 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALLabel: Three-stage Active Learning for LLM-based Entity Recognition using Demonstration Retrieval
Sep 09, 2025Many contemporary data-driven research efforts in the natural sciences, such as chemistry and materials science, require large-scale, high-performance entity recognition from scientific datasets. Large language models (LLMs) have increasingly been adopted to solve the entity recognition task, with the same trend being observed on all-spectrum NLP tasks. The prevailing entity recognition LLMs rely on fine-tuned technology, yet the fine-tuning process often incurs significant cost. To achieve a best performance-cost trade-off, we propose ALLabel, a three-stage framework designed to select the most informative and representative samples in preparing the demonstrations for LLM modeling. The annotated examples are used to construct a ground-truth retrieval corpus for LLM in-context learning. By sequentially employing three distinct active learning strategies, ALLabel consistently outperforms all baselines under the same annotation budget across three specialized domain datasets. Experimental results also demonstrate that selectively annotating only 5\%-10\% of the dataset with ALLabel can achieve performance comparable to the method annotating the entire dataset. Further analyses and ablation studies verify the effectiveness and generalizability of our proposal.
Pre-DPO: Improving Data Utilization in Direct Preference Optimization Using a Guiding Reference Model
Apr 22, 2025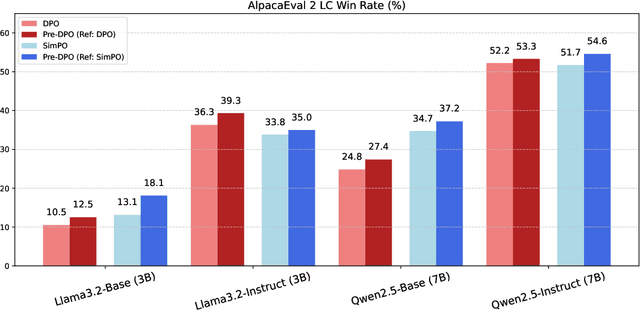
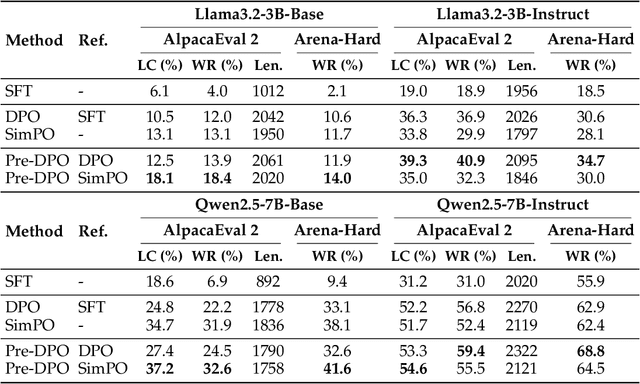
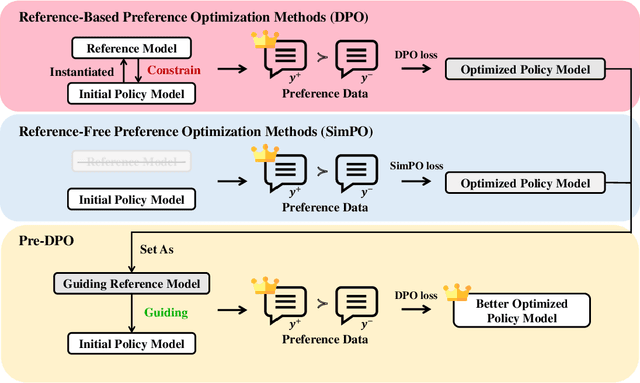
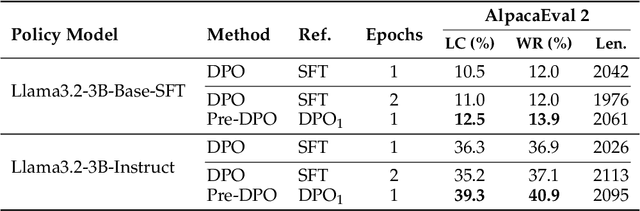
Direct Preference Optimization (DPO) simplifies reinforcement learning from human feedback (RLHF) for large language models (LLMs) by directly optimizing human preferences without an explicit reward model. We find that during DPO training, the reference model plays the role of a data weight adjuster. However, the common practice of initializing the policy and reference models identically in DPO can lead to inefficient data utilization and impose a performance ceiling. Meanwhile, the lack of a reference model in Simple Preference Optimization (SimPO) reduces training robustness and necessitates stricter conditions to prevent catastrophic forgetting. In this work, we propose Pre-DPO, a simple yet effective DPO-based training paradigm that enhances preference optimization performance by leveraging a guiding reference model. This reference model provides foresight into the optimal policy state achievable through the training preference data, serving as a guiding mechanism that adaptively assigns higher weights to samples more suitable for the model and lower weights to those less suitable. Extensive experiments on AlpacaEval 2.0 and Arena-Hard v0.1 benchmarks demonstrate that Pre-DPO consistently improves the performance of both DPO and SimPO, without relying on external models or additional data.
Image-of-Thought Prompting for Visual Reasoning Refinement in Multimodal Large Language Models
May 22, 2024



