 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
ERNIE 3.0 Tiny: Frustratingly Simple Method to Improve Task-Agnostic Distillation Generalization
Jan 09, 2023



Task-agnostic knowledge distillation attempts to address the problem of deploying large pretrained language model in resource-constrained scenarios by compressing a large pretrained model called teacher into a smaller one called student such that the student can be directly finetuned on downstream tasks and retains comparable performance. However, we empirically find that there is a generalization gap between the student and the teacher in existing methods. In this work, we show that we can leverage multi-task learning in task-agnostic distillation to advance the generalization of the resulted student. In particular, we propose Multi-task Infused Task-agnostic Knowledge Distillation (MITKD). We first enhance the teacher by multi-task training it on multiple downstream tasks and then perform distillation to produce the student. Experimental results demonstrate that our method yields a student with much better generalization, significantly outperforms existing baselines, and establishes a new state-of-the-art result on in-domain, out-domain, and low-resource datasets in the setting of task-agnostic distillation. Moreover, our method even exceeds an 8x larger BERT$_{\text{Base}}$ on SQuAD and four GLUE tasks. In addition, by combining ERNIE 3.0, our method achieves state-of-the-art results on 10 Chinese datasets.
ERNIE-ViLG 2.0: Improving Text-to-Image Diffusion Model with Knowledge-Enhanced Mixture-of-Denoising-Experts
Oct 27, 2022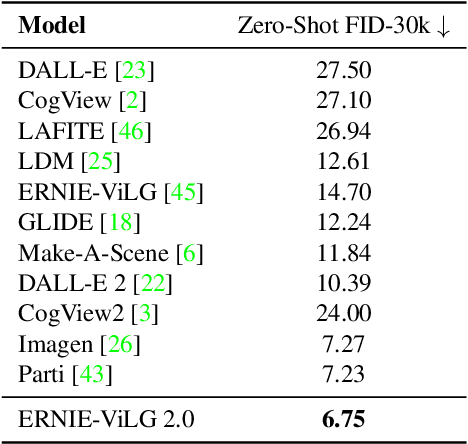
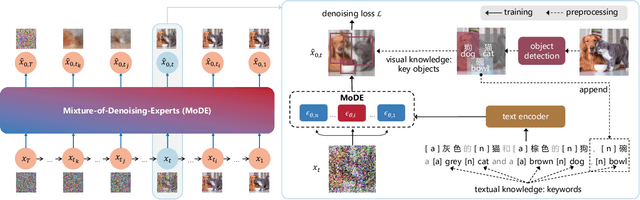
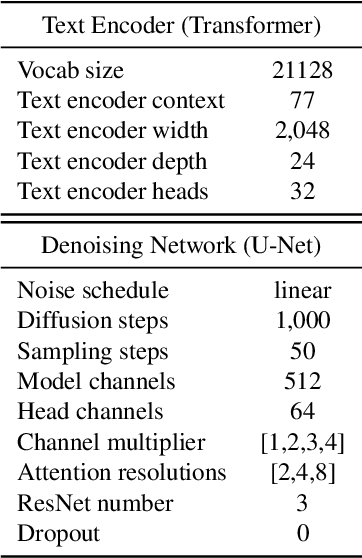
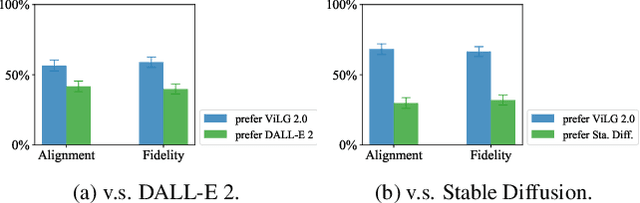
Recent progress in diffusion models has revolutionized the popular technology of text-to-image generation. While existing approaches could produce photorealistic high-resolution images with text conditions, there are still several open problems to be solved, which limits the further improvement of image fidelity and text relevancy. In this paper, we propose ERNIE-ViLG 2.0, a large-scale Chinese text-to-image diffusion model, which progressively upgrades the quality of generated images~by: (1) incorporating fine-grained textual and visual knowledge of key elements in the scene, and (2) utilizing different denoising experts at different denoising stages. With the proposed mechanisms, ERNIE-ViLG 2.0 not only achieves the state-of-the-art on MS-COCO with zero-shot FID score of 6.75, but also significantly outperforms recent models in terms of image fidelity and image-text alignment, with side-by-side human evaluation on the bilingual prompt set ViLG-300.
