 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE-ViLG: Unified Generative Pre-training for Bidirectional Vision-Language Generation
Dec 31, 2021
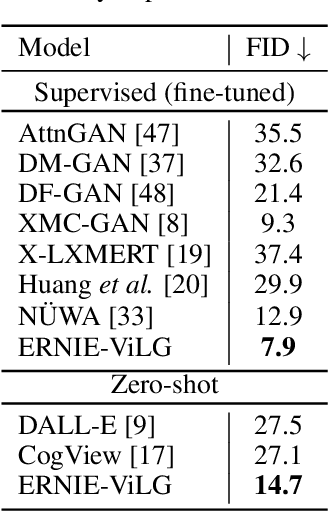


Conventional methods for the image-text generation tasks mainly tackle the naturally bidirectional generation tasks separately, focusing on designing task-specific frameworks to improve the quality and fidelity of the generated samples. Recently, Vision-Language Pre-training models have greatly improved the performance of the image-to-text generation tasks, but large-scale pre-training models for text-to-image synthesis task are still under-developed. In this paper, we propose ERNIE-ViLG, a unified generative pre-training framework for bidirectional image-text generation with transformer model. Based on the image quantization models, we formulate both image generation and text generation as autoregressive generative tasks conditioned on the text/image input. The bidirectional image-text generative modeling eases the semantic alignments across vision and language. For the text-to-image generation process, we further propose an end-to-end training method to jointly learn the visual sequence generator and the image reconstructor. To explore the landscape of large-scale pre-training for bidirectional text-image generation, we train a 10-billion parameter ERNIE-ViLG model on a large-scale dataset of 145 million (Chinese) image-text pairs which achieves state-of-the-art performance for both text-to-image and image-to-text tasks, obtaining an FID of 7.9 on MS-COCO for text-to-image synthesis and best results on COCO-CN and AIC-ICC for image captioning.