 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePROMISE: Prompt-Attentive Hierarchical Contrastive Learning for Robust Cross-Modal Representation with Missing Modalities
Nov 14, 2025Multimodal models integrating natural language and visual information have substantially improved generalization of representation models. However, their effectiveness significantly declines in real-world situations where certain modalities are missing or unavailable. This degradation primarily stems from inconsistent representation learning between complete multimodal data and incomplete modality scenarios. Existing approaches typically address missing modalities through relatively simplistic generation methods, yet these approaches fail to adequately preserve cross-modal consistency, leading to suboptimal performance. To overcome this limitation, we propose a novel multimodal framework named PROMISE, a PROMpting-Attentive HIerarchical ContraStive LEarning approach designed explicitly for robust cross-modal representation under conditions of missing modalities. Specifically, PROMISE innovatively incorporates multimodal prompt learning into a hierarchical contrastive learning framework, equipped with a specially designed prompt-attention mechanism. This mechanism dynamically generates robust and consistent representations for scenarios where particular modalities are absent, thereby effectively bridging the representational gap between complete and incomplete data. Extensive experiments conducted on benchmark datasets, along with comprehensive ablation studies, clearly demonstrate the superior performance of PROMISE compared to current state-of-the-art multimodal methods.
Towards An Efficient and Effective En Route Travel Time Estimation Framework
Apr 05, 2025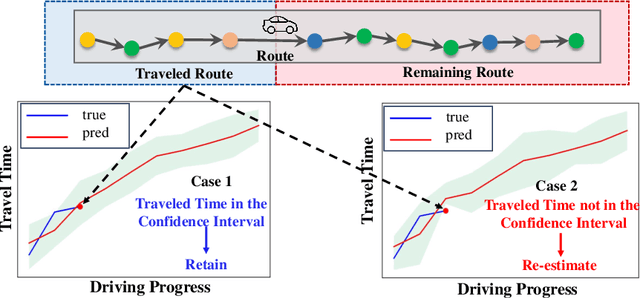

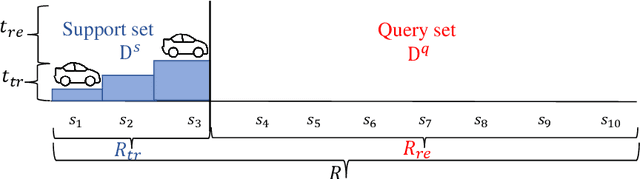

En route travel time estimation (ER-TTE) focuses on predicting the travel time of the remaining route. Existing ER-TTE methods always make re-estimation which significantly hinders real-time performance, especially when faced with the computational demands of simultaneous user requests. This results in delays and reduced responsiveness in ER-TTE services. We propose a general efficient framework U-ERTTE combining an Uncertainty-Guided Decision mechanism (UGD) and Fine-Tuning with Meta-Learning (FTML) to address these challenges. UGD quantifies the uncertainty and provides confidence intervals for the entire route. It selectively re-estimates only when the actual travel time deviates from the predicted confidence intervals, thereby optimizing the efficiency of ER-TTE. To ensure the accuracy of confidence intervals and accurate predictions that need to re-estimate, FTML is employed to train the model, enabling it to learn general driving patterns and specific features to adapt to specific tasks. Extensive experiments on two large-scale real datasets demonstrate that the U-ERTTE framework significantly enhances inference speed and throughput while maintaining high effectiveness. Our code is available at https://github.com/shenzekai/U-ERTTE
SOLA-GCL: Subgraph-Oriented Learnable Augmentation Method for Graph Contrastive Learning
Mar 13, 2025Graph contrastive learning has emerged as a powerful technique for learning graph representations that are robust and discriminative. However, traditional approaches often neglect the critical role of subgraph structures, particularly the intra-subgraph characteristics and inter-subgraph relationships, which are crucial for generating informative and diverse contrastive pairs. These subgraph features are crucial as they vary significantly across different graph types, such as social networks where they represent communities, and biochemical networks where they symbolize molecular interactions. To address this issue, our work proposes a novel subgraph-oriented learnable augmentation method for graph contrastive learning, termed SOLA-GCL, that centers around subgraphs, taking full advantage of the subgraph information for data augmentation. Specifically, SOLA-GCL initially partitions a graph into multiple densely connected subgraphs based on their intrinsic properties. To preserve and enhance the unique characteristics inherent to subgraphs, a graph view generator optimizes augmentation strategies for each subgraph, thereby generating tailored views for graph contrastive learning. This generator uses a combination of intra-subgraph and inter-subgraph augmentation strategies, including node dropping, feature masking, intra-edge perturbation, inter-edge perturbation, and subgraph swapping. Extensive experiments have been conducted on various graph learning applications, ranging from social networks to molecules, under semi-supervised learning, unsupervised learning, and transfer learning settings to demonstrate the superiority of our proposed approach over the state-of-the-art in GCL.
RLER-TTE: An Efficient and Effective Framework for En Route Travel Time Estimation with Reinforcement Learning
Jan 26, 2025



