 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperience is the Best Teacher: Motivating Effective Exploration in Reinforcement Learning for LLMs
Mar 20, 2026Reinforcement Learning (RL) with rubric-based rewards has recently shown remarkable progress in enhancing general reasoning capabilities of Large Language Models (LLMs), yet still suffers from ineffective exploration confined to curent policy distribution. In fact, RL optimization can be viewed as steering the policy toward an ideal distribution that maximizes the rewards, while effective exploration should align efforts with desired target. Leveraging this insight, we propose HeRL, a Hindsight experience guided Reinforcement Learning framework to bootstrap effective exploration by explicitly telling LLMs the desired behaviors specified in rewards. Concretely, HeRL treats failed trajectories along with their unmet rubrics as hindsight experience, which serves as in-context guidance for the policy to explore desired responses beyond its current distribution. Additionally, we introduce a bonus reward to incentivize responses with greater potential for improvement under such guidance. HeRL facilitates effective learning from desired high quality samples without repeated trial-and-error from scratch, yielding a more accurate estimation of the expected gradient theoretically. Extensive experiments across various benchmarks demonstrate that HeRL achieves superior performance gains over baselines, and can further benefit from experience guided self-improvement at test time. Our code is available at https://github.com/sikelifei/HeRL.
Spatial Transcriptomics as Images for Large-Scale Pretraining
Mar 18, 2026Spatial Transcriptomics (ST) profiles thousands of gene expression values at discrete spots with precise coordinates on tissue sections, preserving spatial context essential for clinical and pathological studies. With rising sequencing throughput and advancing platforms, the expanding data volumes motivate large-scale ST pretraining. However, the fundamental unit for pretraining, i.e., what constitutes a single training sample, remains ill-posed. Existing choices fall into two camps: (1) treating each spot as an independent sample, which discards spatial dependencies and collapses ST into single-cell transcriptomics; and (2) treating an entire slide as a single sample, which produces prohibitively large inputs and drastically fewer training examples, undermining effective pretraining. To address this gap, we propose treating spatial transcriptomics as croppable images. Specifically, we define a multi-channel image representation with fixed spatial size by cropping patches from raw slides, thereby preserving spatial context while substantially increasing the number of training samples. Along the channel dimension, we define gene subset selection rules to control input dimensionality and improve pretraining stability. Extensive experiments show that the proposed image-like dataset construction for ST pretraining consistently improves downstream performance, outperforming conventional pretraining schemes. Ablation studies verify that both spatial patching and channel design are necessary, establishing a unified, practical paradigm for organizing ST data and enabling large-scale pretraining.
Scaling Test-Time Robustness of Vision-Language Models via Self-Critical Inference Framework
Mar 08, 2026The emergence of Large Language Models (LLMs) has driven rapid progress in multi-modal learning, particularly in the development of Large Vision-Language Models (LVLMs). However, existing LVLM training paradigms place excessive reliance on the LLM component, giving rise to two critical robustness challenges: language bias and language sensitivity. To address both issues simultaneously, we propose a novel Self-Critical Inference (SCI) framework that extends Visual Contrastive Decoding by conducting multi-round counterfactual reasoning through both textual and visual perturbations. This process further introduces a new strategy for improving robustness by scaling the number of counterfactual rounds. Moreover, we also observe that failure cases of LVLMs differ significantly across models, indicating that fixed robustness benchmarks may not be able to capture the true reliability of LVLMs. To this end, we propose the Dynamic Robustness Benchmark (DRBench), a model-specific evaluation framework targeting both language bias and sensitivity issues. Extensive experiments show that SCI consistently outperforms baseline methods on DRBench, and that increasing the number of inference rounds further boosts robustness beyond existing single-step counterfactual reasoning methods.
CCCaption: Dual-Reward Reinforcement Learning for Complete and Correct Image Captioning
Feb 25, 2026Image captioning remains a fundamental task for vision language understanding, yet ground-truth supervision still relies predominantly on human-annotated references. Because human annotations reflect subjective preferences and expertise, ground-truth captions are often incomplete or even incorrect, which in turn limits caption models. We argue that caption quality should be assessed by two objective aspects: completeness (does the caption cover all salient visual facts?) and correctness (are the descriptions true with respect to the image?). To this end, we introduce CCCaption: a dual-reward reinforcement learning framework with a dedicated fine-tuning corpus that explicitly optimizes these properties to generate \textbf{C}omplete and \textbf{C}orrect \textbf{Captions}. For completeness, we use diverse LVLMs to disentangle the image into a set of visual queries, and reward captions that answer more of these queries, with a dynamic query sampling strategy to improve training efficiency. For correctness, we penalize captions that contain hallucinations by validating the authenticity of sub-caption queries, which are derived from the caption decomposition. Our symmetric dual-reward optimization jointly maximizes completeness and correctness, guiding models toward captions that better satisfy these objective criteria. Extensive experiments across standard captioning benchmarks show consistent improvements, offering a principled path to training caption models beyond human-annotation imitation.
