 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Test-Time Robustness of Vision-Language Models via Self-Critical Inference Framework
Mar 08, 2026The emergence of Large Language Models (LLMs) has driven rapid progress in multi-modal learning, particularly in the development of Large Vision-Language Models (LVLMs). However, existing LVLM training paradigms place excessive reliance on the LLM component, giving rise to two critical robustness challenges: language bias and language sensitivity. To address both issues simultaneously, we propose a novel Self-Critical Inference (SCI) framework that extends Visual Contrastive Decoding by conducting multi-round counterfactual reasoning through both textual and visual perturbations. This process further introduces a new strategy for improving robustness by scaling the number of counterfactual rounds. Moreover, we also observe that failure cases of LVLMs differ significantly across models, indicating that fixed robustness benchmarks may not be able to capture the true reliability of LVLMs. To this end, we propose the Dynamic Robustness Benchmark (DRBench), a model-specific evaluation framework targeting both language bias and sensitivity issues. Extensive experiments show that SCI consistently outperforms baseline methods on DRBench, and that increasing the number of inference rounds further boosts robustness beyond existing single-step counterfactual reasoning methods.
HiFloat4 Format for Language Model Inference
Feb 13, 2026This paper introduces HiFloat4 (HiF4), a block floating-point data format tailored for deep learning. Each HiF4 unit packs 64 4-bit elements with 32 bits of shared scaling metadata, averaging 4.5 bits per value. The metadata specifies a three-level scaling hierarchy, capturing inter- and intra-group dynamic range while improving the utilization of the representational space. In addition, the large 64-element group size enables matrix multiplications to be executed in a highly fixed-point manner, significantly reducing hardware area and power consumption. To evaluate the proposed format, we conducted inference experiments on several language models, including LLaMA, Qwen, Mistral, DeepSeek-V3.1 and LongCat. Results show that HiF4 achieves higher average accuracy than the state-of-the-art NVFP4 format across multiple models and diverse downstream tasks.
Enhancing Multimodal In-Context Learning for Image Classification through Coreset Optimization
Apr 19, 2025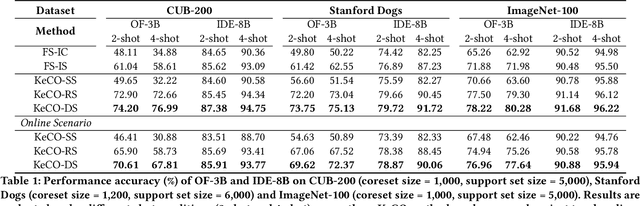
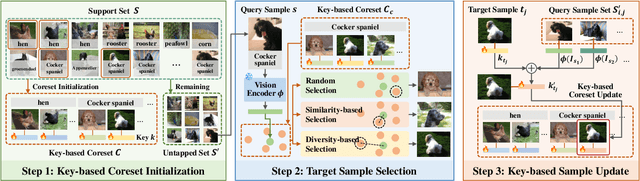

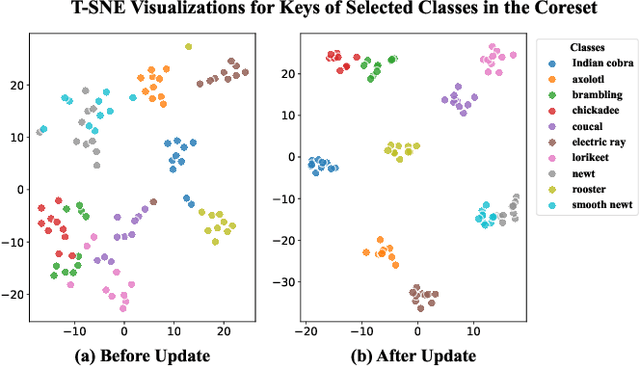
In-context learning (ICL) enables Large Vision-Language Models (LVLMs) to adapt to new tasks without parameter updates, using a few demonstrations from a large support set. However, selecting informative demonstrations leads to high computational and memory costs. While some methods explore selecting a small and representative coreset in the text classification, evaluating all support set samples remains costly, and discarded samples lead to unnecessary information loss. These methods may also be less effective for image classification due to differences in feature spaces. Given these limitations, we propose Key-based Coreset Optimization (KeCO), a novel framework that leverages untapped data to construct a compact and informative coreset. We introduce visual features as keys within the coreset, which serve as the anchor for identifying samples to be updated through different selection strategies. By leveraging untapped samples from the support set, we update the keys of selected coreset samples, enabling the randomly initialized coreset to evolve into a more informative coreset under low computational cost. Through extensive experiments on coarse-grained and fine-grained image classification benchmarks, we demonstrate that KeCO effectively enhances ICL performance for image classification task, achieving an average improvement of more than 20\%. Notably, we evaluate KeCO under a simulated online scenario, and the strong performance in this scenario highlights the practical value of our framework for resource-constrained real-world scenarios.