En Route Travel Time Estimation (ER-TTE) aims to learn driving patterns from traveled routes to achieve rapid and accurate real-time predictions. However, existing methods ignore the complexity and dynamism of real-world traffic systems, resulting in significant gaps in efficiency and accuracy in real-time scenarios. Addressing this issue is a critical yet challenging task. This paper proposes a novel framework that redefines the implementation path of ER-TTE to achieve highly efficient and effective predictions. Firstly, we introduce a novel pipeline consisting of a Decision Maker and a Predictor to rectify the inefficient prediction strategies of current methods. The Decision Maker performs efficient real-time decisions to determine whether the high-complexity prediction model in the Predictor needs to be invoked, and the Predictor recalculates the travel time or infers from historical prediction results based on these decisions. Next, to tackle the dynamic and uncertain real-time scenarios, we model the online decision-making problem as a Markov decision process and design an intelligent agent based on reinforcement learning for autonomous decision-making. Moreover, to fully exploit the spatio-temporal correlation between online data and offline data, we meticulously design feature representation and encoding techniques based on the attention mechanism. Finally, to improve the flawed training and evaluation strategies of existing methods, we propose an end-to-end training and evaluation approach, incorporating curriculum learning strategies to manage spatio-temporal data for more advanced training algorithms. Extensive evaluations on three real-world datasets confirm that our method significantly outperforms state-of-the-art solutions in both accuracy and efficiency.
CORAG: A Cost-Constrained Retrieval Optimization System for Retrieval-Augmented Generation
Nov 01, 2024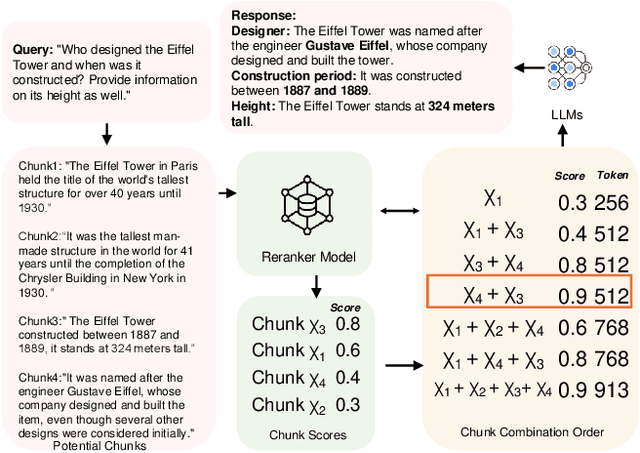

