 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimizing Mismatch Risk: A Prototype-Based Routing Framework for Zero-shot LLM-generated Text Detection
Feb 01, 2026Zero-shot methods detect LLM-generated text by computing statistical signatures using a surrogate model. Existing approaches typically employ a fixed surrogate for all inputs regardless of the unknown source. We systematically examine this design and find that detection performance varies substantially depending on surrogate-source alignment. We observe that while no single surrogate achieves optimal performance universally, a well-matched surrogate typically exists within a diverse pool for any given input. This finding transforms robust detection into a routing problem: selecting the most appropriate surrogate for each input. We propose DetectRouter, a prototype-based framework that learns text-detector affinity through two-stage training. The first stage constructs discriminative prototypes from white-box models; the second generalizes to black-box sources by aligning geometric distances with observed detection scores. Experiments on EvoBench and MAGE benchmarks demonstrate consistent improvements across multiple detection criteria and model families.
When AI Settles Down: Late-Stage Stability as a Signature of AI-Generated Text Detection
Jan 08, 2026Zero-shot detection methods for AI-generated text typically aggregate token-level statistics across entire sequences, overlooking the temporal dynamics inherent to autoregressive generation. We analyze over 120k text samples and reveal Late-Stage Volatility Decay: AI-generated text exhibits rapidly stabilizing log probability fluctuations as generation progresses, while human writing maintains higher variability throughout. This divergence peaks in the second half of sequences, where AI-generated text shows 24--32\% lower volatility. Based on this finding, we propose two simple features: Derivative Dispersion and Local Volatility, which computed exclusively from late-stage statistics. Without perturbation sampling or additional model access, our method achieves state-of-the-art performance on EvoBench and MAGE benchmarks and demonstrates strong complementarity with existing global methods.
Direct Value Optimization: Improving Chain-of-Thought Reasoning in LLMs with Refined Values
Feb 19, 2025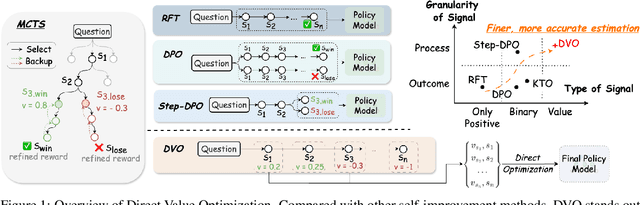
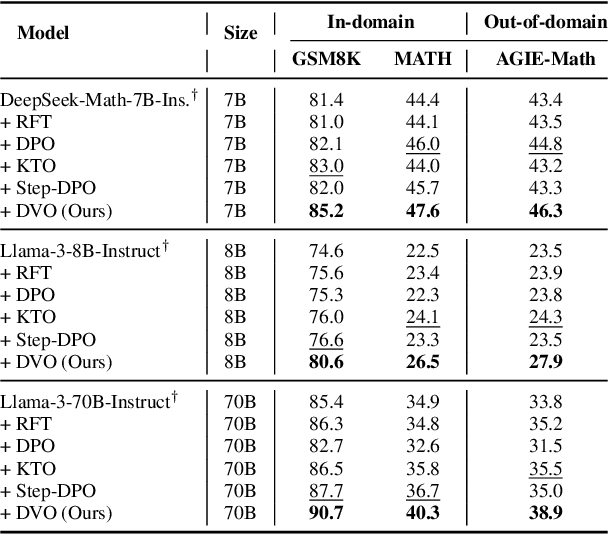
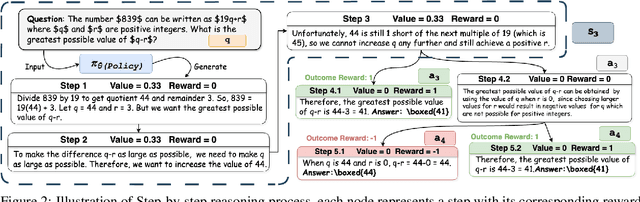
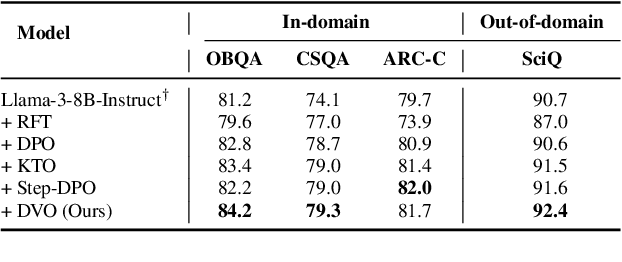
We introduce Direct Value Optimization (DVO), an innovative reinforcement learning framework for enhancing large language models in complex reasoning tasks. Unlike traditional methods relying on preference labels, DVO utilizes value signals at individual reasoning steps, optimizing models via a mean squared error loss. The key benefit of DVO lies in its fine-grained supervision, circumventing the need for labor-intensive human annotations. Target values within the DVO are estimated using either Monte Carlo Tree Search or an outcome value model. Our empirical analysis on both mathematical and commonsense reasoning tasks shows that DVO consistently outperforms existing offline preference optimization techniques, even with fewer training steps. These findings underscore the importance of value signals in advancing reasoning capabilities and highlight DVO as a superior methodology under scenarios lacking explicit human preference information.