Gene Incremental Learning for Single-Cell Transcriptomics
Nov 14, 2025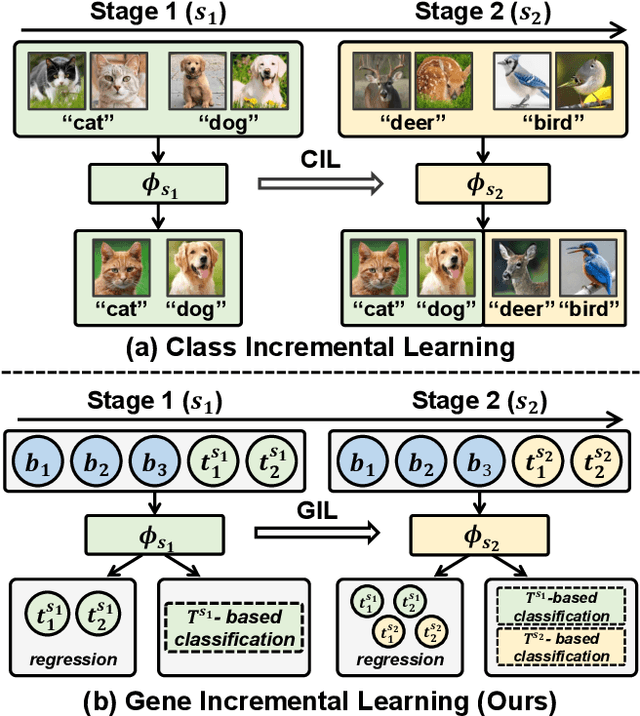
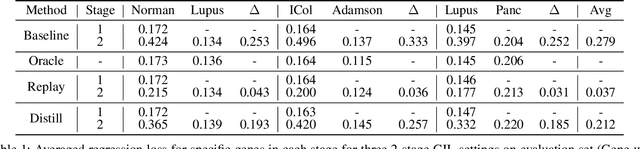
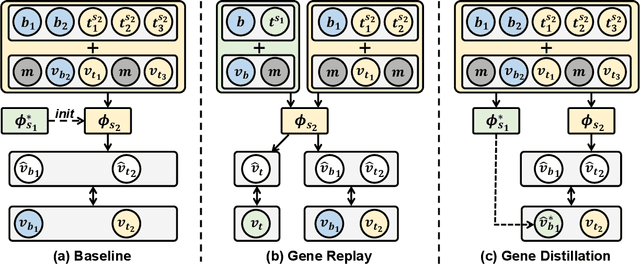
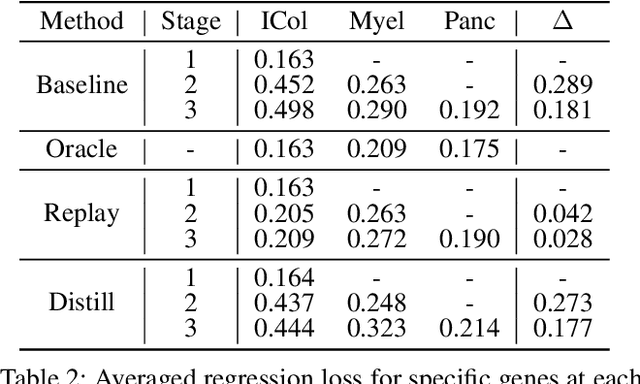
Classes, as fundamental elements of Computer Vision, have been extensively studied within incremental learning frameworks. In contrast, tokens, which play essential roles in many research fields, exhibit similar characteristics of growth, yet investigations into their incremental learning remain significantly scarce. This research gap primarily stems from the holistic nature of tokens in language, which imposes significant challenges on the design of incremental learning frameworks for them. To overcome this obstacle, in this work, we turn to a type of token, gene, for a large-scale biological dataset--single-cell transcriptomics--to formulate a pipeline for gene incremental learning and establish corresponding evaluations. We found that the forgetting problem also exists in gene incremental learning, thus we adapted existing class incremental learning methods to mitigate the forgetting of genes. Through extensive experiments, we demonstrated the soundness of our framework design and evaluations, as well as the effectiveness of our method adaptations. Finally, we provide a complete benchmark for gene incremental learning in single-cell transcriptomics.
