 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlimpse: Enabling White-Box Methods to Use Proprietary Models for Zero-Shot LLM-Generated Text Detection
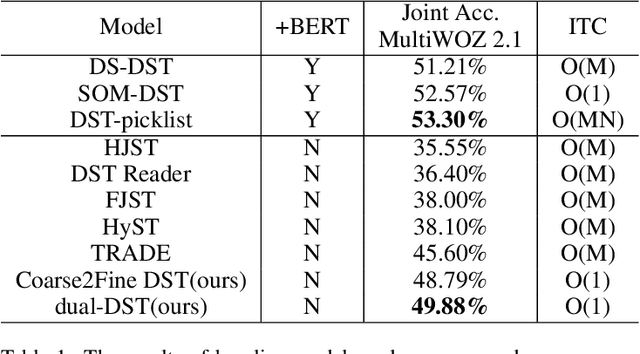
Dec 16, 2024Advanced large language models (LLMs) can generate text almost indistinguishable from human-written text, highlighting the importance of LLM-generated text detection. However, current zero-shot techniques face challenges as white-box methods are restricted to use weaker open-source LLMs, and black-box methods are limited by partial observation from stronger proprietary LLMs. It seems impossible to enable white-box methods to use proprietary models because API-level access to the models neither provides full predictive distributions nor inner embeddings. To traverse the divide, we propose Glimpse, a probability distribution estimation approach, predicting the full distributions from partial observations. Despite the simplicity of Glimpse, we successfully extend white-box methods like Entropy, Rank, Log-Rank, and Fast-DetectGPT to latest proprietary models. Experiments show that Glimpse with Fast-DetectGPT and GPT-3.5 achieves an average AUROC of about 0.95 in five latest source models, improving the score by 51% relative to the remaining space of the open source baseline (Table 1). It demonstrates that the latest LLMs can effectively detect their own outputs, suggesting that advanced LLMs may be the best shield against themselves.
Fast-DetectGPT: Efficient Zero-Shot Detection of Machine-Generated Text via Conditional Probability Curvature
Oct 08, 2023
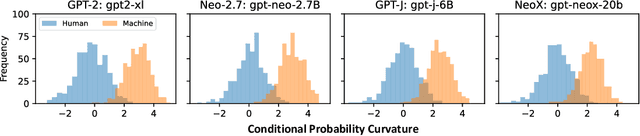
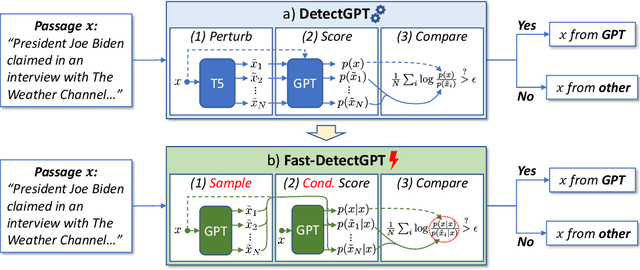
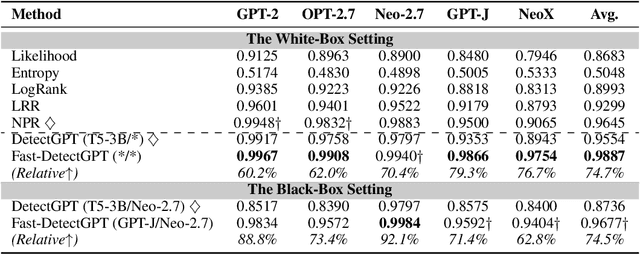
Large language models (LLMs) have shown the ability to produce fluent and cogent content, presenting both productivity opportunities and societal risks. To build trustworthy AI systems, it is imperative to distinguish between machine-generated and human-authored content. The leading zero-shot detector, DetectGPT, showcases commendable performance but is marred by its intensive computational costs. In this paper, we introduce the concept of conditional probability curvature to elucidate discrepancies in word choices between LLMs and humans within a given context. Utilizing this curvature as a foundational metric, we present Fast-DetectGPT, an optimized zero-shot detector, which substitutes DetectGPT's perturbation step with a more efficient sampling step. Our evaluations on various datasets, source models, and test conditions indicate that Fast-DetectGPT not only outperforms DetectGPT in both the white-box and black-box settings but also accelerates the detection process by a factor of 340, as detailed in Table 1.
ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
Dec 23, 2021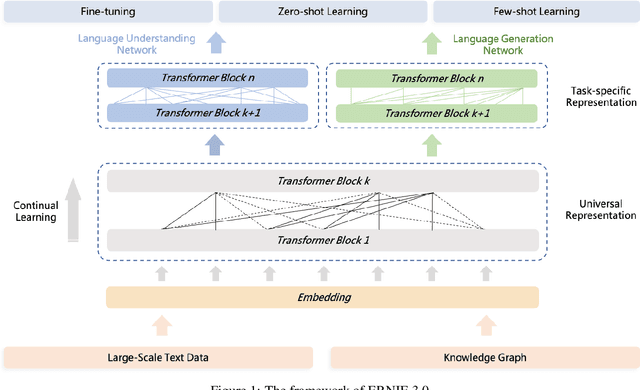
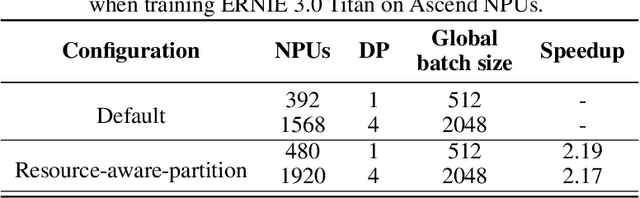
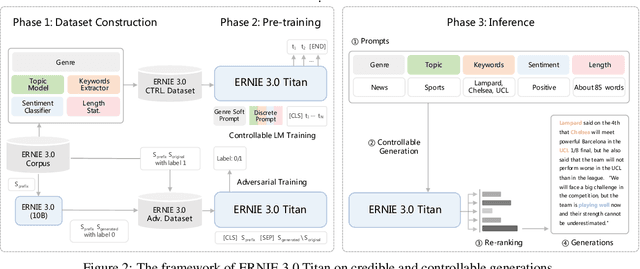
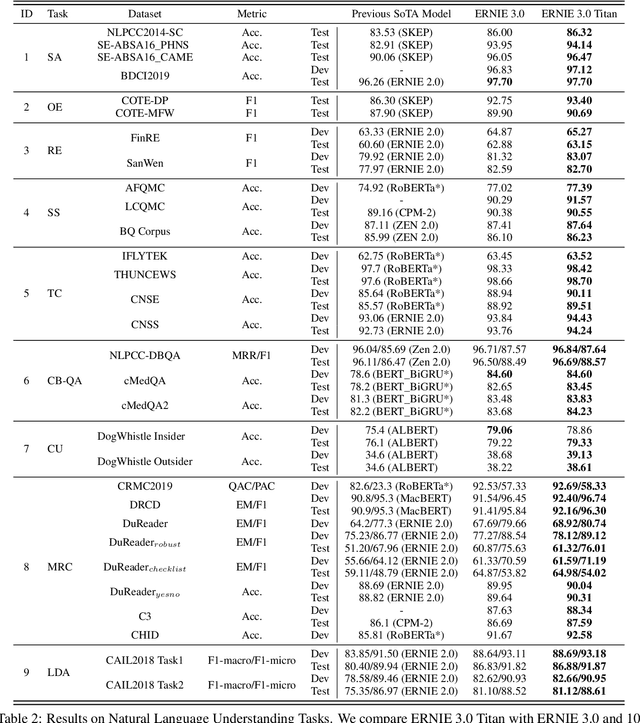
Pre-trained language models have achieved state-of-the-art results in various Natural Language Processing (NLP) tasks. GPT-3 has shown that scaling up pre-trained language models can further exploit their enormous potential. A unified framework named ERNIE 3.0 was recently proposed for pre-training large-scale knowledge enhanced models and trained a model with 10 billion parameters. ERNIE 3.0 outperformed the state-of-the-art models on various NLP tasks. In order to explore the performance of scaling up ERNIE 3.0, we train a hundred-billion-parameter model called ERNIE 3.0 Titan with up to 260 billion parameters on the PaddlePaddle platform. Furthermore, we design a self-supervised adversarial loss and a controllable language modeling loss to make ERNIE 3.0 Titan generate credible and controllable texts. To reduce the computation overhead and carbon emission, we propose an online distillation framework for ERNIE 3.0 Titan, where the teacher model will teach students and train itself simultaneously. ERNIE 3.0 Titan is the largest Chinese dense pre-trained model so far. Empirical results show that the ERNIE 3.0 Titan outperforms the state-of-the-art models on 68 NLP datasets.
ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
Jul 05, 2021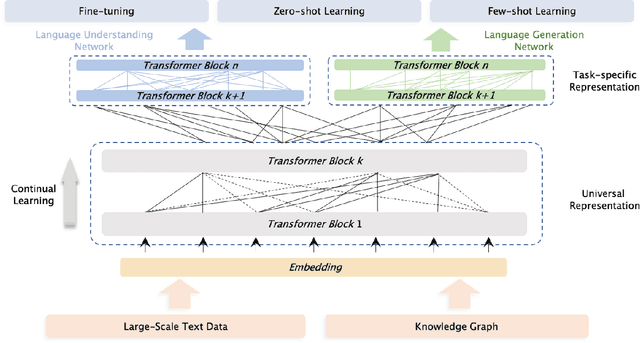

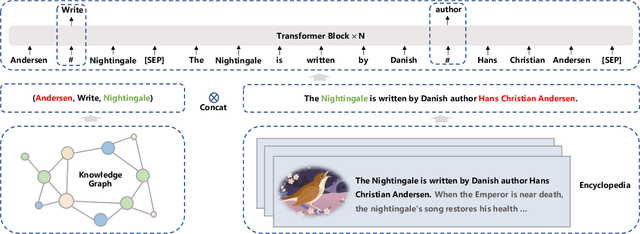
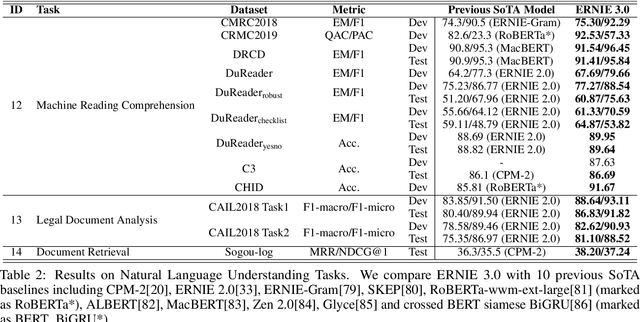
Pre-trained models have achieved state-of-the-art results in various Natural Language Processing (NLP) tasks. Recent works such as T5 and GPT-3 have shown that scaling up pre-trained language models can improve their generalization abilities. Particularly, the GPT-3 model with 175 billion parameters shows its strong task-agnostic zero-shot/few-shot learning capabilities. Despite their success, these large-scale models are trained on plain texts without introducing knowledge such as linguistic knowledge and world knowledge. In addition, most large-scale models are trained in an auto-regressive way. As a result, this kind of traditional fine-tuning approach demonstrates relatively weak performance when solving downstream language understanding tasks. In order to solve the above problems, we propose a unified framework named ERNIE 3.0 for pre-training large-scale knowledge enhanced models. It fuses auto-regressive network and auto-encoding network, so that the trained model can be easily tailored for both natural language understanding and generation tasks with zero-shot learning, few-shot learning or fine-tuning. We trained the model with 10 billion parameters on a 4TB corpus consisting of plain texts and a large-scale knowledge graph. Empirical results show that the model outperforms the state-of-the-art models on 54 Chinese NLP tasks, and its English version achieves the first place on the SuperGLUE benchmark (July 3, 2021), surpassing the human performance by +0.8% (90.6% vs. 89.8%).
