 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour AI-Generated Image Detector Can Secretly Achieve SOTA Accuracy, If Calibrated
Feb 02, 2026Despite being trained on balanced datasets, existing AI-generated image detectors often exhibit systematic bias at test time, frequently misclassifying fake images as real. We hypothesize that this behavior stems from distributional shift in fake samples and implicit priors learned during training. Specifically, models tend to overfit to superficial artifacts that do not generalize well across different generation methods, leading to a misaligned decision threshold when faced with test-time distribution shift. To address this, we propose a theoretically grounded post-hoc calibration framework based on Bayesian decision theory. In particular, we introduce a learnable scalar correction to the model's logits, optimized on a small validation set from the target distribution while keeping the backbone frozen. This parametric adjustment compensates for distributional shift in model output, realigning the decision boundary even without requiring ground-truth labels. Experiments on challenging benchmarks show that our approach significantly improves robustness without retraining, offering a lightweight and principled solution for reliable and adaptive AI-generated image detection in the open world. Code is available at https://github.com/muliyangm/AIGI-Det-Calib.
Visual Prompting for One-shot Controllable Video Editing without Inversion
Apr 19, 2025



One-shot controllable video editing (OCVE) is an important yet challenging task, aiming to propagate user edits that are made -- using any image editing tool -- on the first frame of a video to all subsequent frames, while ensuring content consistency between edited frames and source frames. To achieve this, prior methods employ DDIM inversion to transform source frames into latent noise, which is then fed into a pre-trained diffusion model, conditioned on the user-edited first frame, to generate the edited video. However, the DDIM inversion process accumulates errors, which hinder the latent noise from accurately reconstructing the source frames, ultimately compromising content consistency in the generated edited frames. To overcome it, our method eliminates the need for DDIM inversion by performing OCVE through a novel perspective based on visual prompting. Furthermore, inspired by consistency models that can perform multi-step consistency sampling to generate a sequence of content-consistent images, we propose a content consistency sampling (CCS) to ensure content consistency between the generated edited frames and the source frames. Moreover, we introduce a temporal-content consistency sampling (TCS) based on Stein Variational Gradient Descent to ensure temporal consistency across the edited frames. Extensive experiments validate the effectiveness of our approach.
MVGamba: Unify 3D Content Generation as State Space Sequence Modeling
Jun 10, 2024



Recent 3D large reconstruction models (LRMs) can generate high-quality 3D content in sub-seconds by integrating multi-view diffusion models with scalable multi-view reconstructors. Current works further leverage 3D Gaussian Splatting as 3D representation for improved visual quality and rendering efficiency. However, we observe that existing Gaussian reconstruction models often suffer from multi-view inconsistency and blurred textures. We attribute this to the compromise of multi-view information propagation in favor of adopting powerful yet computationally intensive architectures (\eg, Transformers). To address this issue, we introduce MVGamba, a general and lightweight Gaussian reconstruction model featuring a multi-view Gaussian reconstructor based on the RNN-like State Space Model (SSM). Our Gaussian reconstructor propagates causal context containing multi-view information for cross-view self-refinement while generating a long sequence of Gaussians for fine-detail modeling with linear complexity. With off-the-shelf multi-view diffusion models integrated, MVGamba unifies 3D generation tasks from a single image, sparse images, or text prompts. Extensive experiments demonstrate that MVGamba outperforms state-of-the-art baselines in all 3D content generation scenarios with approximately only $0.1\times$ of the model size.
Diffusion Time-step Curriculum for One Image to 3D Generation
Apr 11, 2024



Score distillation sampling~(SDS) has been widely adopted to overcome the absence of unseen views in reconstructing 3D objects from a \textbf{single} image. It leverages pre-trained 2D diffusion models as teacher to guide the reconstruction of student 3D models. Despite their remarkable success, SDS-based methods often encounter geometric artifacts and texture saturation. We find out the crux is the overlooked indiscriminate treatment of diffusion time-steps during optimization: it unreasonably treats the student-teacher knowledge distillation to be equal at all time-steps and thus entangles coarse-grained and fine-grained modeling. Therefore, we propose the Diffusion Time-step Curriculum one-image-to-3D pipeline (DTC123), which involves both the teacher and student models collaborating with the time-step curriculum in a coarse-to-fine manner. Extensive experiments on NeRF4, RealFusion15, GSO and Level50 benchmark demonstrate that DTC123 can produce multi-view consistent, high-quality, and diverse 3D assets. Codes and more generation demos will be released in https://github.com/yxymessi/DTC123.
Masked Diffusion with Task-awareness for Procedure Planning in Instructional Videos
Sep 14, 2023