Generalized Logit Adjustment: Calibrating Fine-tuned Models by Removing Label Bias in Foundation Models
Oct 12, 2023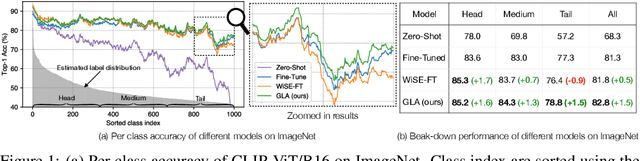
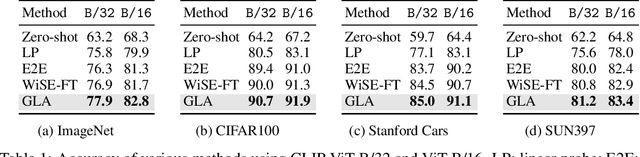
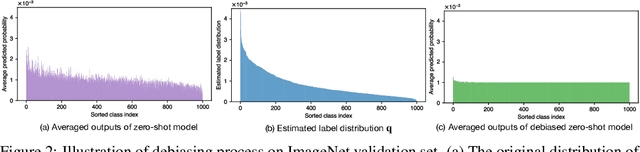
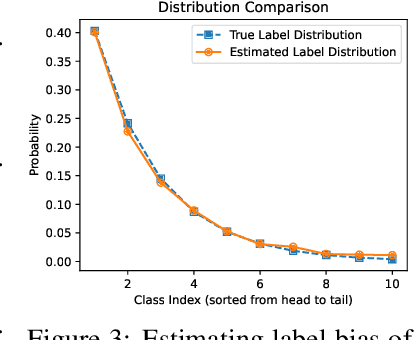
Foundation models like CLIP allow zero-shot transfer on various tasks without additional training data. Yet, the zero-shot performance is less competitive than a fully supervised one. Thus, to enhance the performance, fine-tuning and ensembling are also commonly adopted to better fit the downstream tasks. However, we argue that such prior work has overlooked the inherent biases in foundation models. Due to the highly imbalanced Web-scale training set, these foundation models are inevitably skewed toward frequent semantics, and thus the subsequent fine-tuning or ensembling is still biased. In this study, we systematically examine the biases in foundation models and demonstrate the efficacy of our proposed Generalized Logit Adjustment (GLA) method. Note that bias estimation in foundation models is challenging, as most pre-train data cannot be explicitly accessed like in traditional long-tailed classification tasks. To this end, GLA has an optimization-based bias estimation approach for debiasing foundation models. As our work resolves a fundamental flaw in the pre-training, the proposed GLA demonstrates significant improvements across a diverse range of tasks: it achieves 1.5 pp accuracy gains on ImageNet, an large average improvement (1.4-4.6 pp) on 11 few-shot datasets, 2.4 pp gains on long-tailed classification. Codes are in \url{https://github.com/BeierZhu/GLA}.