LGESQL: Line Graph Enhanced Text-to-SQL Model with Mixed Local and Non-Local Relations
Jun 10, 2021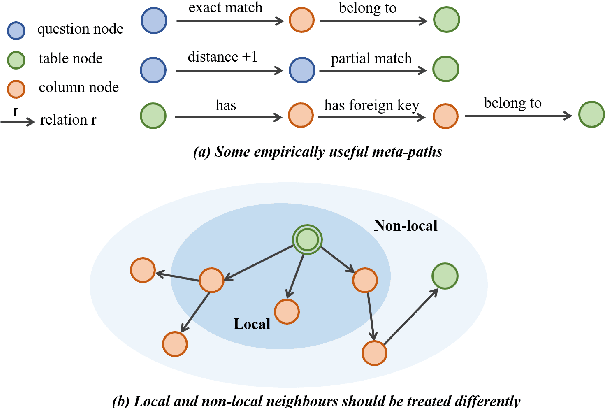
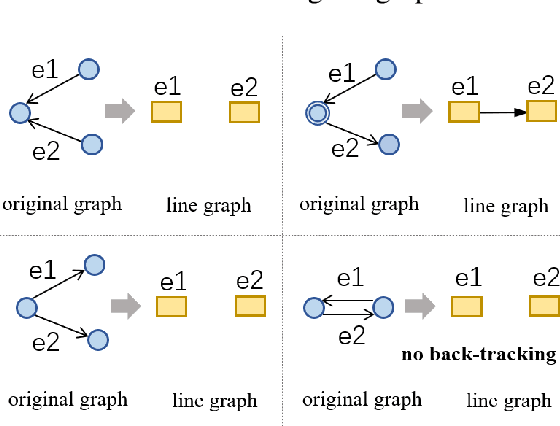
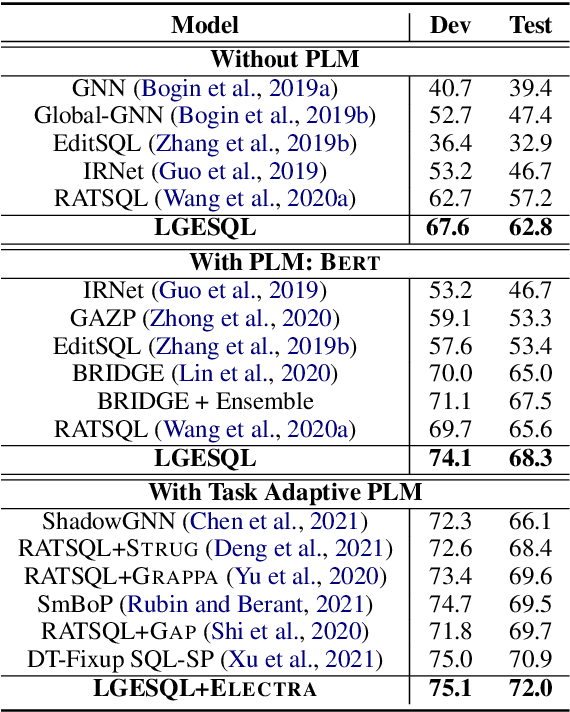
This work aims to tackle the challenging heterogeneous graph encoding problem in the text-to-SQL task. Previous methods are typically node-centric and merely utilize different weight matrices to parameterize edge types, which 1) ignore the rich semantics embedded in the topological structure of edges, and 2) fail to distinguish local and non-local relations for each node. To this end, we propose a Line Graph Enhanced Text-to-SQL (LGESQL) model to mine the underlying relational features without constructing meta-paths. By virtue of the line graph, messages propagate more efficiently through not only connections between nodes, but also the topology of directed edges. Furthermore, both local and non-local relations are integrated distinctively during the graph iteration. We also design an auxiliary task called graph pruning to improve the discriminative capability of the encoder. Our framework achieves state-of-the-art results (62.8% with Glove, 72.0% with Electra) on the cross-domain text-to-SQL benchmark Spider at the time of writing.