Glimpse: Enabling White-Box Methods to Use Proprietary Models for Zero-Shot LLM-Generated Text Detection
Dec 16, 2024Advanced large language models (LLMs) can generate text almost indistinguishable from human-written text, highlighting the importance of LLM-generated text detection. However, current zero-shot techniques face challenges as white-box methods are restricted to use weaker open-source LLMs, and black-box methods are limited by partial observation from stronger proprietary LLMs. It seems impossible to enable white-box methods to use proprietary models because API-level access to the models neither provides full predictive distributions nor inner embeddings. To traverse the divide, we propose Glimpse, a probability distribution estimation approach, predicting the full distributions from partial observations. Despite the simplicity of Glimpse, we successfully extend white-box methods like Entropy, Rank, Log-Rank, and Fast-DetectGPT to latest proprietary models. Experiments show that Glimpse with Fast-DetectGPT and GPT-3.5 achieves an average AUROC of about 0.95 in five latest source models, improving the score by 51% relative to the remaining space of the open source baseline (Table 1). It demonstrates that the latest LLMs can effectively detect their own outputs, suggesting that advanced LLMs may be the best shield against themselves.
CycleResearcher: Improving Automated Research via Automated Review
Oct 28, 2024The automation of scientific discovery has been a long-standing goal within the research community, driven by the potential to accelerate knowledge creation. While significant progress has been made using commercial large language models (LLMs) as research assistants or idea generators, the possibility of automating the entire research process with open-source LLMs remains largely unexplored. This paper explores the feasibility of using open-source post-trained LLMs as autonomous agents capable of performing the full cycle of automated research and review, from literature review and manuscript preparation to peer review and paper revision. Our iterative preference training framework consists of CycleResearcher, which conducts research tasks, and CycleReviewer, which simulates the peer review process, providing iterative feedback via reinforcement learning. To train these models, we develop two new datasets, Review-5k and Research-14k, reflecting real-world machine learning research and peer review dynamics. Our results demonstrate that CycleReviewer achieves a 26.89\% improvement in mean absolute error (MAE) over individual human reviewers in predicting paper scores, indicating that LLMs can surpass expert-level performance in research evaluation. In research, the papers generated by the CycleResearcher model achieved a score of 5.36 in simulated peer reviews, surpassing the preprint level of 5.24 from human experts and approaching the accepted paper level of 5.69. This work represents a significant step toward fully automated scientific inquiry, providing ethical safeguards and advancing AI-driven research capabilities. The code, dataset and model weight are released at \url{http://github/minjun-zhu/Researcher}.