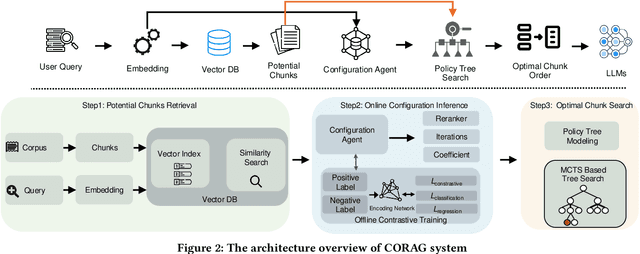
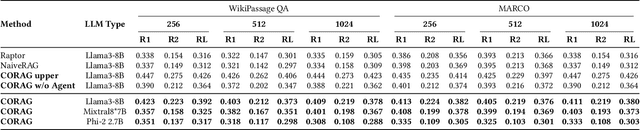
Large Language Models (LLMs) have demonstrated remarkable generation capabilities but often struggle to access up-to-date information, which can lead to hallucinations. Retrieval-Augmented Generation (RAG) addresses this issue by incorporating knowledge from external databases, enabling more accurate and relevant responses. Due to the context window constraints of LLMs, it is impractical to input the entire external database context directly into the model. Instead, only the most relevant information, referred to as chunks, is selectively retrieved. However, current RAG research faces three key challenges. First, existing solutions often select each chunk independently, overlooking potential correlations among them. Second, in practice the utility of chunks is non-monotonic, meaning that adding more chunks can decrease overall utility. Traditional methods emphasize maximizing the number of included chunks, which can inadvertently compromise performance. Third, each type of user query possesses unique characteristics that require tailored handling, an aspect that current approaches do not fully consider. To overcome these challenges, we propose a cost constrained retrieval optimization system CORAG for retrieval-augmented generation. We employ a Monte Carlo Tree Search (MCTS) based policy framework to find optimal chunk combinations sequentially, allowing for a comprehensive consideration of correlations among chunks. Additionally, rather than viewing budget exhaustion as a termination condition, we integrate budget constraints into the optimization of chunk combinations, effectively addressing the non-monotonicity of chunk utility.
Urban Traffic Accident Risk Prediction Revisited: Regionality, Proximity, Similarity and Sparsity
Jul 29, 2024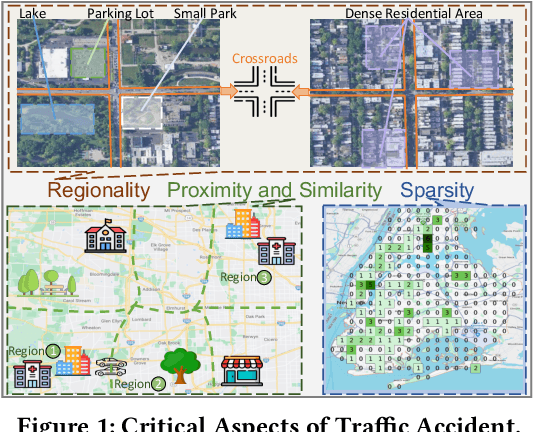
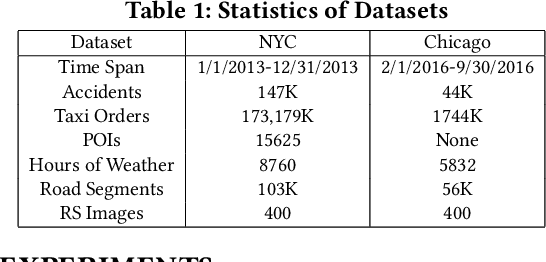
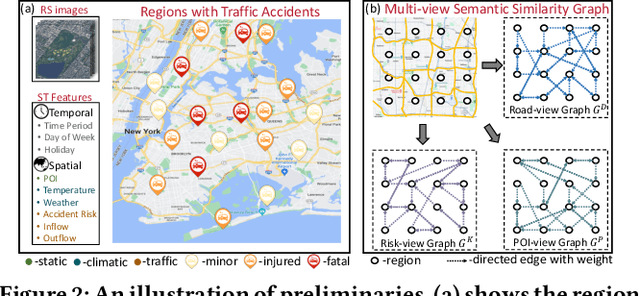
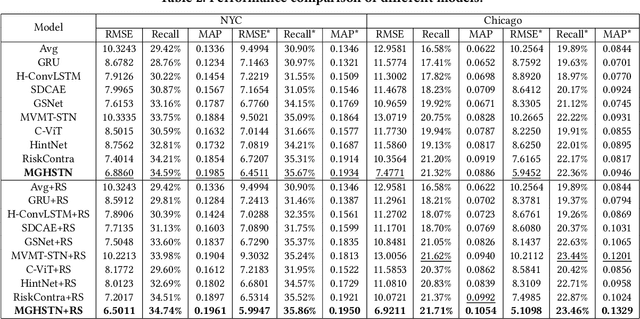
Traffic accidents pose a significant risk to human health and property safety. Therefore, to prevent traffic accidents, predicting their risks has garnered growing interest. We argue that a desired prediction solution should demonstrate resilience to the complexity of traffic accidents. In particular, it should adequately consider the regional background, accurately capture both spatial proximity and semantic similarity, and effectively address the sparsity of traffic accidents. However, these factors are often overlooked or difficult to incorporate. In this paper, we propose a novel multi-granularity hierarchical spatio-temporal network. Initially, we innovate by incorporating remote sensing data, facilitating the creation of hierarchical multi-granularity structure and the comprehension of regional background. We construct multiple high-level risk prediction tasks to enhance model's ability to cope with sparsity. Subsequently, to capture both spatial proximity and semantic similarity, region feature and multi-view graph undergo encoding processes to distill effective representations. Additionally, we propose message passing and adaptive temporal attention module that bridges different granularities and dynamically captures time correlations inherent in traffic accident patterns. At last, a multivariate hierarchical loss function is devised considering the complexity of the prediction purpose. Extensive experiments on two real datasets verify the superiority of our model against the state-of-the-art methods.
LLM-R2: A Large Language Model Enhanced Rule-based Rewrite System for Boosting Query Efficiency
Apr 19, 2024