ShadowGNN: Graph Projection Neural Network for Text-to-SQL Parser
Apr 14, 2021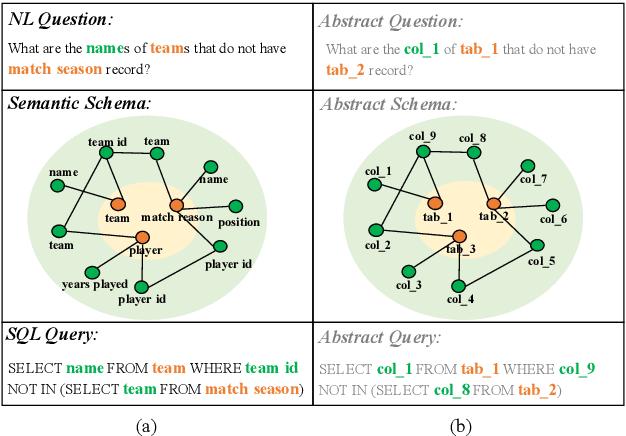
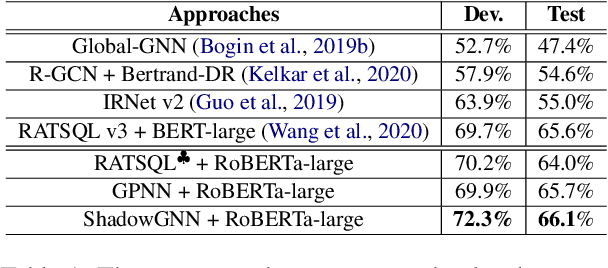
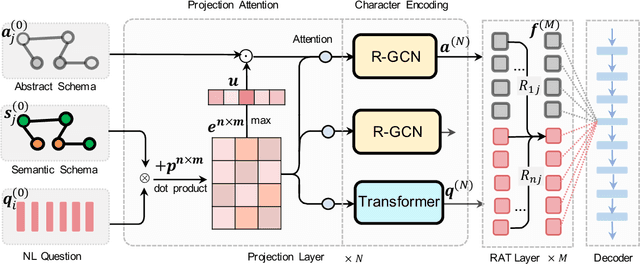

Given a database schema, Text-to-SQL aims to translate a natural language question into the corresponding SQL query. Under the setup of cross-domain, traditional semantic parsing models struggle to adapt to unseen database schemas. To improve the model generalization capability for rare and unseen schemas, we propose a new architecture, ShadowGNN, which processes schemas at abstract and semantic levels. By ignoring names of semantic items in databases, abstract schemas are exploited in a well-designed graph projection neural network to obtain delexicalized representation of question and schema. Based on the domain-independent representations, a relation-aware transformer is utilized to further extract logical linking between question and schema. Finally, a SQL decoder with context-free grammar is applied. On the challenging Text-to-SQL benchmark Spider, empirical results show that ShadowGNN outperforms state-of-the-art models. When the annotated data is extremely limited (only 10\% training set), ShadowGNN gets over absolute 5\% performance gain, which shows its powerful generalization ability. Our implementation will be open-sourced at \url{https://github.com/WowCZ/shadowgnn}.
CREDIT: Coarse-to-Fine Sequence Generation for Dialogue State Tracking
Sep 22, 2020

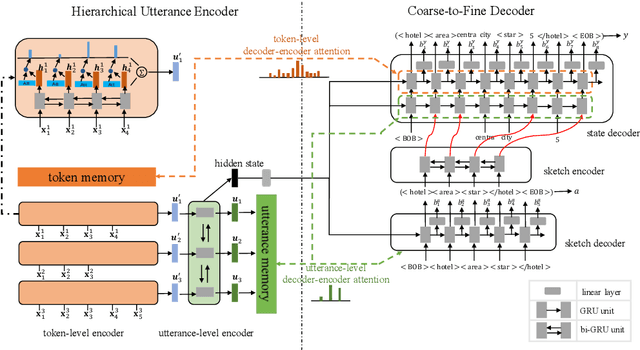
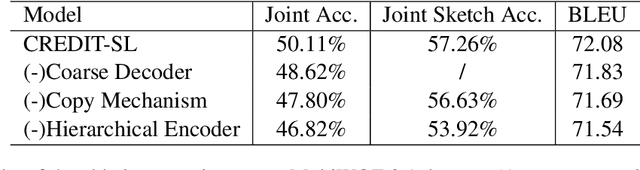
In dialogue systems, a dialogue state tracker aims to accurately find a compact representation of the current dialogue status, based on the entire dialogue history. While previous approaches often define dialogue states as a combination of separate triples ({\em domain-slot-value}), in this paper, we employ a structured state representation and cast dialogue state tracking as a sequence generation problem. Based on this new formulation, we propose a {\bf C}oa{\bf R}s{\bf E}-to-fine {\bf DI}alogue state {\bf T}racking ({\bf CREDIT}) approach. Taking advantage of the structured state representation, which is a marked language sequence, we can further fine-tune the pre-trained model (by supervised learning) by optimizing natural language metrics with the policy gradient method. Like all generative state tracking methods, CREDIT does not rely on pre-defined dialogue ontology enumerating all possible slot values. Experiments demonstrate our tracker achieves encouraging joint goal accuracy for the five domains in MultiWOZ 2.0 and MultiWOZ 2.1 datasets.