NovelQA: A Benchmark for Long-Range Novel Question Answering
Mar 18, 2024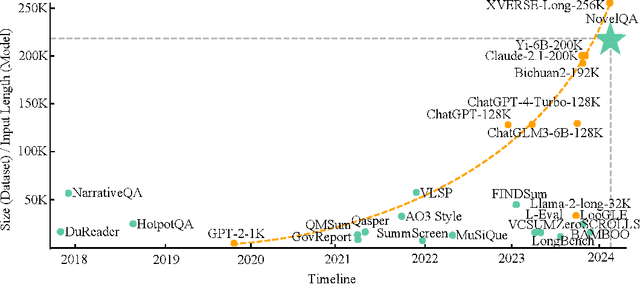
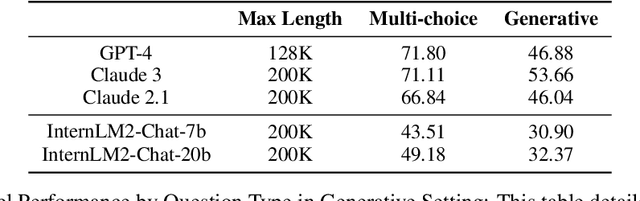

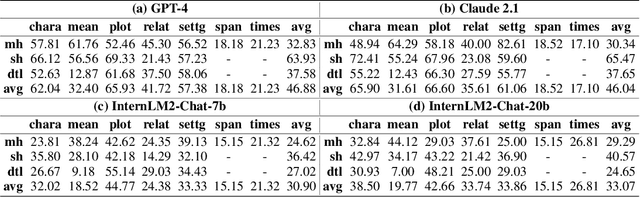
The rapid advancement of Large Language Models (LLMs) has introduced a new frontier in natural language processing, particularly in understanding and processing long-context information. However, the evaluation of these models' long-context abilities remains a challenge due to the limitations of current benchmarks. To address this gap, we introduce NovelQA, a benchmark specifically designed to test the capabilities of LLMs with extended texts. Constructed from English novels, NovelQA offers a unique blend of complexity, length, and narrative coherence, making it an ideal tool for assessing deep textual understanding in LLMs. This paper presents the design and construction of NovelQA, highlighting its manual annotation, and diverse question types. Our evaluation of Long-context LLMs on NovelQA reveals significant insights into the models' performance, particularly emphasizing the challenges they face with multi-hop reasoning, detail-oriented questions, and extremely long input with more than 100,000 tokens. The results underscore the necessity for further advancements in LLMs to improve their long-context comprehension and computational literary studies.
LLMs with Chain-of-Thought Are Non-Causal Reasoners
Feb 25, 2024This paper explores the role of the Chain of Thought (CoT) in Large Language Models (LLMs) reasoning. Despite its potential to improve task performance, our analysis reveals a surprising frequency of correct answers following incorrect CoTs and vice versa. We employ causal analysis to assess the cause-effect relationship between CoTs/instructions and answers in LLMs, uncovering the Structural Causal Model (SCM) that LLMs approximate. By comparing the implied SCM with that of human reasoning, we highlight discrepancies between LLM and human reasoning processes. We further examine the factors influencing the causal structure of the implied SCM, revealing that in-context learning, supervised fine-tuning, and reinforcement learning on human feedback significantly impact the causal relations. We release the code and results at https://github.com/StevenZHB/CoT_Causal_Analysis.
Supervised Knowledge Makes Large Language Models Better In-context Learners
Dec 26, 2023



Large Language Models (LLMs) exhibit emerging in-context learning abilities through prompt engineering. The recent progress in large-scale generative models has further expanded their use in real-world language applications. However, the critical challenge of improving the generalizability and factuality of LLMs in natural language understanding and question answering remains under-explored. While previous in-context learning research has focused on enhancing models to adhere to users' specific instructions and quality expectations, and to avoid undesired outputs, little to no work has explored the use of task-Specific fine-tuned Language Models (SLMs) to improve LLMs' in-context learning during the inference stage. Our primary contribution is the establishment of a simple yet effective framework that enhances the reliability of LLMs as it: 1) generalizes out-of-distribution data, 2) elucidates how LLMs benefit from discriminative models, and 3) minimizes hallucinations in generative tasks. Using our proposed plug-in method, enhanced versions of Llama 2 and ChatGPT surpass their original versions regarding generalizability and factuality. We offer a comprehensive suite of resources, including 16 curated datasets, prompts, model checkpoints, and LLM outputs across 9 distinct tasks. Our empirical analysis sheds light on the advantages of incorporating discriminative models into LLMs and highlights the potential of our methodology in fostering more reliable LLMs.
