 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing the Reasoning Load: Difficulty-Differentiated Policy Optimization with Length Redistribution for Efficient and Robust Reinforcement Learning
Mar 19, 2026Large Reasoning Models (LRMs) have shown exceptional reasoning capabilities, but they also suffer from the issue of overthinking, often generating excessively long and redundant answers. For problems that exceed the model's capabilities, LRMs tend to exhibit the overconfidence phenomenon, generating overly short but incorrect answers, which may contribute to suboptimal performance. To address these issues, we propose Difficulty-Differentiated Policy Optimization (DDPO), an efficient reinforcement learning algorithm that optimizes simple and complex tasks separately based on the overconfidence phenomenon. Specifically, it reduces the output length for simple tasks without compromising accuracy, while for complex tasks, it expands the exploration space to improve performance. We further derive the theoretical conditions for maximizing expected accuracy, which require the length distribution to closely approximate the optimal length and be as concentrated as possible. Based on these conditions, we propose using the difficulty-level average as a well-founded reference for length optimization. Extensive experiments on both in-domain and out-of-domain benchmarks validate the superiority and effectiveness of DDPO. Compared to GRPO, DDPO reduces the average answer length by 12% while improving accuracy by 1.85% across multiple benchmarks, achieving a better trade-off between accuracy and length. The code is available at https://github.com/Yinan-Xia/DDPO.
From the Inside Out: Progressive Distribution Refinement for Confidence Calibration
Mar 17, 2026Leveraging the model's internal information as the self-reward signal in Reinforcement Learning (RL) has received extensive attention due to its label-free nature. While prior works have made significant progress in applying the Test-Time Scaling (TTS) strategies to RL, the discrepancy in internal information between test and training remains inadequately addressed. Moreover, Test-Time Training based on voting-based TTS strategies often suffers from reward hacking problems. To address these issues, we propose DistriTTRL, which leverages the distribution prior of the model's confidence during RL to progressively optimize the reward signal, rather than relying solely on single-query rollouts. Additionally, we mitigate the phenomenon of consistent reward hacking caused by the voting-based TTS strategies through diversity-targeted penalties. Benefiting from this training mechanism where model capability and self-reward signals complement each other, and the mitigation of reward hacking, DistriTTRL has achieved significant performance improvements across multiple models and benchmarks.
Semantic Bridging Domains: Pseudo-Source as Test-Time Connector
Mar 04, 2026Distribution shifts between training and testing data are a critical bottleneck limiting the practical utility of models, especially in real-world test-time scenarios. To adapt models when the source domain is unknown and the target domain is unlabeled, previous works constructed pseudo-source domains via data generation and translation, then aligned the target domain with them. However, significant discrepancies exist between the pseudo-source and the original source domain, leading to potential divergence when correcting the target directly. From this perspective, we propose a Stepwise Semantic Alignment (SSA) method, viewing the pseudo-source as a semantic bridge connecting the source and target, rather than a direct substitute for the source. Specifically, we leverage easily accessible universal semantics to rectify the semantic features of the pseudo-source, and then align the target domain using the corrected pseudo-source semantics. Additionally, we introduce a Hierarchical Feature Aggregation (HFA) module and a Confidence-Aware Complementary Learning (CACL) strategy to enhance the semantic quality of the SSA process in the absence of source and ground truth of target domains. We evaluated our approach on tasks like semantic segmentation and image classification, achieving a 5.2% performance boost on GTA2Cityscapes over the state-of-the-art.
Believe Your Model: Distribution-Guided Confidence Calibration
Mar 04, 2026Large Reasoning Models have demonstrated remarkable performance with the advancement of test-time scaling techniques, which enhances prediction accuracy by generating multiple candidate responses and selecting the most reliable answer. While prior work has analyzed that internal model signals like confidence scores can partly indicate response correctness and exhibit a distributional correlation with accuracy, such distributional information has not been fully utilized to guide answer selection. Motivated by this, we propose DistriVoting, which incorporates distributional priors as another signal alongside confidence during voting. Specifically, our method (1) first decomposes the mixed confidence distribution into positive and negative components using Gaussian Mixture Models, (2) then applies a reject filter based on positive/negative samples from them to mitigate overlap between the two distributions. Besides, to further alleviate the overlap from the perspective of distribution itself, we propose SelfStepConf, which uses step-level confidence to dynamically adjust inference process, increasing the separation between the two distributions to improve the reliability of confidences in voting. Experiments across 16 models and 5 benchmarks demonstrate that our method significantly outperforms state-of-the-art approaches.