Recent advancements in Chain-of-Thought (CoT) and related rationale-based works have significantly improved the performance of Large Language Models (LLMs) in complex reasoning tasks. With the evolution of Multimodal Large Language Models (MLLMs), enhancing their capability to tackle complex multimodal reasoning problems is a crucial frontier. However, incorporating multimodal rationales in CoT has yet to be thoroughly investigated. We propose the Image-of-Thought (IoT) prompting method, which helps MLLMs to extract visual rationales step-by-step. Specifically, IoT prompting can automatically design critical visual information extraction operations based on the input images and questions. Each step of visual information refinement identifies specific visual rationales that support answers to complex visual reasoning questions. Beyond the textual CoT, IoT simultaneously utilizes visual and textual rationales to help MLLMs understand complex multimodal information. IoT prompting has improved zero-shot visual reasoning performance across various visual understanding tasks in different MLLMs. Moreover, the step-by-step visual feature explanations generated by IoT prompting elucidate the visual reasoning process, aiding in analyzing the cognitive processes of large multimodal models
GLoRE: Evaluating Logical Reasoning of Large Language Models
Oct 13, 2023



Recently, large language models (LLMs), including notable models such as GPT-4 and burgeoning community models, have showcased significant general language understanding abilities. However, there has been a scarcity of attempts to assess the logical reasoning capacities of these LLMs, an essential facet of natural language understanding. To encourage further investigation in this area, we introduce GLoRE, a meticulously assembled General Logical Reasoning Evaluation benchmark comprised of 12 datasets that span three different types of tasks. Our experimental results show that compared to the performance of human and supervised fine-tuning, the logical reasoning capabilities of open LLM models necessitate additional improvement; ChatGPT and GPT-4 show a strong capability of logical reasoning, with GPT-4 surpassing ChatGPT by a large margin. We propose a self-consistency probing method to enhance the accuracy of ChatGPT and a fine-tuned method to boost the performance of an open LLM. We release the datasets and evaluation programs to facilitate future research.
LogiCoT: Logical Chain-of-Thought Instruction-Tuning Data Collection with GPT-4
May 20, 2023Generative Pre-trained Transformer 4 (GPT-4) demonstrates impressive chain-of-thought reasoning ability. Recent work on self-instruction tuning, such as Alpaca, has focused on enhancing the general proficiency of models. These instructions enable the model to achieve performance comparable to GPT-3.5 on general tasks like open-domain text generation and paraphrasing. However, they fall short of helping the model handle complex reasoning tasks. To bridge the gap, this paper presents LogiCoT, a new instruction-tuning dataset for Logical Chain-of-Thought reasoning with GPT-4. We elaborate on the process of harvesting instructions for prompting GPT-4 to generate chain-of-thought rationales. LogiCoT serves as an instruction set for teaching models of logical reasoning and elicits general reasoning skills.
Evaluating the Logical Reasoning Ability of ChatGPT and GPT-4
Apr 20, 2023



Harnessing logical reasoning ability is a comprehensive natural language understanding endeavor. With the release of Generative Pretrained Transformer 4 (GPT-4), highlighted as "advanced" at reasoning tasks, we are eager to learn the GPT-4 performance on various logical reasoning tasks. This report analyses multiple logical reasoning datasets, with popular benchmarks like LogiQA and ReClor, and newly-released datasets like AR-LSAT. We test the multi-choice reading comprehension and natural language inference tasks with benchmarks requiring logical reasoning. We further construct a logical reasoning out-of-distribution dataset to investigate the robustness of ChatGPT and GPT-4. We also make a performance comparison between ChatGPT and GPT-4. Experiment results show that ChatGPT performs significantly better than the RoBERTa fine-tuning method on most logical reasoning benchmarks. With early access to the GPT-4 API we are able to conduct intense experiments on the GPT-4 model. The results show GPT-4 yields even higher performance on most logical reasoning datasets. Among benchmarks, ChatGPT and GPT-4 do relatively well on well-known datasets like LogiQA and ReClor. However, the performance drops significantly when handling newly released and out-of-distribution datasets. Logical reasoning remains challenging for ChatGPT and GPT-4, especially on out-of-distribution and natural language inference datasets. We release the prompt-style logical reasoning datasets as a benchmark suite and name it LogiEval.