Dual Learning for Dialogue State Tracking
Sep 22, 2020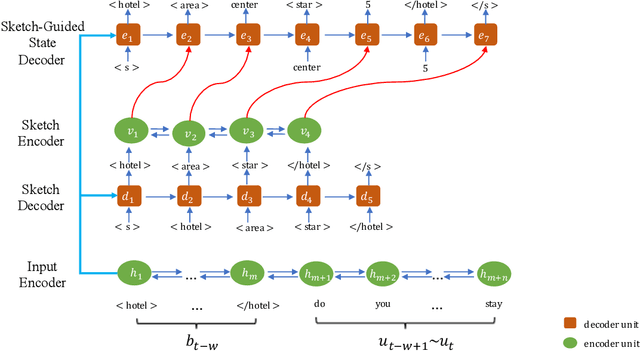
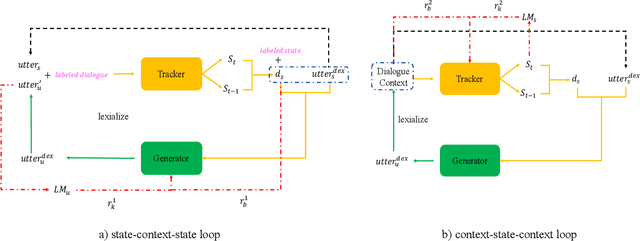
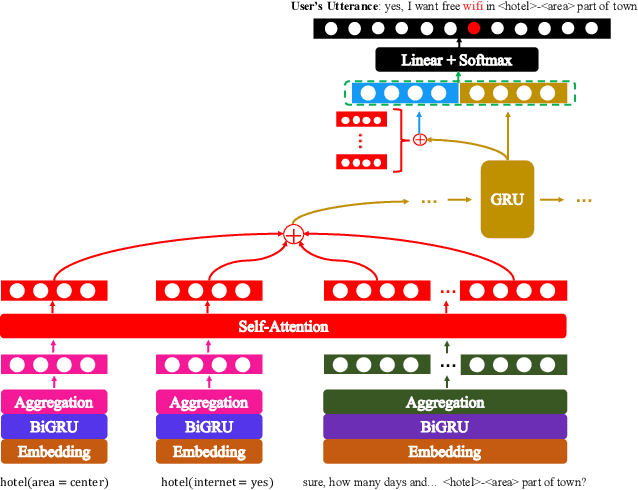
In task-oriented multi-turn dialogue systems, dialogue state refers to a compact representation of the user goal in the context of dialogue history. Dialogue state tracking (DST) is to estimate the dialogue state at each turn. Due to the dependency on complicated dialogue history contexts, DST data annotation is more expensive than single-sentence language understanding, which makes the task more challenging. In this work, we formulate DST as a sequence generation problem and propose a novel dual-learning framework to make full use of unlabeled data. In the dual-learning framework, there are two agents: the primal tracker agent (utterance-to-state generator) and the dual utterance generator agent (state-to-utterance genera-tor). Compared with traditional supervised learning framework, dual learning can iteratively update both agents through the reconstruction error and reward signal respectively without labeled data. Reward sparsity problem is hard to solve in previous DST methods. In this work, the reformulation of DST as a sequence generation model effectively alleviates this problem. We call this primal tracker agent dual-DST. Experimental results on MultiWOZ2.1 dataset show that the proposed dual-DST works very well, especially when labelled data is limited. It achieves comparable performance to the system where labeled data is fully used.
