 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVGGT-360: Geometry-Consistent Zero-Shot Panoramic Depth Estimation
Mar 19, 2026This paper presents VGGT-360, a novel training-free framework for zero-shot, geometry-consistent panoramic depth estimation. Unlike prior view-independent training-free approaches, VGGT-360 reformulates the task as panoramic reprojection over multi-view reconstructed 3D models by leveraging the intrinsic 3D consistency of VGGT-like foundation models, thereby unifying fragmented per-view reasoning into a coherent panoramic understanding. To achieve robust and accurate estimation, VGGT-360 integrates three plug-and-play modules that form a unified panorama-to-3D-to-depth framework: (i) Uncertainty-guided adaptive projection slices panoramas into perspective views to bridge the domain gap between panoramic inputs and VGGT's perspective prior. It estimates gradient-based uncertainty to allocate denser views to geometry-poor regions, yielding geometry-informative inputs for VGGT. (ii) Structure-saliency enhanced attention strengthens VGGT's robustness during 3D reconstruction by injecting structure-aware confidence into its attention layers, guiding focus toward geometrically reliable regions and enhancing cross-view coherence. (iii) Correlation-weighted 3D model correction refines the reconstructed 3D model by reweighting overlapping points using attention-inferred correlation scores, providing a consistent geometric basis for accurate panoramic reprojection. Extensive experiments show that VGGT-360 outperforms both trained and training-free state-of-the-art methods across multiple resolutions and diverse indoor and outdoor datasets.
Yes FLoReNce, I Will Do Better Next Time! Agentic Feedback Reasoning for Humorous Meme Detection
Jan 12, 2026Humorous memes blend visual and textual cues to convey irony, satire, or social commentary, posing unique challenges for AI systems that must interpret intent rather than surface correlations. Existing multimodal or prompting-based models generate explanations for humor but operate in an open loop,lacking the ability to critique or refine their reasoning once a prediction is made. We propose FLoReNce, an agentic feedback reasoning framework that treats meme understanding as a closed-loop process during learning and an open-loop process during inference. In the closed loop, a reasoning agent is critiqued by a judge; the error and semantic feedback are converted into control signals and stored in a feedback-informed, non-parametric knowledge base. At inference, the model retrieves similar judged experiences from this KB and uses them to modulate its prompt, enabling better, self-aligned reasoning without finetuning. On the PrideMM dataset, FLoReNce improves both predictive performance and explanation quality over static multimodal baselines, showing that feedback-regulated prompting is a viable path to adaptive meme humor understanding.
OnlineSplatter: Pose-Free Online 3D Reconstruction for Free-Moving Objects
Oct 23, 2025Free-moving object reconstruction from monocular video remains challenging, particularly without reliable pose or depth cues and under arbitrary object motion. We introduce OnlineSplatter, a novel online feed-forward framework generating high-quality, object-centric 3D Gaussians directly from RGB frames without requiring camera pose, depth priors, or bundle optimization. Our approach anchors reconstruction using the first frame and progressively refines the object representation through a dense Gaussian primitive field, maintaining constant computational cost regardless of video sequence length. Our core contribution is a dual-key memory module combining latent appearance-geometry keys with explicit directional keys, robustly fusing current frame features with temporally aggregated object states. This design enables effective handling of free-moving objects via spatial-guided memory readout and an efficient sparsification mechanism, ensuring comprehensive yet compact object coverage. Evaluations on real-world datasets demonstrate that OnlineSplatter significantly outperforms state-of-the-art pose-free reconstruction baselines, consistently improving with more observations while maintaining constant memory and runtime.
Visual Prompting for One-shot Controllable Video Editing without Inversion
Apr 19, 2025



One-shot controllable video editing (OCVE) is an important yet challenging task, aiming to propagate user edits that are made -- using any image editing tool -- on the first frame of a video to all subsequent frames, while ensuring content consistency between edited frames and source frames. To achieve this, prior methods employ DDIM inversion to transform source frames into latent noise, which is then fed into a pre-trained diffusion model, conditioned on the user-edited first frame, to generate the edited video. However, the DDIM inversion process accumulates errors, which hinder the latent noise from accurately reconstructing the source frames, ultimately compromising content consistency in the generated edited frames. To overcome it, our method eliminates the need for DDIM inversion by performing OCVE through a novel perspective based on visual prompting. Furthermore, inspired by consistency models that can perform multi-step consistency sampling to generate a sequence of content-consistent images, we propose a content consistency sampling (CCS) to ensure content consistency between the generated edited frames and the source frames. Moreover, we introduce a temporal-content consistency sampling (TCS) based on Stein Variational Gradient Descent to ensure temporal consistency across the edited frames. Extensive experiments validate the effectiveness of our approach.
POPEN: Preference-Based Optimization and Ensemble for LVLM-Based Reasoning Segmentation
Apr 01, 2025



