 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Behavioral Performance to Internal Competence: Interpreting Vision-Language Models with VLM-Lens
Oct 02, 2025We introduce VLM-Lens, a toolkit designed to enable systematic benchmarking, analysis, and interpretation of vision-language models (VLMs) by supporting the extraction of intermediate outputs from any layer during the forward pass of open-source VLMs. VLM-Lens provides a unified, YAML-configurable interface that abstracts away model-specific complexities and supports user-friendly operation across diverse VLMs. It currently supports 16 state-of-the-art base VLMs and their over 30 variants, and is extensible to accommodate new models without changing the core logic. The toolkit integrates easily with various interpretability and analysis methods. We demonstrate its usage with two simple analytical experiments, revealing systematic differences in the hidden representations of VLMs across layers and target concepts. VLM-Lens is released as an open-sourced project to accelerate community efforts in understanding and improving VLMs.
Logical Reasoning in Large Language Models: A Survey
Feb 13, 2025
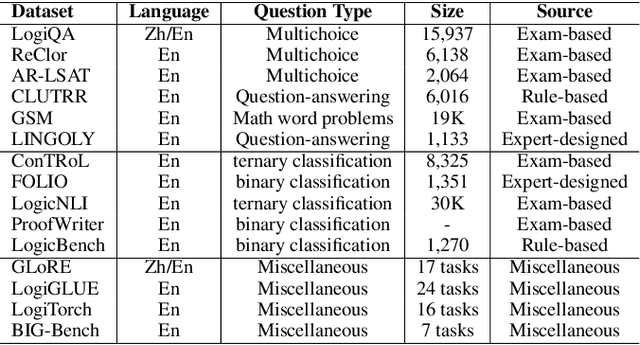

With the emergence of advanced reasoning models like OpenAI o3 and DeepSeek-R1, large language models (LLMs) have demonstrated remarkable reasoning capabilities. However, their ability to perform rigorous logical reasoning remains an open question. This survey synthesizes recent advancements in logical reasoning within LLMs, a critical area of AI research. It outlines the scope of logical reasoning in LLMs, its theoretical foundations, and the benchmarks used to evaluate reasoning proficiency. We analyze existing capabilities across different reasoning paradigms - deductive, inductive, abductive, and analogical - and assess strategies to enhance reasoning performance, including data-centric tuning, reinforcement learning, decoding strategies, and neuro-symbolic approaches. The review concludes with future directions, emphasizing the need for further exploration to strengthen logical reasoning in AI systems.
NovelQA: A Benchmark for Long-Range Novel Question Answering
Mar 18, 2024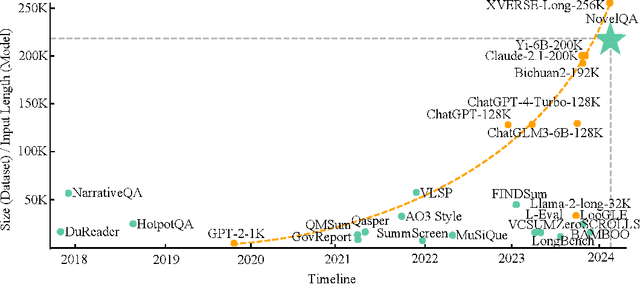
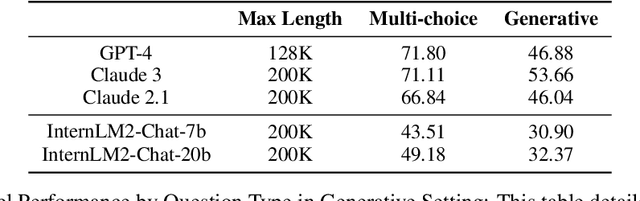

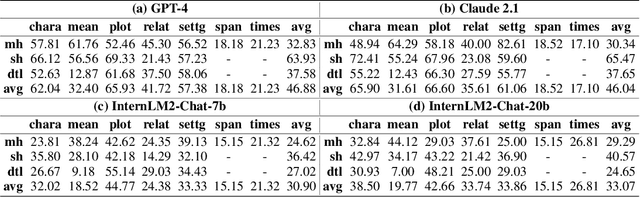
The rapid advancement of Large Language Models (LLMs) has introduced a new frontier in natural language processing, particularly in understanding and processing long-context information. However, the evaluation of these models' long-context abilities remains a challenge due to the limitations of current benchmarks. To address this gap, we introduce NovelQA, a benchmark specifically designed to test the capabilities of LLMs with extended texts. Constructed from English novels, NovelQA offers a unique blend of complexity, length, and narrative coherence, making it an ideal tool for assessing deep textual understanding in LLMs. This paper presents the design and construction of NovelQA, highlighting its manual annotation, and diverse question types. Our evaluation of Long-context LLMs on NovelQA reveals significant insights into the models' performance, particularly emphasizing the challenges they face with multi-hop reasoning, detail-oriented questions, and extremely long input with more than 100,000 tokens. The results underscore the necessity for further advancements in LLMs to improve their long-context comprehension and computational literary studies.
GLoRE: Evaluating Logical Reasoning of Large Language Models
Oct 13, 2023



Recently, large language models (LLMs), including notable models such as GPT-4 and burgeoning community models, have showcased significant general language understanding abilities. However, there has been a scarcity of attempts to assess the logical reasoning capacities of these LLMs, an essential facet of natural language understanding. To encourage further investigation in this area, we introduce GLoRE, a meticulously assembled General Logical Reasoning Evaluation benchmark comprised of 12 datasets that span three different types of tasks. Our experimental results show that compared to the performance of human and supervised fine-tuning, the logical reasoning capabilities of open LLM models necessitate additional improvement; ChatGPT and GPT-4 show a strong capability of logical reasoning, with GPT-4 surpassing ChatGPT by a large margin. We propose a self-consistency probing method to enhance the accuracy of ChatGPT and a fine-tuned method to boost the performance of an open LLM. We release the datasets and evaluation programs to facilitate future research.
Evaluating the Logical Reasoning Ability of ChatGPT and GPT-4
Apr 20, 2023



Harnessing logical reasoning ability is a comprehensive natural language understanding endeavor. With the release of Generative Pretrained Transformer 4 (GPT-4), highlighted as "advanced" at reasoning tasks, we are eager to learn the GPT-4 performance on various logical reasoning tasks. This report analyses multiple logical reasoning datasets, with popular benchmarks like LogiQA and ReClor, and newly-released datasets like AR-LSAT. We test the multi-choice reading comprehension and natural language inference tasks with benchmarks requiring logical reasoning. We further construct a logical reasoning out-of-distribution dataset to investigate the robustness of ChatGPT and GPT-4. We also make a performance comparison between ChatGPT and GPT-4. Experiment results show that ChatGPT performs significantly better than the RoBERTa fine-tuning method on most logical reasoning benchmarks. With early access to the GPT-4 API we are able to conduct intense experiments on the GPT-4 model. The results show GPT-4 yields even higher performance on most logical reasoning datasets. Among benchmarks, ChatGPT and GPT-4 do relatively well on well-known datasets like LogiQA and ReClor. However, the performance drops significantly when handling newly released and out-of-distribution datasets. Logical reasoning remains challenging for ChatGPT and GPT-4, especially on out-of-distribution and natural language inference datasets. We release the prompt-style logical reasoning datasets as a benchmark suite and name it LogiEval.