DuETA: Traffic Congestion Propagation Pattern Modeling via Efficient Graph Learning for ETA Prediction at Baidu Maps
Aug 15, 2022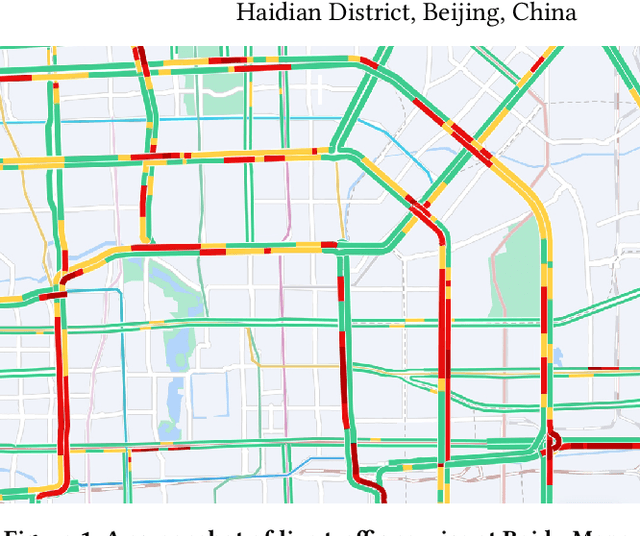
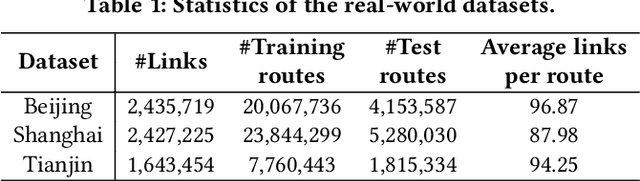
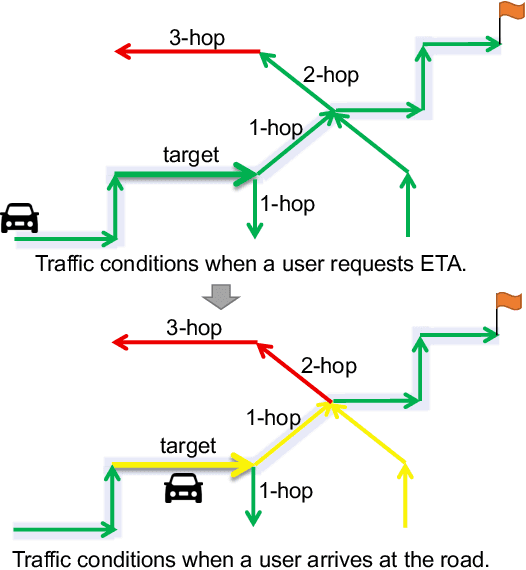
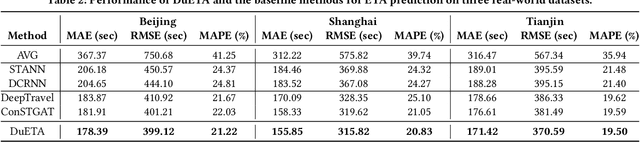
Estimated time of arrival (ETA) prediction, also known as travel time estimation, is a fundamental task for a wide range of intelligent transportation applications, such as navigation, route planning, and ride-hailing services. To accurately predict the travel time of a route, it is essential to take into account both contextual and predictive factors, such as spatial-temporal interaction, driving behavior, and traffic congestion propagation inference. The ETA prediction models previously deployed at Baidu Maps have addressed the factors of spatial-temporal interaction (ConSTGAT) and driving behavior (SSML). In this work, we focus on modeling traffic congestion propagation patterns to improve ETA performance. Traffic congestion propagation pattern modeling is challenging, and it requires accounting for impact regions over time and cumulative effect of delay variations over time caused by traffic events on the road network. In this paper, we present a practical industrial-grade ETA prediction framework named DuETA. Specifically, we construct a congestion-sensitive graph based on the correlations of traffic patterns, and we develop a route-aware graph transformer to directly learn the long-distance correlations of the road segments. This design enables DuETA to capture the interactions between the road segment pairs that are spatially distant but highly correlated with traffic conditions. Extensive experiments are conducted on large-scale, real-world datasets collected from Baidu Maps. Experimental results show that ETA prediction can significantly benefit from the learned traffic congestion propagation patterns. In addition, DuETA has already been deployed in production at Baidu Maps, serving billions of requests every day. This demonstrates that DuETA is an industrial-grade and robust solution for large-scale ETA prediction services.
ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
Dec 23, 2021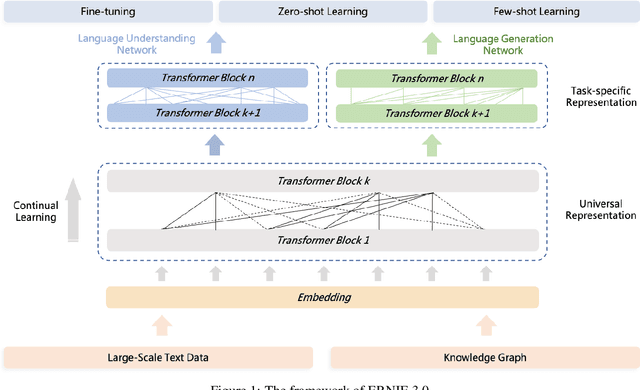
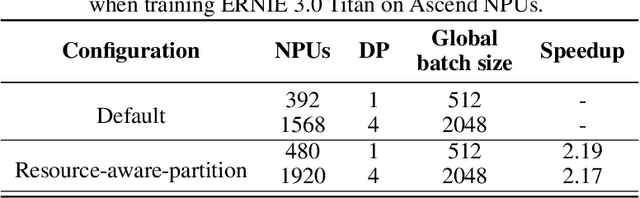
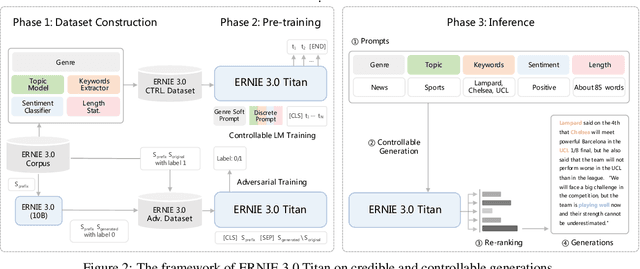
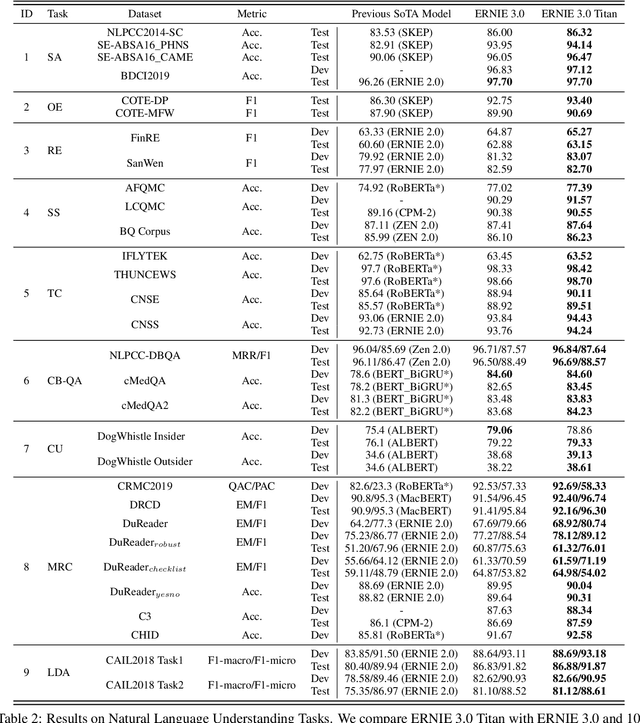
Pre-trained language models have achieved state-of-the-art results in various Natural Language Processing (NLP) tasks. GPT-3 has shown that scaling up pre-trained language models can further exploit their enormous potential. A unified framework named ERNIE 3.0 was recently proposed for pre-training large-scale knowledge enhanced models and trained a model with 10 billion parameters. ERNIE 3.0 outperformed the state-of-the-art models on various NLP tasks. In order to explore the performance of scaling up ERNIE 3.0, we train a hundred-billion-parameter model called ERNIE 3.0 Titan with up to 260 billion parameters on the PaddlePaddle platform. Furthermore, we design a self-supervised adversarial loss and a controllable language modeling loss to make ERNIE 3.0 Titan generate credible and controllable texts. To reduce the computation overhead and carbon emission, we propose an online distillation framework for ERNIE 3.0 Titan, where the teacher model will teach students and train itself simultaneously. ERNIE 3.0 Titan is the largest Chinese dense pre-trained model so far. Empirical results show that the ERNIE 3.0 Titan outperforms the state-of-the-art models on 68 NLP datasets.
ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
Jul 05, 2021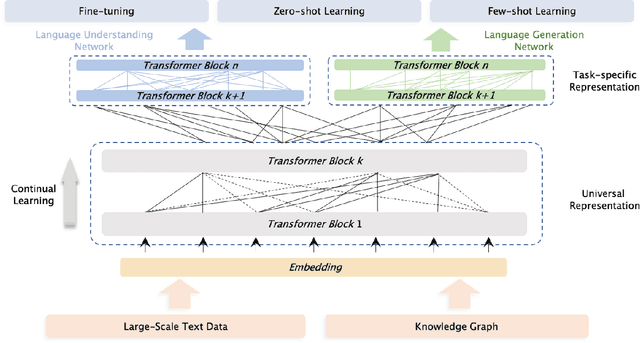

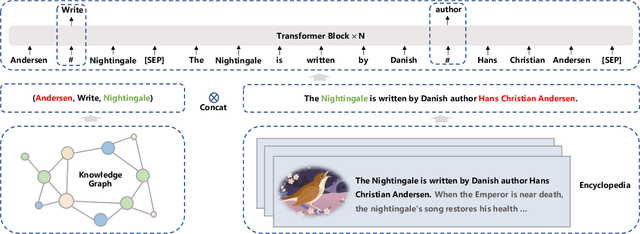
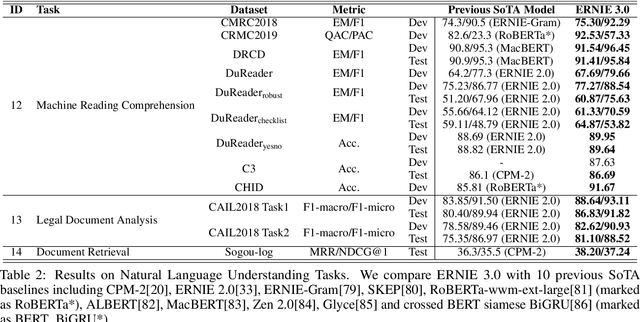
Pre-trained models have achieved state-of-the-art results in various Natural Language Processing (NLP) tasks. Recent works such as T5 and GPT-3 have shown that scaling up pre-trained language models can improve their generalization abilities. Particularly, the GPT-3 model with 175 billion parameters shows its strong task-agnostic zero-shot/few-shot learning capabilities. Despite their success, these large-scale models are trained on plain texts without introducing knowledge such as linguistic knowledge and world knowledge. In addition, most large-scale models are trained in an auto-regressive way. As a result, this kind of traditional fine-tuning approach demonstrates relatively weak performance when solving downstream language understanding tasks. In order to solve the above problems, we propose a unified framework named ERNIE 3.0 for pre-training large-scale knowledge enhanced models. It fuses auto-regressive network and auto-encoding network, so that the trained model can be easily tailored for both natural language understanding and generation tasks with zero-shot learning, few-shot learning or fine-tuning. We trained the model with 10 billion parameters on a 4TB corpus consisting of plain texts and a large-scale knowledge graph. Empirical results show that the model outperforms the state-of-the-art models on 54 Chinese NLP tasks, and its English version achieves the first place on the SuperGLUE benchmark (July 3, 2021), surpassing the human performance by +0.8% (90.6% vs. 89.8%).