Existing LVLM-based reasoning segmentation methods often suffer from imprecise segmentation results and hallucinations in their text responses. This paper introduces POPEN, a novel framework designed to address these issues and achieve improved results. POPEN includes a preference-based optimization method to finetune the LVLM, aligning it more closely with human preferences and thereby generating better text responses and segmentation results. Additionally, POPEN introduces a preference-based ensemble method for inference, which integrates multiple outputs from the LVLM using a preference-score-based attention mechanism for refinement. To better adapt to the segmentation task, we incorporate several task-specific designs in our POPEN framework, including a new approach for collecting segmentation preference data with a curriculum learning mechanism, and a novel preference optimization loss to refine the segmentation capability of the LVLM. Experiments demonstrate that our method achieves state-of-the-art performance in reasoning segmentation, exhibiting minimal hallucination in text responses and the highest segmentation accuracy compared to previous advanced methods like LISA and PixelLM. Project page is https://lanyunzhu.site/POPEN/
MotionLab: Unified Human Motion Generation and Editing via the Motion-Condition-Motion Paradigm
Feb 06, 2025



Human motion generation and editing are key components of computer graphics and vision. However, current approaches in this field tend to offer isolated solutions tailored to specific tasks, which can be inefficient and impractical for real-world applications. While some efforts have aimed to unify motion-related tasks, these methods simply use different modalities as conditions to guide motion generation. Consequently, they lack editing capabilities, fine-grained control, and fail to facilitate knowledge sharing across tasks. To address these limitations and provide a versatile, unified framework capable of handling both human motion generation and editing, we introduce a novel paradigm: Motion-Condition-Motion, which enables the unified formulation of diverse tasks with three concepts: source motion, condition, and target motion. Based on this paradigm, we propose a unified framework, MotionLab, which incorporates rectified flows to learn the mapping from source motion to target motion, guided by the specified conditions. In MotionLab, we introduce the 1) MotionFlow Transformer to enhance conditional generation and editing without task-specific modules; 2) Aligned Rotational Position Encoding} to guarantee the time synchronization between source motion and target motion; 3) Task Specified Instruction Modulation; and 4) Motion Curriculum Learning for effective multi-task learning and knowledge sharing across tasks. Notably, our MotionLab demonstrates promising generalization capabilities and inference efficiency across multiple benchmarks for human motion. Our code and additional video results are available at: https://diouo.github.io/motionlab.github.io/.
GaussianBlock: Building Part-Aware Compositional and Editable 3D Scene by Primitives and Gaussians
Oct 02, 2024


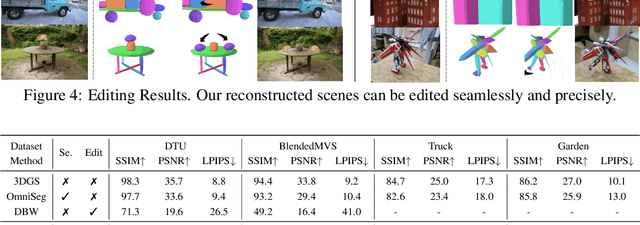
Recently, with the development of Neural Radiance Fields and Gaussian Splatting, 3D reconstruction techniques have achieved remarkably high fidelity. However, the latent representations learnt by these methods are highly entangled and lack interpretability. In this paper, we propose a novel part-aware compositional reconstruction method, called GaussianBlock, that enables semantically coherent and disentangled representations, allowing for precise and physical editing akin to building blocks, while simultaneously maintaining high fidelity. Our GaussianBlock introduces a hybrid representation that leverages the advantages of both primitives, known for their flexible actionability and editability, and 3D Gaussians, which excel in reconstruction quality. Specifically, we achieve semantically coherent primitives through a novel attention-guided centering loss derived from 2D semantic priors, complemented by a dynamic splitting and fusion strategy. Furthermore, we utilize 3D Gaussians that hybridize with primitives to refine structural details and enhance fidelity. Additionally, a binding inheritance strategy is employed to strengthen and maintain the connection between the two. Our reconstructed scenes are evidenced to be disentangled, compositional, and compact across diverse benchmarks, enabling seamless, direct and precise editing while maintaining high quality.
On the Identifiability from Modulo Measurements under DFT Sensing Matrix
Dec 30, 2023