Efficient RLVR Training via Weighted Mutual Information Data Selection
Mar 02, 2026Reinforcement learning (RL) plays a central role in improving the reasoning and alignment of large language models, yet its efficiency critically depends on how training data are selected. Existing online selection strategies predominantly rely on difficulty-based heuristics, favouring datapoints with intermediate success rates, implicitly equating difficulty with informativeness and neglecting epistemic uncertainty arising from limited evidence. We introduce InSight, an INformation-guided data SamplInG metHod for RL Training, grounded in a weighted mutual information objective. By modeling data outcomes with Bayesian latent success rates, we show that expected uncertainty reduction decomposes into complementary difficulty- and evidence-dependent components, revealing a fundamental limitation of difficulty-only selection. Leveraging this observation, InSight constructs a stable acquisition score based on the mean belief of datapoints' success rather than noisy sampled outcomes, and naturally extends to multi-rollout settings common in reinforcement learning with verifiable rewards (RLVR). Extensive experiments demonstrate that InSight consistently achieves state-of-the-art performance and improves training efficiency, including a +1.41 average gain on Planning & Mathmatics benchmarks, +1.01 improvement on general reasoning, and up to ~2.2x acceleration, with negligible additional computational overhead.
SWE-Compass: Towards Unified Evaluation of Agentic Coding Abilities for Large Language Models
Nov 07, 2025Evaluating large language models (LLMs) for software engineering has been limited by narrow task coverage, language bias, and insufficient alignment with real-world developer workflows. Existing benchmarks often focus on algorithmic problems or Python-centric bug fixing, leaving critical dimensions of software engineering underexplored. To address these gaps, we introduce SWE-Compass1, a comprehensive benchmark that unifies heterogeneous code-related evaluations into a structured and production-aligned framework. SWE-Compass spans 8 task types, 8 programming scenarios, and 10 programming languages, with 2000 high-quality instances curated from authentic GitHub pull requests and refined through systematic filtering and validation. We benchmark ten state-of-the-art LLMs under two agentic frameworks, SWE-Agent and Claude Code, revealing a clear hierarchy of difficulty across task types, languages, and scenarios. Moreover, by aligning evaluation with real-world developer practices, SWE-Compass provides a rigorous and reproducible foundation for diagnosing and advancing agentic coding capabilities in large language models.
A Scenario-Driven Cognitive Approach to Next-Generation AI Memory
Sep 16, 2025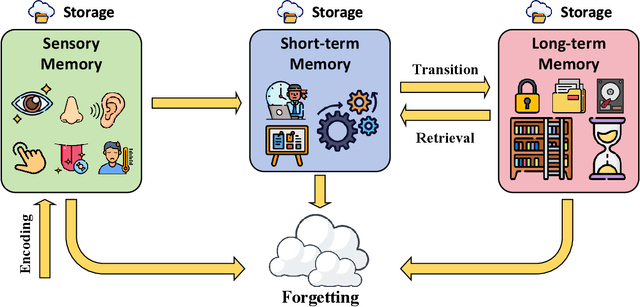
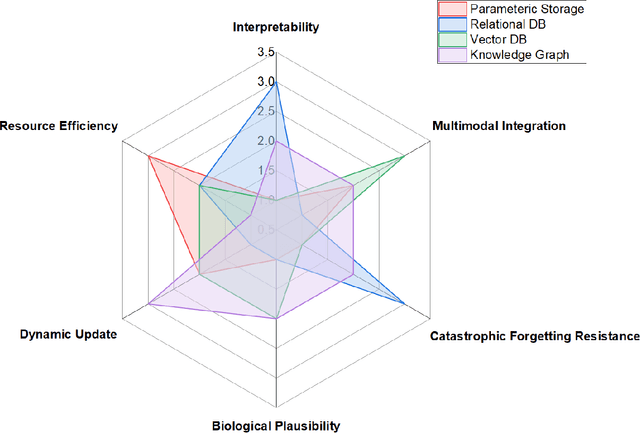
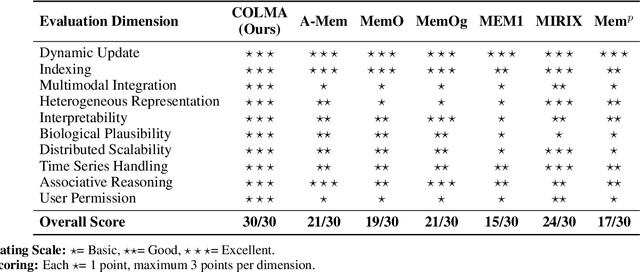
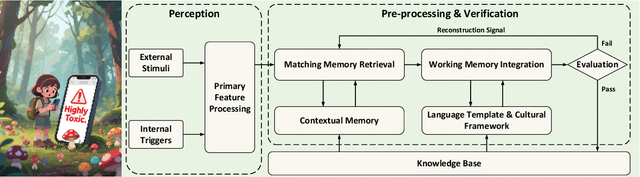
As artificial intelligence advances toward artificial general intelligence (AGI), the need for robust and human-like memory systems has become increasingly evident. Current memory architectures often suffer from limited adaptability, insufficient multimodal integration, and an inability to support continuous learning. To address these limitations, we propose a scenario-driven methodology that extracts essential functional requirements from representative cognitive scenarios, leading to a unified set of design principles for next-generation AI memory systems. Based on this approach, we introduce the \textbf{COgnitive Layered Memory Architecture (COLMA)}, a novel framework that integrates cognitive scenarios, memory processes, and storage mechanisms into a cohesive design. COLMA provides a structured foundation for developing AI systems capable of lifelong learning and human-like reasoning, thereby contributing to the pragmatic development of AGI.