ERNIE-Tiny : A Progressive Distillation Framework for Pretrained Transformer Compression
Jun 04, 2021
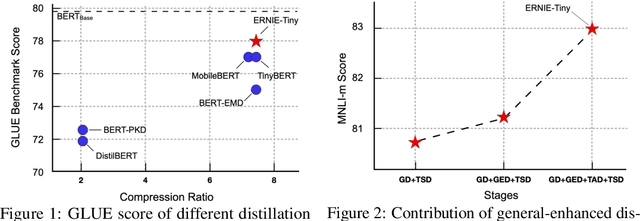
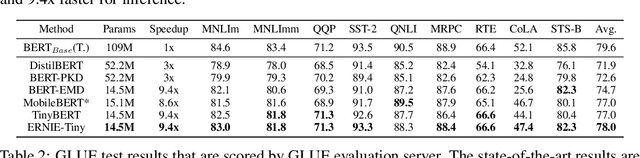
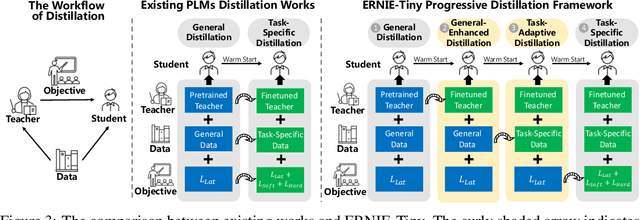
Pretrained language models (PLMs) such as BERT adopt a training paradigm which first pretrain the model in general data and then finetune the model on task-specific data, and have recently achieved great success. However, PLMs are notorious for their enormous parameters and hard to be deployed on real-life applications. Knowledge distillation has been prevailing to address this problem by transferring knowledge from a large teacher to a much smaller student over a set of data. We argue that the selection of thee three key components, namely teacher, training data, and learning objective, is crucial to the effectiveness of distillation. We, therefore, propose a four-stage progressive distillation framework ERNIE-Tiny to compress PLM, which varies the three components gradually from general level to task-specific level. Specifically, the first stage, General Distillation, performs distillation with guidance from pretrained teacher, gerenal data and latent distillation loss. Then, General-Enhanced Distillation changes teacher model from pretrained teacher to finetuned teacher. After that, Task-Adaptive Distillation shifts training data from general data to task-specific data. In the end, Task-Specific Distillation, adds two additional losses, namely Soft-Label and Hard-Label loss onto the last stage. Empirical results demonstrate the effectiveness of our framework and generalization gain brought by ERNIE-Tiny.In particular, experiments show that a 4-layer ERNIE-Tiny maintains over 98.0%performance of its 12-layer teacher BERT base on GLUE benchmark, surpassing state-of-the-art (SOTA) by 1.0% GLUE score with the same amount of parameters. Moreover, ERNIE-Tiny achieves a new compression SOTA on five Chinese NLP tasks, outperforming BERT base by 0.4% accuracy with 7.5x fewer parameters and9.4x faster inference speed.
kk2018 at SemEval-2020 Task 9: Adversarial Training for Code-Mixing Sentiment Classification
Sep 09, 2020
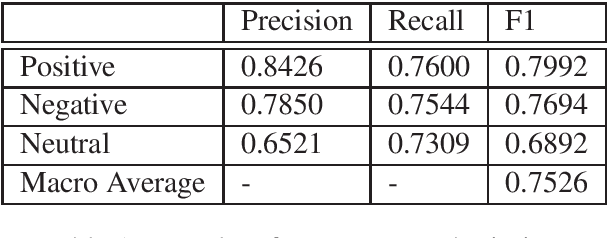
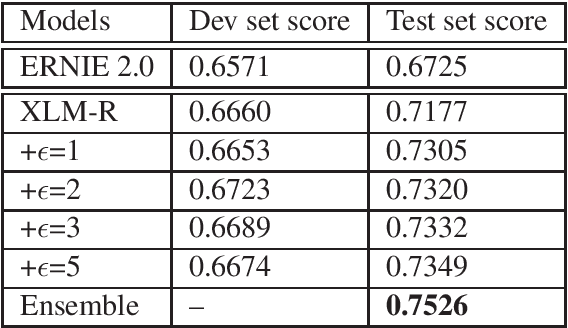
Code switching is a linguistic phenomenon that may occur within a multilingual setting where speakers share more than one language. With the increasing communication between groups with different languages, this phenomenon is more and more popular. However, there are little research and data in this area, especially in code-mixing sentiment classification. In this work, the domain transfer learning from state-of-the-art uni-language model ERNIE is tested on the code-mixing dataset, and surprisingly, a strong baseline is achieved. Furthermore, the adversarial training with a multi-lingual model is used to achieve 1st place of SemEval-2020 Task 9 Hindi-English sentiment classification competition.