A key challenge with procedure planning in instructional videos lies in how to handle a large decision space consisting of a multitude of action types that belong to various tasks. To understand real-world video content, an AI agent must proficiently discern these action types (e.g., pour milk, pour water, open lid, close lid, etc.) based on brief visual observation. Moreover, it must adeptly capture the intricate semantic relation of the action types and task goals, along with the variable action sequences. Recently, notable progress has been made via the integration of diffusion models and visual representation learning to address the challenge. However, existing models employ rudimentary mechanisms to utilize task information to manage the decision space. To overcome this limitation, we introduce a simple yet effective enhancement - a masked diffusion model. The introduced mask acts akin to a task-oriented attention filter, enabling the diffusion/denoising process to concentrate on a subset of action types. Furthermore, to bolster the accuracy of task classification, we harness more potent visual representation learning techniques. In particular, we learn a joint visual-text embedding, where a text embedding is generated by prompting a pre-trained vision-language model to focus on human actions. We evaluate the method on three public datasets and achieve state-of-the-art performance on multiple metrics. Code is available at https://github.com/ffzzy840304/Masked-PDPP.
Invariant Training 2D-3D Joint Hard Samples for Few-Shot Point Cloud Recognition
Aug 18, 2023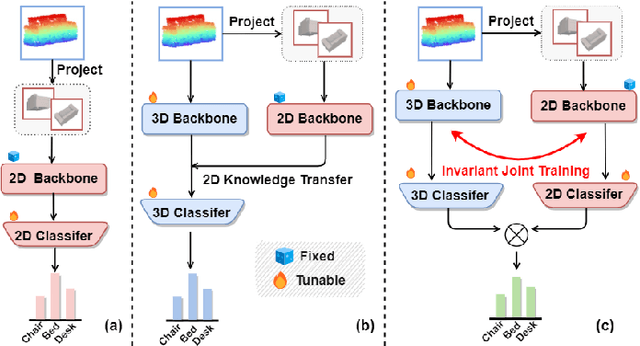
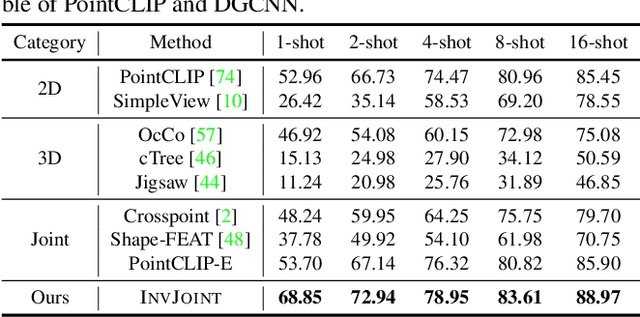
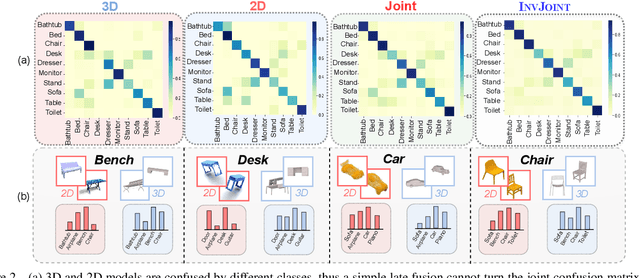
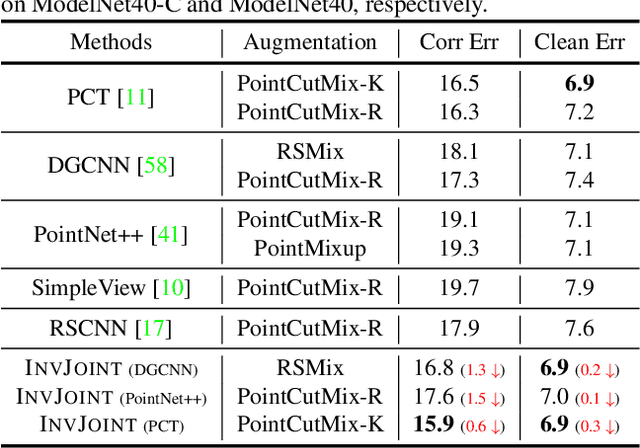
We tackle the data scarcity challenge in few-shot point cloud recognition of 3D objects by using a joint prediction from a conventional 3D model and a well-trained 2D model. Surprisingly, such an ensemble, though seems trivial, has hardly been shown effective in recent 2D-3D models. We find out the crux is the less effective training for the ''joint hard samples'', which have high confidence prediction on different wrong labels, implying that the 2D and 3D models do not collaborate well. To this end, our proposed invariant training strategy, called InvJoint, does not only emphasize the training more on the hard samples, but also seeks the invariance between the conflicting 2D and 3D ambiguous predictions. InvJoint can learn more collaborative 2D and 3D representations for better ensemble. Extensive experiments on 3D shape classification with widely adopted ModelNet10/40, ScanObjectNN and Toys4K, and shape retrieval with ShapeNet-Core validate the superiority of our InvJoint.
Keyword-Aware Relative Spatio-Temporal Graph Networks for Video Question Answering
Jul 25, 2023