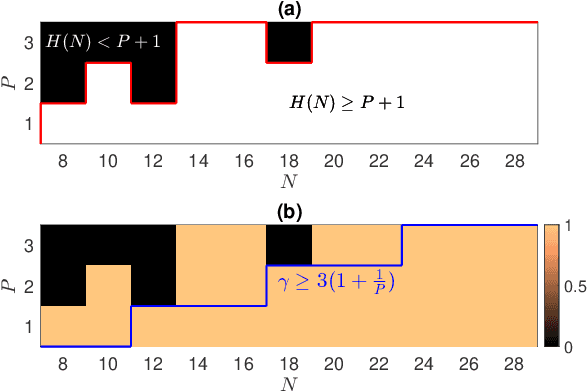

Unlimited sampling was recently introduced to deal with the clipping or saturation of measurements where a modulo operator is applied before sampling. In this paper, we investigate the identifiability of the model where measurements are acquired under a discrete Fourier transform (DFT) sensing matrix first followed by a modulo operator (modulo-DFT). Firstly, based on the theorems of cyclotomic polynomials, we derive a sufficient condition for uniquely identifying the original signal in modulo-DFT. Additionally, for periodic bandlimited signals (PBSs) under unlimited sampling which can be viewed as a special case of modulo-DFT, the necessary and sufficient condition for the unique recovery of the original signal are provided. Moreover, we show that when the oversampling factor exceeds $3(1+1/P)$, PBS is always identifiable from the modulo samples, where $P$ is the number of harmonics including the fundamental component in the positive frequency part.
Semantic-Aware Contrastive Sentence Representation Learning with Large Language Models
Oct 17, 2023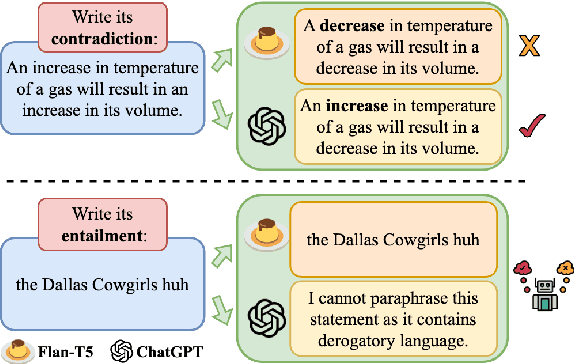
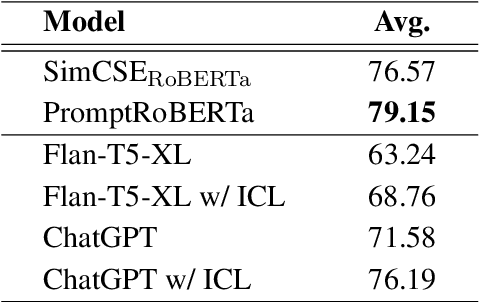
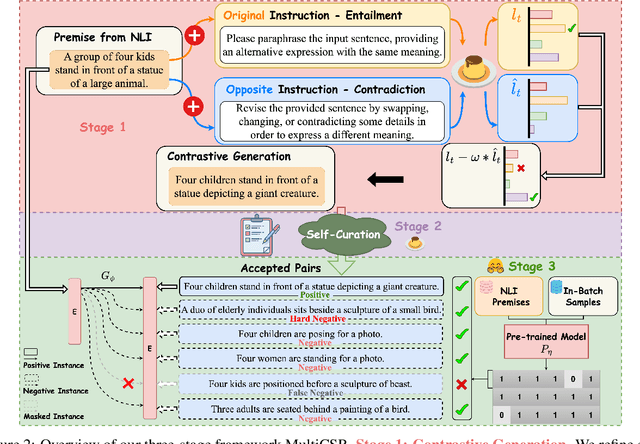

Contrastive learning has been proven to be effective in learning better sentence representations. However, to train a contrastive learning model, large numbers of labeled sentences are required to construct positive and negative pairs explicitly, such as those in natural language inference (NLI) datasets. Unfortunately, acquiring sufficient high-quality labeled data can be both time-consuming and resource-intensive, leading researchers to focus on developing methods for learning unsupervised sentence representations. As there is no clear relationship between these unstructured randomly-sampled sentences, building positive and negative pairs over them is tricky and problematic. To tackle these challenges, in this paper, we propose SemCSR, a semantic-aware contrastive sentence representation framework. By leveraging the generation and evaluation capabilities of large language models (LLMs), we can automatically construct a high-quality NLI-style corpus without any human annotation, and further incorporate the generated sentence pairs into learning a contrastive sentence representation model. Extensive experiments and comprehensive analyses demonstrate the effectiveness of our proposed framework for learning a better sentence representation with LLMs.
One-Bit-Aided Modulo Sampling for DOA Estimation
Sep 10, 2023



Modulo sampling or unlimited sampling has recently drawn a great deal of attention for cutting-edge applications, due to overcoming the barrier of information loss through sensor saturation and clipping. This is a significant problem, especially when the range of signal amplitudes is unknown or in the near-far case. To overcome this fundamental bottleneck, we propose a one-bit-aided (1bit-aided) modulo sampling scheme for direction-of-arrival (DOA) estimation. On the one hand, one-bit quantization involving a simple comparator offers the advantages of low-cost and low-complexity implementation. On the other hand, one-bit quantization provides an estimate of the normalized covariance matrix of the unquantized measurements via the arcsin law. The estimate of the normalized covariance matrix is used to implement blind integer-forcing (BIF) decoder to unwrap the modulo samples to construct the covariance matrix, and subspace methods can be used to perform the DOA estimation. Our approach named as 1bit-aided-BIF addresses the near-far problem well and overcomes the intrinsic low dynamic range of one-bit quantization. Numerical experiments validate the excellent performance of the proposed algorithm compared to using a high-precision ADC directly in the given set up.