Fast-DetectGPT: Efficient Zero-Shot Detection of Machine-Generated Text via Conditional Probability Curvature
Oct 08, 2023
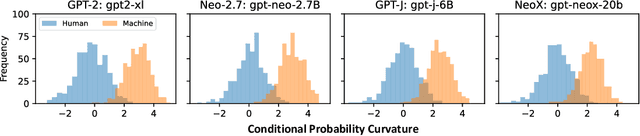
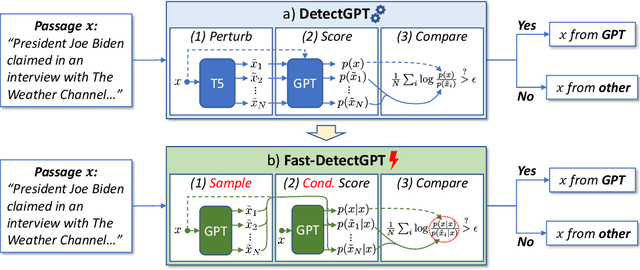
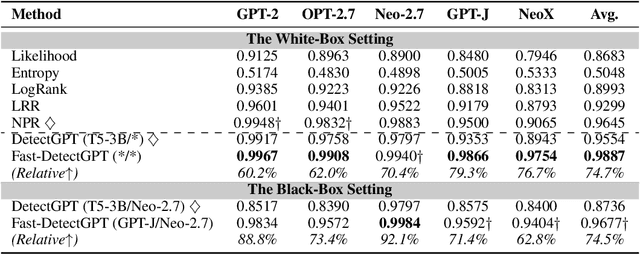
Large language models (LLMs) have shown the ability to produce fluent and cogent content, presenting both productivity opportunities and societal risks. To build trustworthy AI systems, it is imperative to distinguish between machine-generated and human-authored content. The leading zero-shot detector, DetectGPT, showcases commendable performance but is marred by its intensive computational costs. In this paper, we introduce the concept of conditional probability curvature to elucidate discrepancies in word choices between LLMs and humans within a given context. Utilizing this curvature as a foundational metric, we present Fast-DetectGPT, an optimized zero-shot detector, which substitutes DetectGPT's perturbation step with a more efficient sampling step. Our evaluations on various datasets, source models, and test conditions indicate that Fast-DetectGPT not only outperforms DetectGPT in both the white-box and black-box settings but also accelerates the detection process by a factor of 340, as detailed in Table 1.
Non-Autoregressive Document-Level Machine Translation (NA-DMT): Exploring Effective Approaches, Challenges, and Opportunities
May 22, 2023
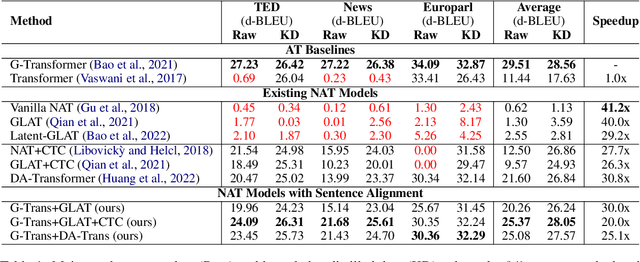
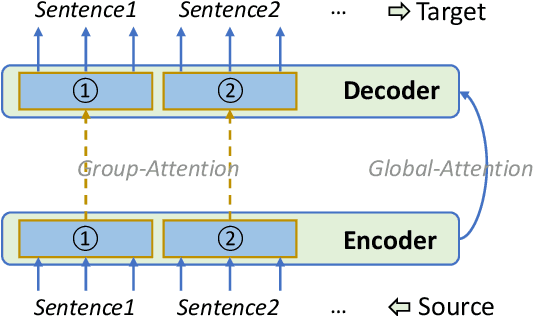

Non-autoregressive translation (NAT) models have been extensively investigated within the context of sentence-level machine translation (MT) tasks, demonstrating comparable quality and superior translation speed when contrasted with autoregressive translation (AT) models. However, the challenges associated with multi-modality and alignment issues within NAT models become more prominent when increasing input and output length, leading to unexpected complications in document-level MT. In this paper, we conduct a comprehensive examination of typical NAT models in the context of document-level MT tasks. Experiments reveal that, although NAT models significantly accelerate text generation on documents, they do not perform as effectively as on sentences. To bridge this performance gap, we introduce a novel design that underscores the importance of sentence-level alignment for non-autoregressive document-level machine translation (NA-DMT). This innovation substantially reduces the performance discrepancy. However, it is worth noting that NA-DMT models are still far from perfect and may necessitate additional research to fully optimize their performance. We delve into the related opportunities and challenges and provide our code at https://github.com/baoguangsheng/nat-on-doc to stimulate further research in this field.