Query rewrite, which aims to generate more efficient queries by altering a SQL query's structure without changing the query result, has been an important research problem. In order to maintain equivalence between the rewritten query and the original one during rewriting, traditional query rewrite methods always rewrite the queries following certain rewrite rules. However, some problems still remain. Firstly, existing methods of finding the optimal choice or sequence of rewrite rules are still limited and the process always costs a lot of resources. Methods involving discovering new rewrite rules typically require complicated proofs of structural logic or extensive user interactions. Secondly, current query rewrite methods usually rely highly on DBMS cost estimators which are often not accurate. In this paper, we address these problems by proposing a novel method of query rewrite named LLM-R2, adopting a large language model (LLM) to propose possible rewrite rules for a database rewrite system. To further improve the inference ability of LLM in recommending rewrite rules, we train a contrastive model by curriculum to learn query representations and select effective query demonstrations for the LLM. Experimental results have shown that our method can significantly improve the query execution efficiency and outperform the baseline methods. In addition, our method enjoys high robustness across different datasets.
STMGF: An Effective Spatial-Temporal Multi-Granularity Framework for Traffic Forecasting
Apr 08, 2024



Accurate Traffic Prediction is a challenging task in intelligent transportation due to the spatial-temporal aspects of road networks. The traffic of a road network can be affected by long-distance or long-term dependencies where existing methods fall short in modeling them. In this paper, we introduce a novel framework known as Spatial-Temporal Multi-Granularity Framework (STMGF) to enhance the capture of long-distance and long-term information of the road networks. STMGF makes full use of different granularity information of road networks and models the long-distance and long-term information by gathering information in a hierarchical interactive way. Further, it leverages the inherent periodicity in traffic sequences to refine prediction results by matching with recent traffic data. We conduct experiments on two real-world datasets, and the results demonstrate that STMGF outperforms all baseline models and achieves state-of-the-art performance.
Towards Effective Next POI Prediction: Spatial and Semantic Augmentation with Remote Sensing Data
Mar 22, 2024



The next point-of-interest (POI) prediction is a significant task in location-based services, yet its complexity arises from the consolidation of spatial and semantic intent. This fusion is subject to the influences of historical preferences, prevailing location, and environmental factors, thereby posing significant challenges. In addition, the uneven POI distribution further complicates the next POI prediction procedure. To address these challenges, we enrich input features and propose an effective deep-learning method within a two-step prediction framework. Our method first incorporates remote sensing data, capturing pivotal environmental context to enhance input features regarding both location and semantics. Subsequently, we employ a region quad-tree structure to integrate urban remote sensing, road network, and POI distribution spaces, aiming to devise a more coherent graph representation method for urban spatial. Leveraging this method, we construct the QR-P graph for the user's historical trajectories to encapsulate historical travel knowledge, thereby augmenting input features with comprehensive spatial and semantic insights. We devise distinct embedding modules to encode these features and employ an attention mechanism to fuse diverse encodings. In the two-step prediction procedure, we initially identify potential spatial zones by predicting user-preferred tiles, followed by pinpointing specific POIs of a designated type within the projected tiles. Empirical findings from four real-world location-based social network datasets underscore the remarkable superiority of our proposed approach over competitive baseline methods.
GraphRARE: Reinforcement Learning Enhanced Graph Neural Network with Relative Entropy
Dec 15, 2023



Graph neural networks (GNNs) have shown advantages in graph-based analysis tasks. However, most existing methods have the homogeneity assumption and show poor performance on heterophilic graphs, where the linked nodes have dissimilar features and different class labels, and the semantically related nodes might be multi-hop away. To address this limitation, this paper presents GraphRARE, a general framework built upon node relative entropy and deep reinforcement learning, to strengthen the expressive capability of GNNs. An innovative node relative entropy, which considers node features and structural similarity, is used to measure mutual information between node pairs. In addition, to avoid the sub-optimal solutions caused by mixing useful information and noises of remote nodes, a deep reinforcement learning-based algorithm is developed to optimize the graph topology. This algorithm selects informative nodes and discards noisy nodes based on the defined node relative entropy. Extensive experiments are conducted on seven real-world datasets. The experimental results demonstrate the superiority of GraphRARE in node classification and its capability to optimize the original graph topology.