 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
ERNIE-ViLG 2.0: Improving Text-to-Image Diffusion Model with Knowledge-Enhanced Mixture-of-Denoising-Experts
Oct 27, 2022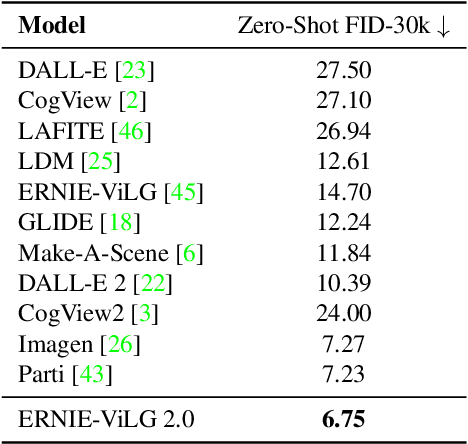
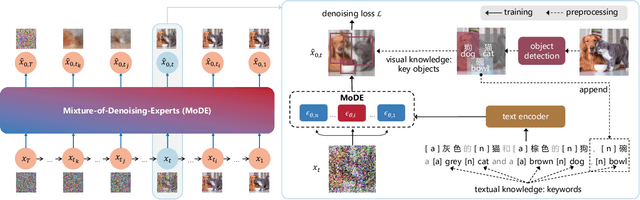
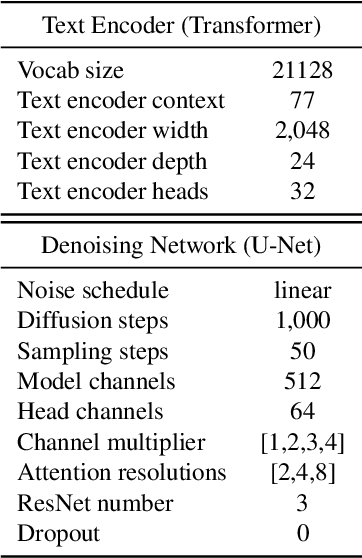
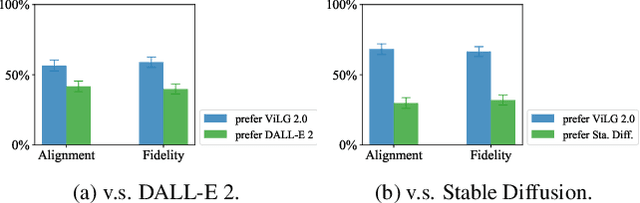
Recent progress in diffusion models has revolutionized the popular technology of text-to-image generation. While existing approaches could produce photorealistic high-resolution images with text conditions, there are still several open problems to be solved, which limits the further improvement of image fidelity and text relevancy. In this paper, we propose ERNIE-ViLG 2.0, a large-scale Chinese text-to-image diffusion model, which progressively upgrades the quality of generated images~by: (1) incorporating fine-grained textual and visual knowledge of key elements in the scene, and (2) utilizing different denoising experts at different denoising stages. With the proposed mechanisms, ERNIE-ViLG 2.0 not only achieves the state-of-the-art on MS-COCO with zero-shot FID score of 6.75, but also significantly outperforms recent models in terms of image fidelity and image-text alignment, with side-by-side human evaluation on the bilingual prompt set ViLG-300.
ERNIE-ViLG: Unified Generative Pre-training for Bidirectional Vision-Language Generation
Dec 31, 2021
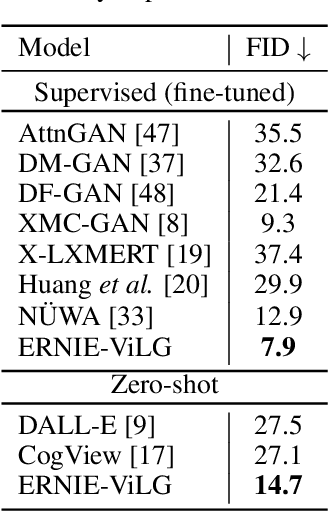


Conventional methods for the image-text generation tasks mainly tackle the naturally bidirectional generation tasks separately, focusing on designing task-specific frameworks to improve the quality and fidelity of the generated samples. Recently, Vision-Language Pre-training models have greatly improved the performance of the image-to-text generation tasks, but large-scale pre-training models for text-to-image synthesis task are still under-developed. In this paper, we propose ERNIE-ViLG, a unified generative pre-training framework for bidirectional image-text generation with transformer model. Based on the image quantization models, we formulate both image generation and text generation as autoregressive generative tasks conditioned on the text/image input. The bidirectional image-text generative modeling eases the semantic alignments across vision and language. For the text-to-image generation process, we further propose an end-to-end training method to jointly learn the visual sequence generator and the image reconstructor. To explore the landscape of large-scale pre-training for bidirectional text-image generation, we train a 10-billion parameter ERNIE-ViLG model on a large-scale dataset of 145 million (Chinese) image-text pairs which achieves state-of-the-art performance for both text-to-image and image-to-text tasks, obtaining an FID of 7.9 on MS-COCO for text-to-image synthesis and best results on COCO-CN and AIC-ICC for image captioning.