Class Is Invariant to Context and Vice Versa: On Learning Invariance for Out-Of-Distribution Generalization
Aug 06, 2022
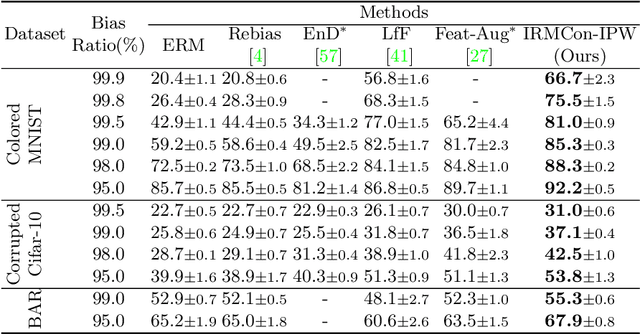
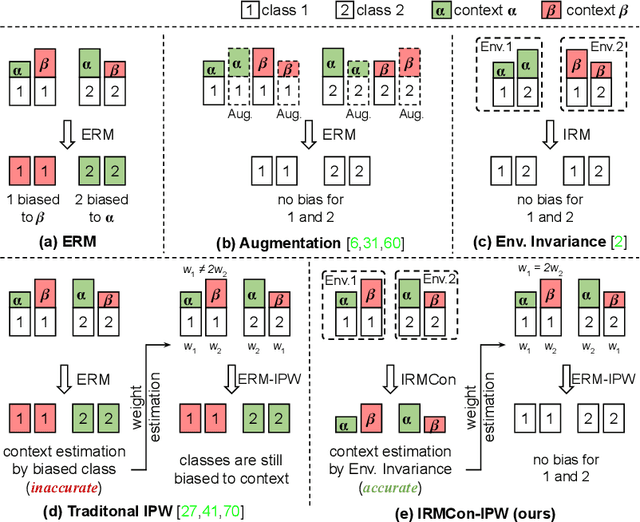
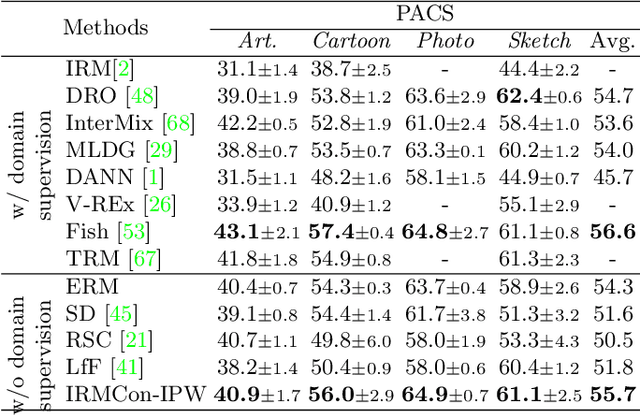
Out-Of-Distribution generalization (OOD) is all about learning invariance against environmental changes. If the context in every class is evenly distributed, OOD would be trivial because the context can be easily removed due to an underlying principle: class is invariant to context. However, collecting such a balanced dataset is impractical. Learning on imbalanced data makes the model bias to context and thus hurts OOD. Therefore, the key to OOD is context balance. We argue that the widely adopted assumption in prior work, the context bias can be directly annotated or estimated from biased class prediction, renders the context incomplete or even incorrect. In contrast, we point out the everoverlooked other side of the above principle: context is also invariant to class, which motivates us to consider the classes (which are already labeled) as the varying environments to resolve context bias (without context labels). We implement this idea by minimizing the contrastive loss of intra-class sample similarity while assuring this similarity to be invariant across all classes. On benchmarks with various context biases and domain gaps, we show that a simple re-weighting based classifier equipped with our context estimation achieves state-of-the-art performance. We provide the theoretical justifications in Appendix and codes on https://github.com/simpleshinobu/IRMCon.