CLaSp: In-Context Layer Skip for Self-Speculative Decoding
May 30, 2025Speculative decoding (SD) is a promising method for accelerating the decoding process of Large Language Models (LLMs). The efficiency of SD primarily hinges on the consistency between the draft model and the verify model. However, existing drafting approaches typically require additional modules to be trained, which can be challenging to implement and ensure compatibility across various LLMs. In this paper, we propose CLaSp, an in-context layer-skipping strategy for self-speculative decoding. Unlike prior methods, CLaSp does not require additional drafting modules or extra training. Instead, it employs a plug-and-play mechanism by skipping intermediate layers of the verify model to construct a compressed draft model. Specifically, we develop a dynamic programming algorithm that optimizes the layer-skipping process by leveraging the complete hidden states from the last verification stage as an objective. This enables CLaSp to dynamically adjust its layer-skipping strategy after each verification stage, without relying on pre-optimized sets of skipped layers. Experimental results across diverse downstream tasks demonstrate that CLaSp achieves a speedup of 1.3x ~ 1.7x on LLaMA3 series models without altering the original distribution of the generated text.
LLM-R2: A Large Language Model Enhanced Rule-based Rewrite System for Boosting Query Efficiency
Apr 19, 2024



Query rewrite, which aims to generate more efficient queries by altering a SQL query's structure without changing the query result, has been an important research problem. In order to maintain equivalence between the rewritten query and the original one during rewriting, traditional query rewrite methods always rewrite the queries following certain rewrite rules. However, some problems still remain. Firstly, existing methods of finding the optimal choice or sequence of rewrite rules are still limited and the process always costs a lot of resources. Methods involving discovering new rewrite rules typically require complicated proofs of structural logic or extensive user interactions. Secondly, current query rewrite methods usually rely highly on DBMS cost estimators which are often not accurate. In this paper, we address these problems by proposing a novel method of query rewrite named LLM-R2, adopting a large language model (LLM) to propose possible rewrite rules for a database rewrite system. To further improve the inference ability of LLM in recommending rewrite rules, we train a contrastive model by curriculum to learn query representations and select effective query demonstrations for the LLM. Experimental results have shown that our method can significantly improve the query execution efficiency and outperform the baseline methods. In addition, our method enjoys high robustness across different datasets.
AdaMergeX: Cross-Lingual Transfer with Large Language Models via Adaptive Adapter Merging
Feb 29, 2024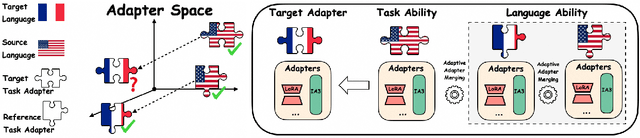

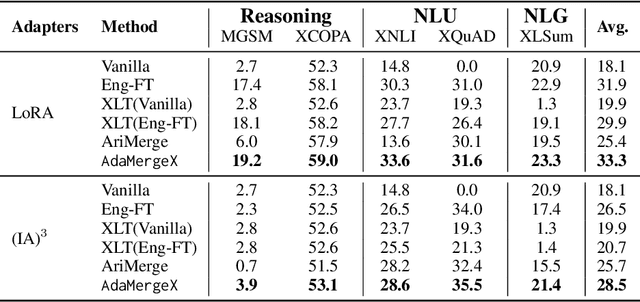

As an effective alternative to the direct fine-tuning on target tasks in specific languages, cross-lingual transfer addresses the challenges of limited training data by decoupling ''task ability'' and ''language ability'' by fine-tuning on the target task in the source language and another selected task in the target language, respectively. However, they fail to fully separate the task ability from the source language or the language ability from the chosen task. In this paper, we acknowledge the mutual reliance between task ability and language ability and direct our attention toward the gap between the target language and the source language on tasks. As the gap removes the impact of tasks, we assume that it remains consistent across tasks. Based on this assumption, we propose a new cross-lingual transfer method called $\texttt{AdaMergeX}$ that utilizes adaptive adapter merging. By introducing a reference task, we can determine that the divergence of adapters fine-tuned on the reference task in both languages follows the same distribution as the divergence of adapters fine-tuned on the target task in both languages. Hence, we can obtain target adapters by combining the other three adapters. Furthermore, we propose a structure-adaptive adapter merging method. Our empirical results demonstrate that our approach yields new and effective cross-lingual transfer, outperforming existing methods across all settings.