The main challenge in video question answering (VideoQA) is to capture and understand the complex spatial and temporal relations between objects based on given questions. Existing graph-based methods for VideoQA usually ignore keywords in questions and employ a simple graph to aggregate features without considering relative relations between objects, which may lead to inferior performance. In this paper, we propose a Keyword-aware Relative Spatio-Temporal (KRST) graph network for VideoQA. First, to make question features aware of keywords, we employ an attention mechanism to assign high weights to keywords during question encoding. The keyword-aware question features are then used to guide video graph construction. Second, because relations are relative, we integrate the relative relation modeling to better capture the spatio-temporal dynamics among object nodes. Moreover, we disentangle the spatio-temporal reasoning into an object-level spatial graph and a frame-level temporal graph, which reduces the impact of spatial and temporal relation reasoning on each other. Extensive experiments on the TGIF-QA, MSVD-QA and MSRVTT-QA datasets demonstrate the superiority of our KRST over multiple state-of-the-art methods.
Identifying Hard Noise in Long-Tailed Sample Distribution
Jul 27, 2022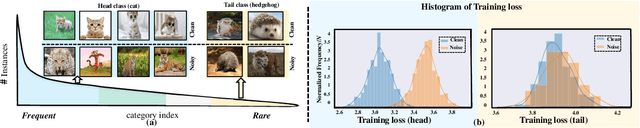

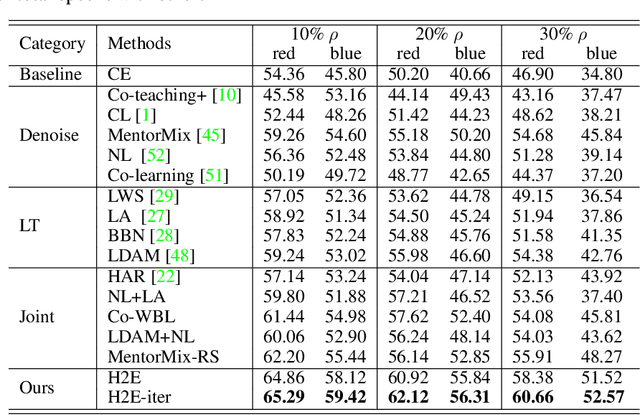
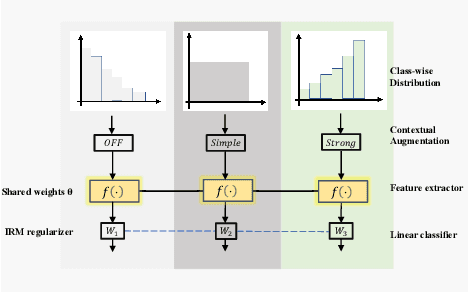
Conventional de-noising methods rely on the assumption that all samples are independent and identically distributed, so the resultant classifier, though disturbed by noise, can still easily identify the noises as the outliers of training distribution. However, the assumption is unrealistic in large-scale data that is inevitably long-tailed. Such imbalanced training data makes a classifier less discriminative for the tail classes, whose previously "easy" noises are now turned into "hard" ones -- they are almost as outliers as the clean tail samples. We introduce this new challenge as Noisy Long-Tailed Classification (NLT). Not surprisingly, we find that most de-noising methods fail to identify the hard noises, resulting in significant performance drop on the three proposed NLT benchmarks: ImageNet-NLT, Animal10-NLT, and Food101-NLT. To this end, we design an iterative noisy learning framework called Hard-to-Easy (H2E). Our bootstrapping philosophy is to first learn a classifier as noise identifier invariant to the class and context distributional changes, reducing "hard" noises to "easy" ones, whose removal further improves the invariance. Experimental results show that our H2E outperforms state-of-the-art de-noising methods and their ablations on long-tailed settings while maintaining a stable performance on the conventional balanced settings. Datasets and codes are available at https://github.com/yxymessi/H2E-Framework
TAILOR: Teaching with Active and Incremental Learning for Object Registration
May 24, 2022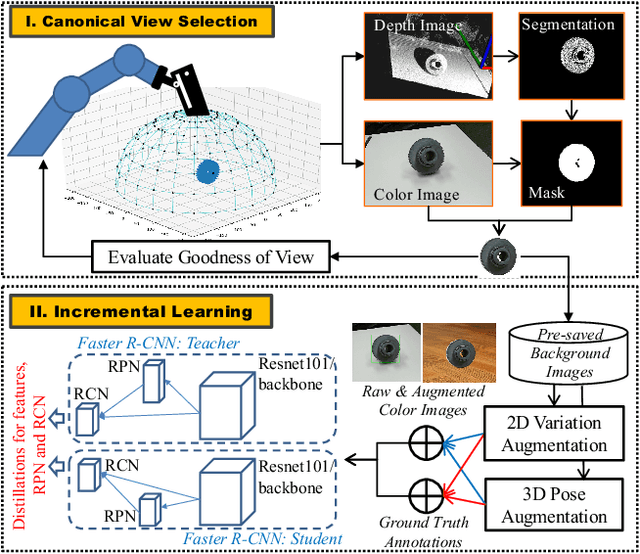
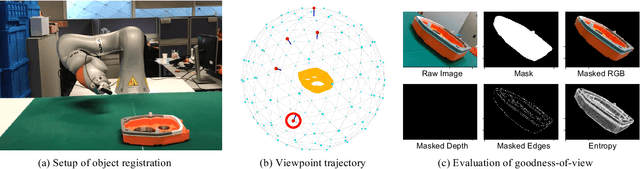