Identifying Hard Noise in Long-Tailed Sample Distribution
Jul 27, 2022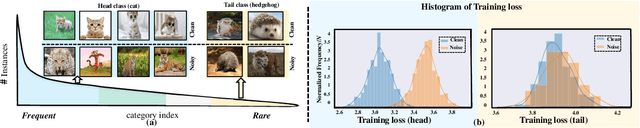

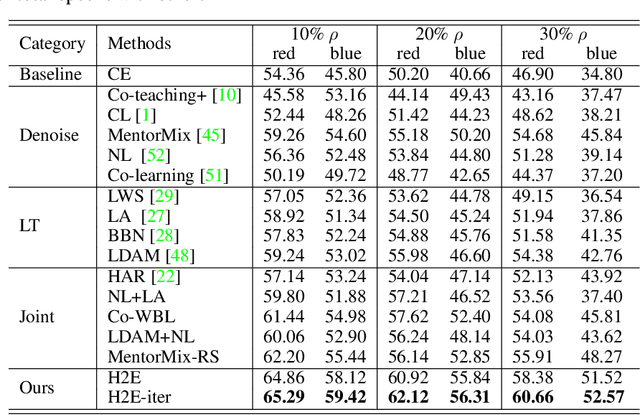
Conventional de-noising methods rely on the assumption that all samples are independent and identically distributed, so the resultant classifier, though disturbed by noise, can still easily identify the noises as the outliers of training distribution. However, the assumption is unrealistic in large-scale data that is inevitably long-tailed. Such imbalanced training data makes a classifier less discriminative for the tail classes, whose previously "easy" noises are now turned into "hard" ones -- they are almost as outliers as the clean tail samples. We introduce this new challenge as Noisy Long-Tailed Classification (NLT). Not surprisingly, we find that most de-noising methods fail to identify the hard noises, resulting in significant performance drop on the three proposed NLT benchmarks: ImageNet-NLT, Animal10-NLT, and Food101-NLT. To this end, we design an iterative noisy learning framework called Hard-to-Easy (H2E). Our bootstrapping philosophy is to first learn a classifier as noise identifier invariant to the class and context distributional changes, reducing "hard" noises to "easy" ones, whose removal further improves the invariance. Experimental results show that our H2E outperforms state-of-the-art de-noising methods and their ablations on long-tailed settings while maintaining a stable performance on the conventional balanced settings. Datasets and codes are available at https://github.com/yxymessi/H2E-Framework
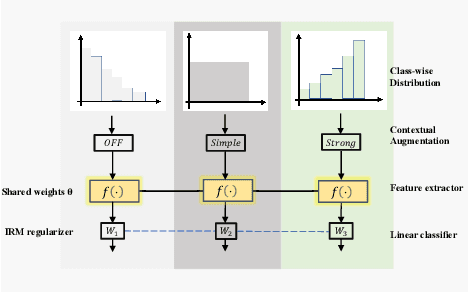
Invariant Feature Learning for Generalized Long-Tailed Classification
Jul 19, 2022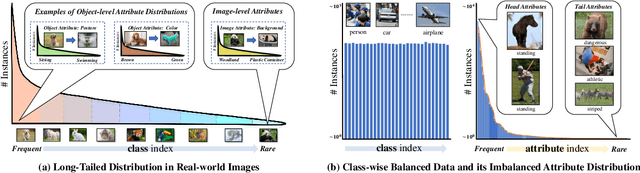
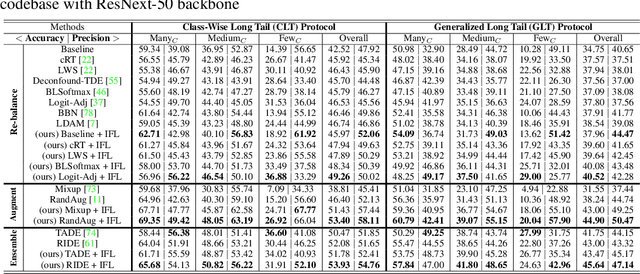


Existing long-tailed classification (LT) methods only focus on tackling the class-wise imbalance that head classes have more samples than tail classes, but overlook the attribute-wise imbalance. In fact, even if the class is balanced, samples within each class may still be long-tailed due to the varying attributes. Note that the latter is fundamentally more ubiquitous and challenging than the former because attributes are not just implicit for most datasets, but also combinatorially complex, thus prohibitively expensive to be balanced. Therefore, we introduce a novel research problem: Generalized Long-Tailed classification (GLT), to jointly consider both kinds of imbalances. By "generalized", we mean that a GLT method should naturally solve the traditional LT, but not vice versa. Not surprisingly, we find that most class-wise LT methods degenerate in our proposed two benchmarks: ImageNet-GLT and MSCOCO-GLT. We argue that it is because they over-emphasize the adjustment of class distribution while neglecting to learn attribute-invariant features. To this end, we propose an Invariant Feature Learning (IFL) method as the first strong baseline for GLT. IFL first discovers environments with divergent intra-class distributions from the imperfect predictions and then learns invariant features across them. Promisingly, as an improved feature backbone, IFL boosts all the LT line-up: one/two-stage re-balance, augmentation, and ensemble. Codes and benchmarks are available on Github: https://github.com/KaihuaTang/Generalized-Long-Tailed-Benchmarks.pytorch
Adversarial Visual Robustness by Causal Intervention
Jun 17, 2021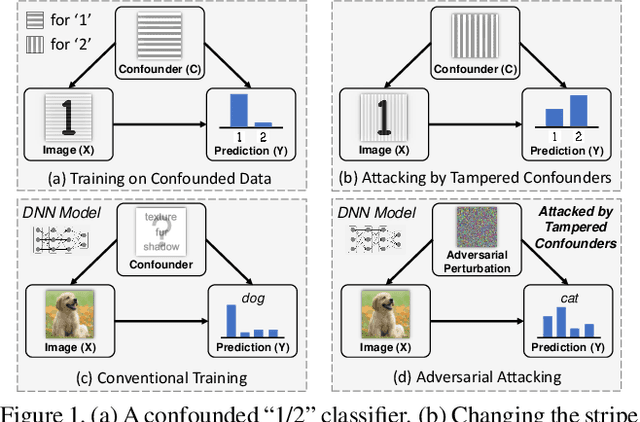
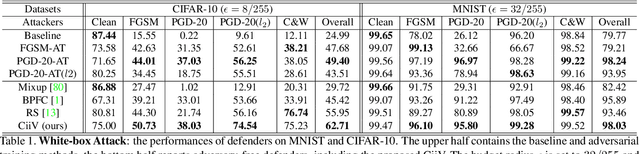
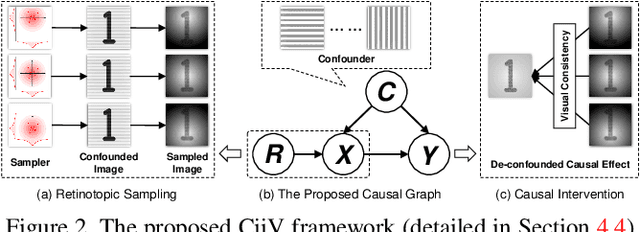
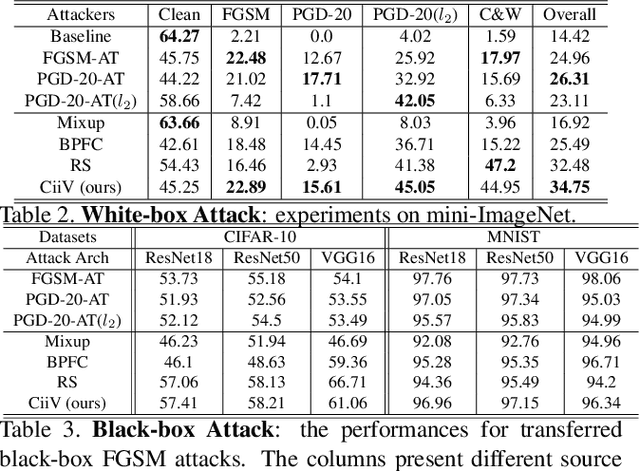
Adversarial training is the de facto most promising defense against adversarial examples. Yet, its passive nature inevitably prevents it from being immune to unknown attackers. To achieve a proactive defense, we need a more fundamental understanding of adversarial examples, beyond the popular bounded threat model. In this paper, we provide a causal viewpoint of adversarial vulnerability: the cause is the confounder ubiquitously existing in learning, where attackers are precisely exploiting the confounding effect. Therefore, a fundamental solution for adversarial robustness is causal intervention. As the confounder is unobserved in general, we propose to use the instrumental variable that achieves intervention without the need for confounder observation. We term our robust training method as Causal intervention by instrumental Variable (CiiV). It has a differentiable retinotopic sampling layer and a consistency loss, which is stable and guaranteed not to suffer from gradient obfuscation. Extensive experiments on a wide spectrum of attackers and settings applied in MNIST, CIFAR-10, and mini-ImageNet datasets empirically demonstrate that CiiV is robust to adaptive attacks.