ERNIE at SemEval-2020 Task 10: Learning Word Emphasis Selection by Pre-trained Language Model
Sep 08, 2020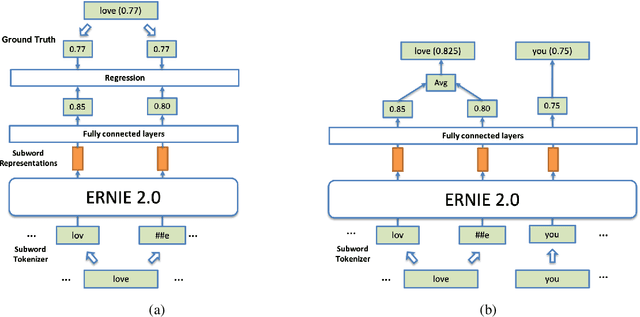

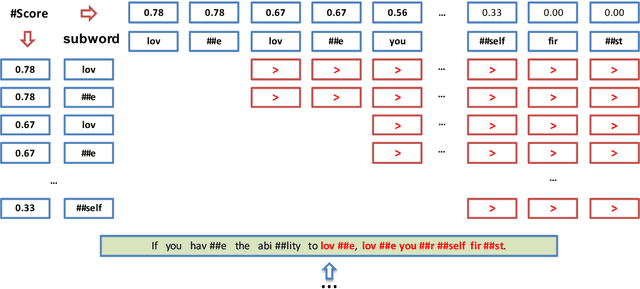

This paper describes the system designed by ERNIE Team which achieved the first place in SemEval-2020 Task 10: Emphasis Selection For Written Text in Visual Media. Given a sentence, we are asked to find out the most important words as the suggestion for automated design. We leverage the unsupervised pre-training model and finetune these models on our task. After our investigation, we found that the following models achieved an excellent performance in this task: ERNIE 2.0, XLM-ROBERTA, ROBERTA and ALBERT. We combine a pointwise regression loss and a pairwise ranking loss which is more close to the final M atchm metric to finetune our models. And we also find that additional feature engineering and data augmentation can help improve the performance. Our best model achieves the highest score of 0.823 and ranks first for all kinds of metrics
ERNIE: Enhanced Representation through Knowledge Integration
Apr 19, 2019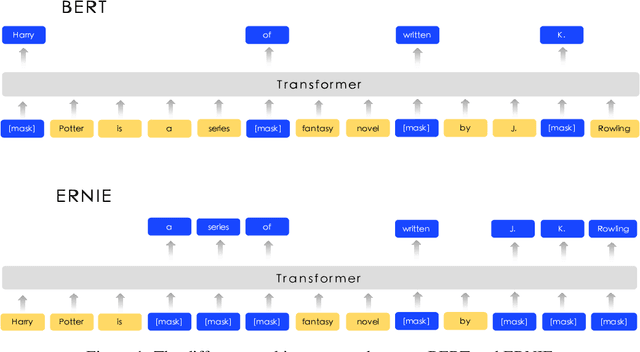
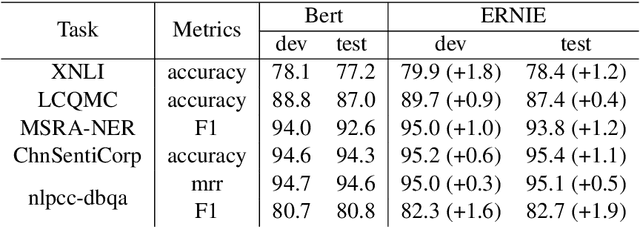

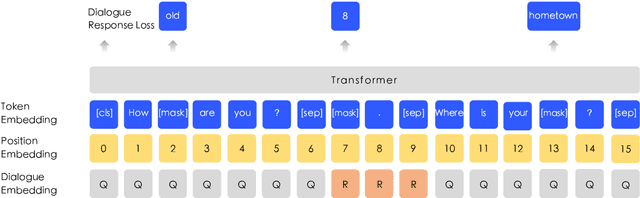
We present a novel language representation model enhanced by knowledge called ERNIE (Enhanced Representation through kNowledge IntEgration). Inspired by the masking strategy of BERT, ERNIE is designed to learn language representation enhanced by knowledge masking strategies, which includes entity-level masking and phrase-level masking. Entity-level strategy masks entities which are usually composed of multiple words.Phrase-level strategy masks the whole phrase which is composed of several words standing together as a conceptual unit.Experimental results show that ERNIE outperforms other baseline methods, achieving new state-of-the-art results on five Chinese natural language processing tasks including natural language inference, semantic similarity, named entity recognition, sentiment analysis and question answering. We also demonstrate that ERNIE has more powerful knowledge inference capacity on a cloze test.