. We propose the Image-of-Thought (IoT) prompting method, which helps MLLMs to extract visual rationales step-by-step. Specifically, IoT prompting can automatically design critical visual information extraction operations based on the input images and questions. Each step of visual information refinement identifies specific visual rationales that support answers to complex visual reasoning questions. Beyond the textual CoT, IoT simultaneously utilizes visual and textual rationales to help MLLMs understand complex multimodal information. IoT prompting has improved zero-shot visual reasoning performance across various visual understanding tasks in different MLLMs. Moreover, the step-by-step visual feature explanations generated by IoT prompting elucidate the visual reasoning process, aiding in analyzing the cognitive processes of large multimodal models