Distilling Causal Effect of Data in Class-Incremental Learning
Mar 08, 2021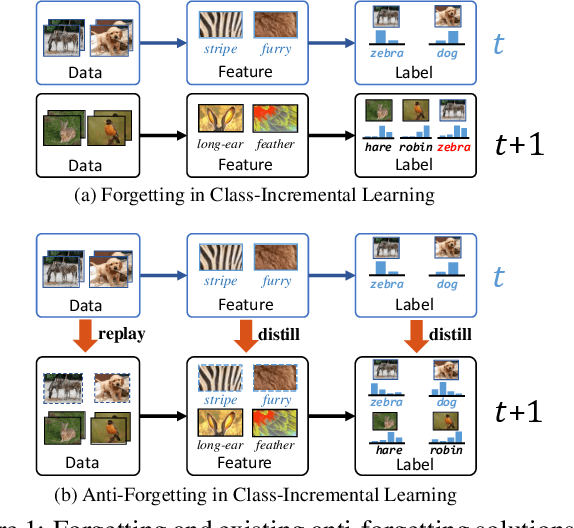
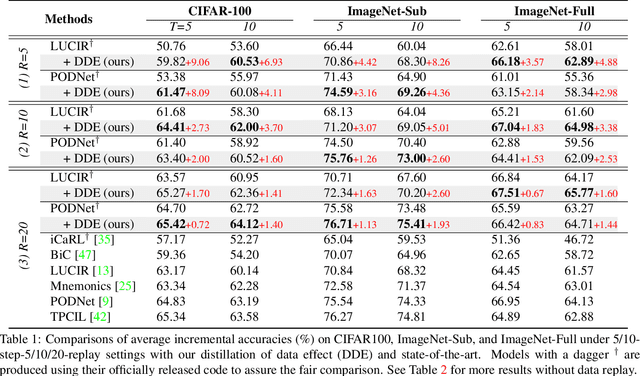
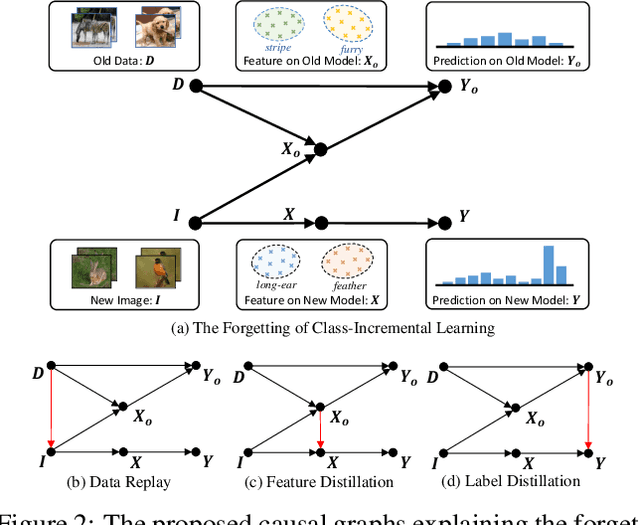
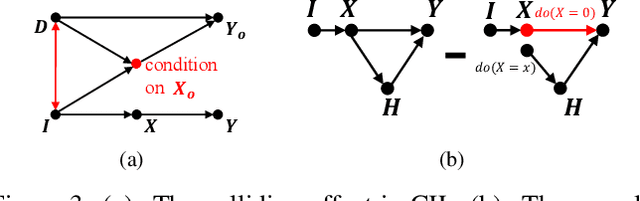
We propose a causal framework to explain the catastrophic forgetting in Class-Incremental Learning (CIL) and then derive a novel distillation method that is orthogonal to the existing anti-forgetting techniques, such as data replay and feature/label distillation. We first 1) place CIL into the framework, 2) answer why the forgetting happens: the causal effect of the old data is lost in new training, and then 3) explain how the existing techniques mitigate it: they bring the causal effect back. Based on the framework, we find that although the feature/label distillation is storage-efficient, its causal effect is not coherent with the end-to-end feature learning merit, which is however preserved by data replay. To this end, we propose to distill the Colliding Effect between the old and the new data, which is fundamentally equivalent to the causal effect of data replay, but without any cost of replay storage. Thanks to the causal effect analysis, we can further capture the Incremental Momentum Effect of the data stream, removing which can help to retain the old effect overwhelmed by the new data effect, and thus alleviate the forgetting of the old class in testing. Extensive experiments on three CIL benchmarks: CIFAR-100, ImageNet-Sub&Full, show that the proposed causal effect distillation can improve various state-of-the-art CIL methods by a large margin (0.72%--9.06%).