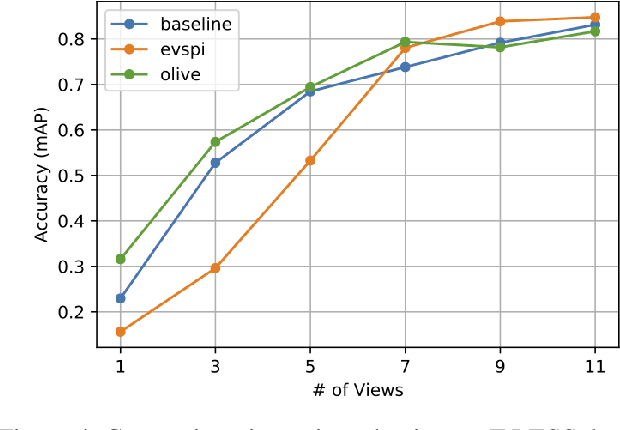
When deploying a robot to a new task, one often has to train it to detect novel objects, which is time-consuming and labor-intensive. We present TAILOR -- a method and system for object registration with active and incremental learning. When instructed by a human teacher to register an object, TAILOR is able to automatically select viewpoints to capture informative images by actively exploring viewpoints, and employs a fast incremental learning algorithm to learn new objects without potential forgetting of previously learned objects. We demonstrate the effectiveness of our method with a KUKA robot to learn novel objects used in a real-world gearbox assembly task through natural interactions.
6D Pose Estimation with Correlation Fusion
Sep 24, 2019
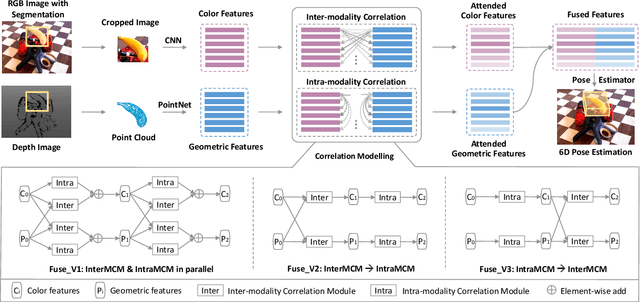
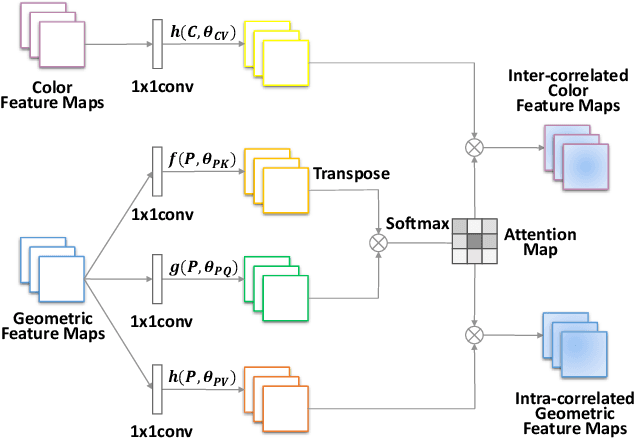

6D object pose estimation is widely applied in robotic tasks such as grasping and manipulation. Prior methods using RGB-only images are vulnerable to heavy occlusion and poor illumination, so it is important to complement them with depth information. However, existing methods using RGB-D data don't adequately exploit consistent and complementary information between two modalities. In this paper, we present a novel method to effectively consider the correlation within and across RGB and depth modalities with attention mechanism to learn discriminative multi-modal features. Then, effective fusion strategies for intra- and inter-correlation modules are explored to ensure efficient information flow between RGB and depth. To the best of our knowledge, this is the first work to explore effective intra- and inter-modality fusion in 6D pose estimation and experimental results show that our method can help achieve the state-of-the-art performance on LineMOD and YCB-Video datasets as well as benefit robot grasping task.