Unsupervised Dual Paraphrasing for Two-stage Semantic Parsing
May 27, 2020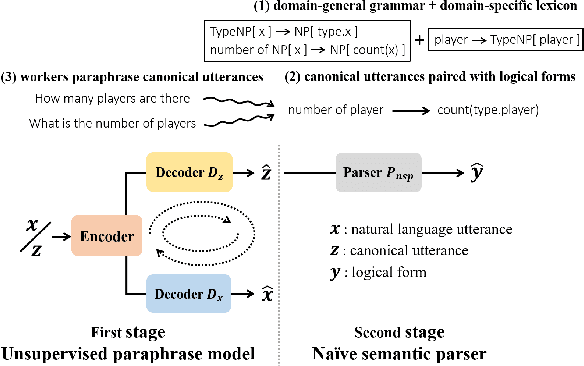


One daunting problem for semantic parsing is the scarcity of annotation. Aiming to reduce nontrivial human labor, we propose a two-stage semantic parsing framework, where the first stage utilizes an unsupervised paraphrase model to convert an unlabeled natural language utterance into the canonical utterance. The downstream naive semantic parser accepts the intermediate output and returns the target logical form. Furthermore, the entire training process is split into two phases: pre-training and cycle learning. Three tailored self-supervised tasks are introduced throughout training to activate the unsupervised paraphrase model. Experimental results on benchmarks Overnight and GeoGranno demonstrate that our framework is effective and compatible with supervised training.
Semi-Supervised Text Simplification with Back-Translation and Asymmetric Denoising Autoencoders
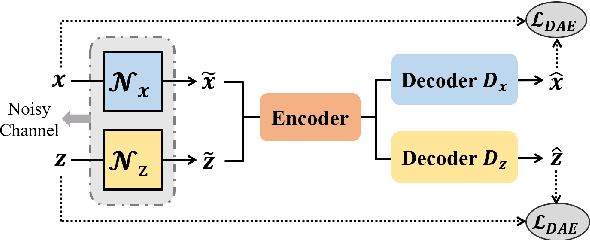
Apr 30, 2020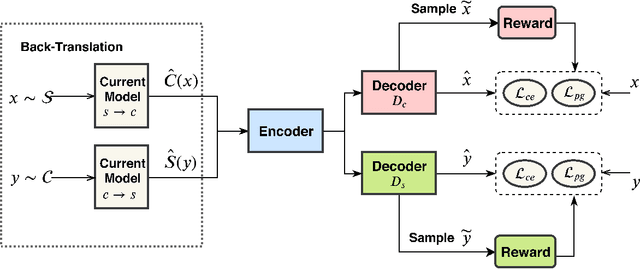


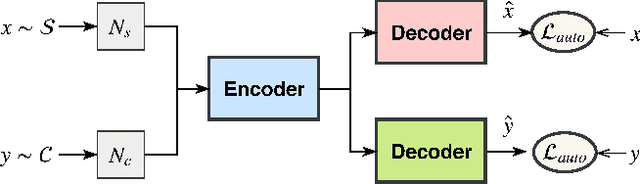
Text simplification (TS) rephrases long sentences into simplified variants while preserving inherent semantics. Traditional sequence-to-sequence models heavily rely on the quantity and quality of parallel sentences, which limits their applicability in different languages and domains. This work investigates how to leverage large amounts of unpaired corpora in TS task. We adopt the back-translation architecture in unsupervised machine translation (NMT), including denoising autoencoders for language modeling and automatic generation of parallel data by iterative back-translation. However, it is non-trivial to generate appropriate complex-simple pair if we directly treat the set of simple and complex corpora as two different languages, since the two types of sentences are quite similar and it is hard for the model to capture the characteristics in different types of sentences. To tackle this problem, we propose asymmetric denoising methods for sentences with separate complexity. When modeling simple and complex sentences with autoencoders, we introduce different types of noise into the training process. Such a method can significantly improve the simplification performance. Our model can be trained in both unsupervised and semi-supervised manner. Automatic and human evaluations show that our unsupervised model outperforms the previous systems, and with limited supervision, our model can perform competitively with multiple state-of-the-art simplification systems.