Class Is Invariant to Context and Vice Versa: On Learning Invariance for Out-Of-Distribution Generalization
Aug 06, 2022
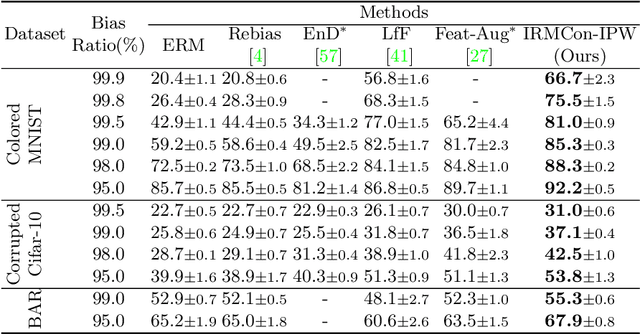
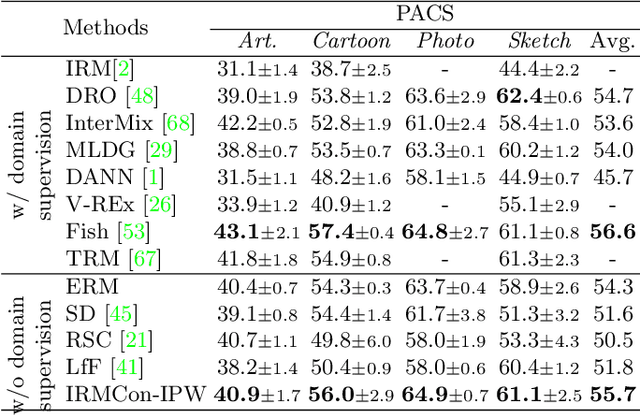
Out-Of-Distribution generalization (OOD) is all about learning invariance against environmental changes. If the context in every class is evenly distributed, OOD would be trivial because the context can be easily removed due to an underlying principle: class is invariant to context. However, collecting such a balanced dataset is impractical. Learning on imbalanced data makes the model bias to context and thus hurts OOD. Therefore, the key to OOD is context balance. We argue that the widely adopted assumption in prior work, the context bias can be directly annotated or estimated from biased class prediction, renders the context incomplete or even incorrect. In contrast, we point out the everoverlooked other side of the above principle: context is also invariant to class, which motivates us to consider the classes (which are already labeled) as the varying environments to resolve context bias (without context labels). We implement this idea by minimizing the contrastive loss of intra-class sample similarity while assuring this similarity to be invariant across all classes. On benchmarks with various context biases and domain gaps, we show that a simple re-weighting based classifier equipped with our context estimation achieves state-of-the-art performance. We provide the theoretical justifications in Appendix and codes on https://github.com/simpleshinobu/IRMCon.
Invariant Feature Learning for Generalized Long-Tailed Classification
Jul 19, 2022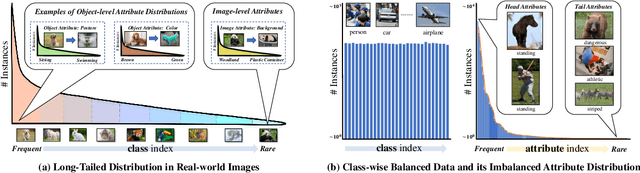
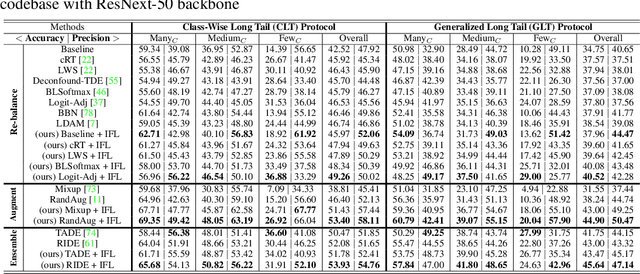


Existing long-tailed classification (LT) methods only focus on tackling the class-wise imbalance that head classes have more samples than tail classes, but overlook the attribute-wise imbalance. In fact, even if the class is balanced, samples within each class may still be long-tailed due to the varying attributes. Note that the latter is fundamentally more ubiquitous and challenging than the former because attributes are not just implicit for most datasets, but also combinatorially complex, thus prohibitively expensive to be balanced. Therefore, we introduce a novel research problem: Generalized Long-Tailed classification (GLT), to jointly consider both kinds of imbalances. By "generalized", we mean that a GLT method should naturally solve the traditional LT, but not vice versa. Not surprisingly, we find that most class-wise LT methods degenerate in our proposed two benchmarks: ImageNet-GLT and MSCOCO-GLT. We argue that it is because they over-emphasize the adjustment of class distribution while neglecting to learn attribute-invariant features. To this end, we propose an Invariant Feature Learning (IFL) method as the first strong baseline for GLT. IFL first discovers environments with divergent intra-class distributions from the imperfect predictions and then learns invariant features across them. Promisingly, as an improved feature backbone, IFL boosts all the LT line-up: one/two-stage re-balance, augmentation, and ensemble. Codes and benchmarks are available on Github: https://github.com/KaihuaTang/Generalized-Long-Tailed-Benchmarks.pytorch
