 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Logit Adjustment: Calibrating Fine-tuned Models by Removing Label Bias in Foundation Models
Paper and Code
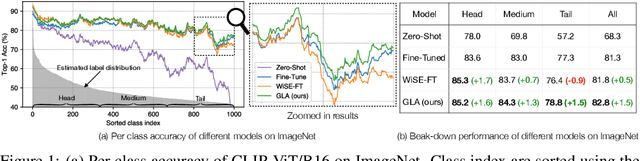
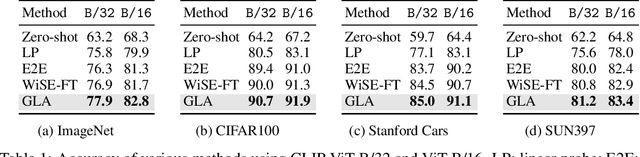
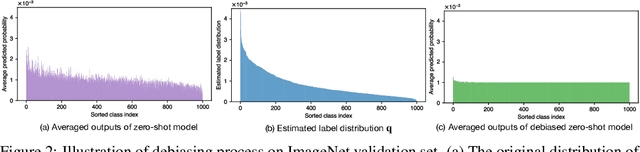
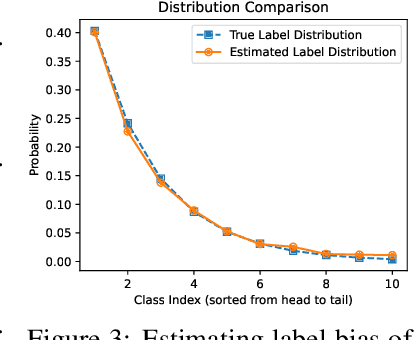
Foundation models like CLIP allow zero-shot transfer on various tasks without additional training data. Yet, the zero-shot performance is less competitive than a fully supervised one. Thus, to enhance the performance, fine-tuning and ensembling are also commonly adopted to better fit the downstream tasks. However, we argue that such prior work has overlooked the inherent biases in foundation models. Due to the highly imbalanced Web-scale training set, these foundation models are inevitably skewed toward frequent semantics, and thus the subsequent fine-tuning or ensembling is still biased. In this study, we systematically examine the biases in foundation models and demonstrate the efficacy of our proposed Generalized Logit Adjustment (GLA) method. Note that bias estimation in foundation models is challenging, as most pre-train data cannot be explicitly accessed like in traditional long-tailed classification tasks. To this end, GLA has an optimization-based bias estimation approach for debiasing foundation models. As our work resolves a fundamental flaw in the pre-training, the proposed GLA demonstrates significant improvements across a diverse range of tasks: it achieves 1.5 pp accuracy gains on ImageNet, an large average improvement (1.4-4.6 pp) on 11 few-shot datasets, 2.4 pp gains on long-tailed classification. Codes are in \url{https://github.com/BeierZhu/GLA}.