Long-Tailed Classification by Keeping the Good and Removing the Bad Momentum Causal Effect
Oct 03, 2020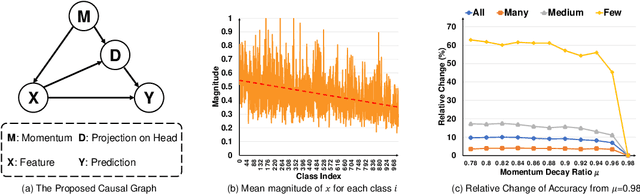

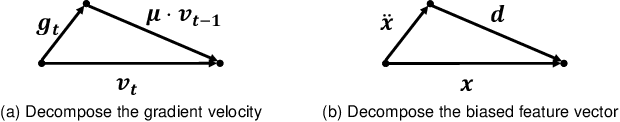
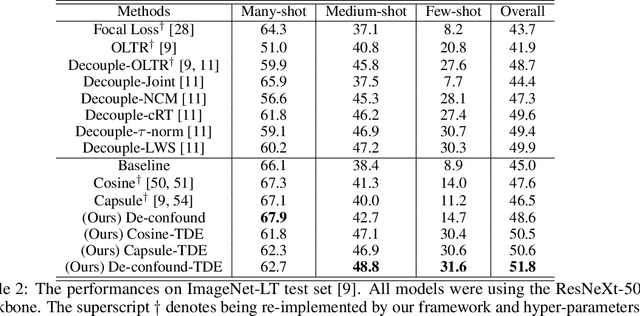
As the class size grows, maintaining a balanced dataset across many classes is challenging because the data are long-tailed in nature; it is even impossible when the sample-of-interest co-exists with each other in one collectable unit, e.g., multiple visual instances in one image. Therefore, long-tailed classification is the key to deep learning at scale. However, existing methods are mainly based on re-weighting/re-sampling heuristics that lack a fundamental theory. In this paper, we establish a causal inference framework, which not only unravels the whys of previous methods, but also derives a new principled solution. Specifically, our theory shows that the SGD momentum is essentially a confounder in long-tailed classification. On one hand, it has a harmful causal effect that misleads the tail prediction biased towards the head. On the other hand, its induced mediation also benefits the representation learning and head prediction. Our framework elegantly disentangles the paradoxical effects of the momentum, by pursuing the direct causal effect caused by an input sample. In particular, we use causal intervention in training, and counterfactual reasoning in inference, to remove the "bad" while keep the "good". We achieve new state-of-the-arts on three long-tailed visual recognition benchmarks: Long-tailed CIFAR-10/-100, ImageNet-LT for image classification and LVIS for instance segmentation.