Deconfounded Visual Grounding
Dec 31, 2021



We focus on the confounding bias between language and location in the visual grounding pipeline, where we find that the bias is the major visual reasoning bottleneck. For example, the grounding process is usually a trivial language-location association without visual reasoning, e.g., grounding any language query containing sheep to the nearly central regions, due to that most queries about sheep have ground-truth locations at the image center. First, we frame the visual grounding pipeline into a causal graph, which shows the causalities among image, query, target location and underlying confounder. Through the causal graph, we know how to break the grounding bottleneck: deconfounded visual grounding. Second, to tackle the challenge that the confounder is unobserved in general, we propose a confounder-agnostic approach called: Referring Expression Deconfounder (RED), to remove the confounding bias. Third, we implement RED as a simple language attention, which can be applied in any grounding method. On popular benchmarks, RED improves various state-of-the-art grounding methods by a significant margin. Code will soon be available at: https://github.com/JianqiangH/Deconfounded_VG.
Two Causal Principles for Improving Visual Dialog
Nov 24, 2019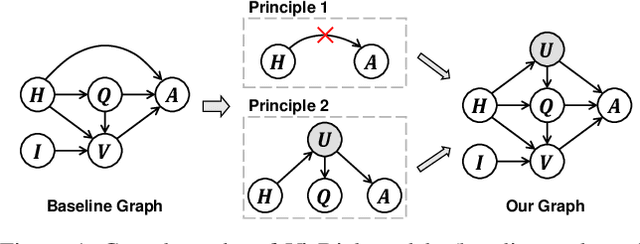
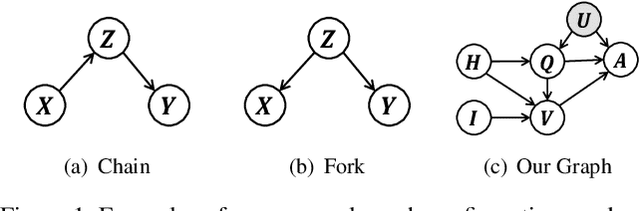

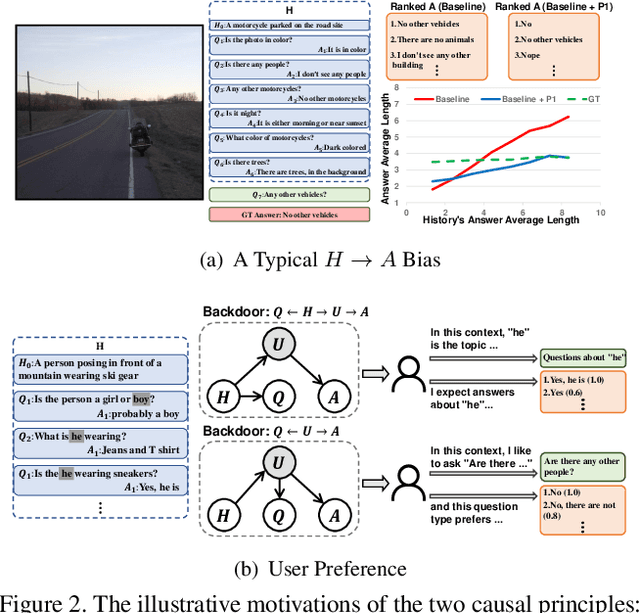
This paper is a winner report from team MReaL-BDAI for Visual Dialog Challenge 2019. We present two causal principles for improving Visual Dialog (VisDial). By "improving", we mean that they can promote almost every existing VisDial model to the state-of-the-art performance on Visual Dialog 2019 Challenge leader-board. Such a major improvement is only due to our careful inspection on the causality behind the model and data, finding that the community has overlooked two causalities in VisDial. Intuitively, Principle 1 suggests: we should remove the direct input of the dialog history to the answer model, otherwise the harmful shortcut bias will be introduced; Principle 2 says: there is an unobserved confounder for history, question, and answer, leading to spurious correlations from training data. In particular, to remove the confounder suggested in Principle 2, we propose several causal intervention algorithms, which make the training fundamentally different from the traditional likelihood estimation. Note that the two principles are model-agnostic, so they are applicable in any VisDial model.