 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Hard Noise in Long-Tailed Sample Distribution
Paper and Code
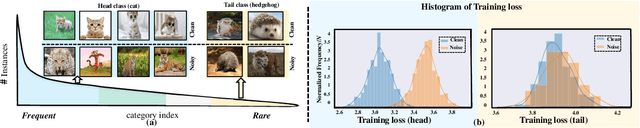

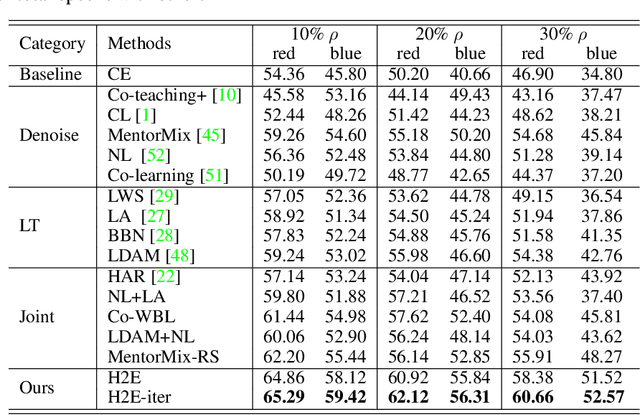
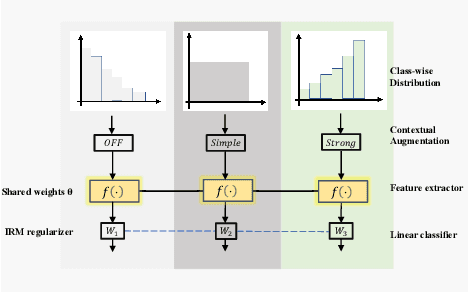
Conventional de-noising methods rely on the assumption that all samples are independent and identically distributed, so the resultant classifier, though disturbed by noise, can still easily identify the noises as the outliers of training distribution. However, the assumption is unrealistic in large-scale data that is inevitably long-tailed. Such imbalanced training data makes a classifier less discriminative for the tail classes, whose previously "easy" noises are now turned into "hard" ones -- they are almost as outliers as the clean tail samples. We introduce this new challenge as Noisy Long-Tailed Classification (NLT). Not surprisingly, we find that most de-noising methods fail to identify the hard noises, resulting in significant performance drop on the three proposed NLT benchmarks: ImageNet-NLT, Animal10-NLT, and Food101-NLT. To this end, we design an iterative noisy learning framework called Hard-to-Easy (H2E). Our bootstrapping philosophy is to first learn a classifier as noise identifier invariant to the class and context distributional changes, reducing "hard" noises to "easy" ones, whose removal further improves the invariance. Experimental results show that our H2E outperforms state-of-the-art de-noising methods and their ablations on long-tailed settings while maintaining a stable performance on the conventional balanced settings. Datasets and codes are available at https://github.com/yxymessi/H2E-Framework