 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEMON: Local Explanations via Modality-aware OptimizatioN
Feb 02, 2026Multimodal models are ubiquitous, yet existing explainability methods are often single-modal, architecture-dependent, or too computationally expensive to run at scale. We introduce LEMON (Local Explanations via Modality-aware OptimizatioN), a model-agnostic framework for local explanations of multimodal predictions. LEMON fits a single modality-aware surrogate with group-structured sparsity to produce unified explanations that disentangle modality-level contributions and feature-level attributions. The approach treats the predictor as a black box and is computationally efficient, requiring relatively few forward passes while remaining faithful under repeated perturbations. We evaluate LEMON on vision-language question answering and a clinical prediction task with image, text, and tabular inputs, comparing against representative multimodal baselines. Across backbones, LEMON achieves competitive deletion-based faithfulness while reducing black-box evaluations by 35-67 times and runtime by 2-8 times compared to strong multimodal baselines.
Learning Fine-Grained Correspondence with Cross-Perspective Perception for Open-Vocabulary 6D Object Pose Estimation
Jan 20, 2026Open-vocabulary 6D object pose estimation empowers robots to manipulate arbitrary unseen objects guided solely by natural language. However, a critical limitation of existing approaches is their reliance on unconstrained global matching strategies. In open-world scenarios, trying to match anchor features against the entire query image space introduces excessive ambiguity, as target features are easily confused with background distractors. To resolve this, we propose Fine-grained Correspondence Pose Estimation (FiCoP), a framework that transitions from noise-prone global matching to spatially-constrained patch-level correspondence. Our core innovation lies in leveraging a patch-to-patch correlation matrix as a structural prior to narrowing the matching scope, effectively filtering out irrelevant clutter to prevent it from degrading pose estimation. Firstly, we introduce an object-centric disentanglement preprocessing to isolate the semantic target from environmental noise. Secondly, a Cross-Perspective Global Perception (CPGP) module is proposed to fuse dual-view features, establishing structural consensus through explicit context reasoning. Finally, we design a Patch Correlation Predictor (PCP) that generates a precise block-wise association map, acting as a spatial filter to enforce fine-grained, noise-resilient matching. Experiments on the REAL275 and Toyota-Light datasets demonstrate that FiCoP improves Average Recall by 8.0% and 6.1%, respectively, compared to the state-of-the-art method, highlighting its capability to deliver robust and generalized perception for robotic agents operating in complex, unconstrained open-world environments. The source code will be made publicly available at https://github.com/zjjqinyu/FiCoP.
Learnable Query Aggregation with KV Routing for Cross-view Geo-localisation
Dec 30, 2025Cross-view geo-localisation (CVGL) aims to estimate the geographic location of a query image by matching it with images from a large-scale database. However, the significant view-point discrepancies present considerable challenges for effective feature aggregation and alignment. To address these challenges, we propose a novel CVGL system that incorporates three key improvements. Firstly, we leverage the DINOv2 backbone with a convolution adapter fine-tuning to enhance model adaptability to cross-view variations. Secondly, we propose a multi-scale channel reallocation module to strengthen the diversity and stability of spatial representations. Finally, we propose an improved aggregation module that integrates a Mixture-of-Experts (MoE) routing into the feature aggregation process. Specifically, the module dynamically selects expert subspaces for the keys and values in a cross-attention framework, enabling adaptive processing of heterogeneous input domains. Extensive experiments on the University-1652 and SUES-200 datasets demonstrate that our method achieves competitive performance with fewer trained parameters.
ICML Topological Deep Learning Challenge 2024: Beyond the Graph Domain
Sep 08, 2024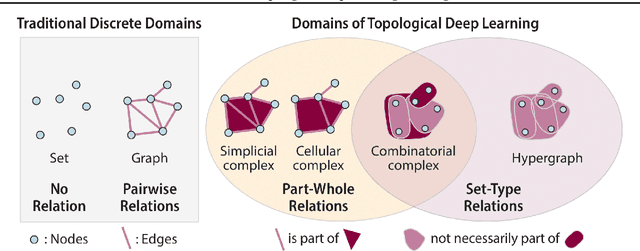
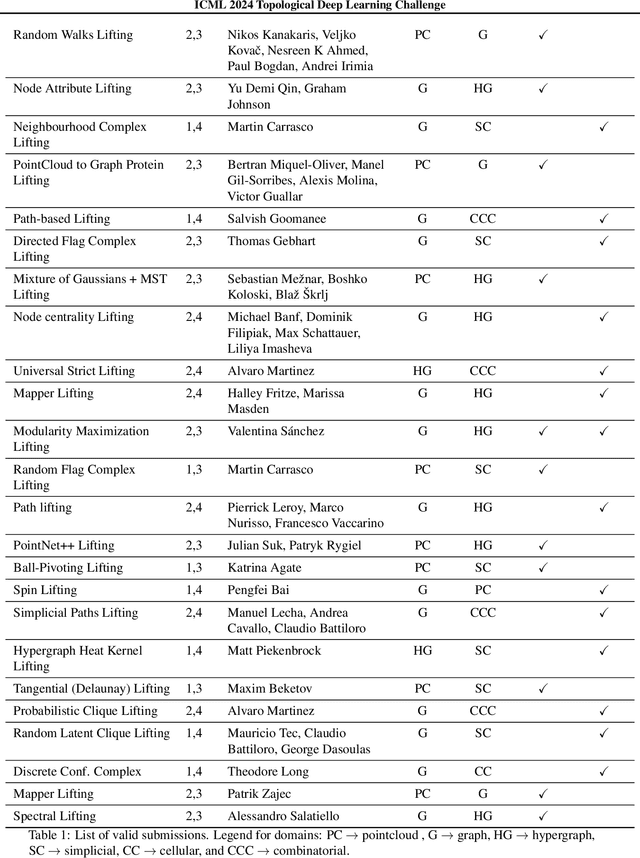
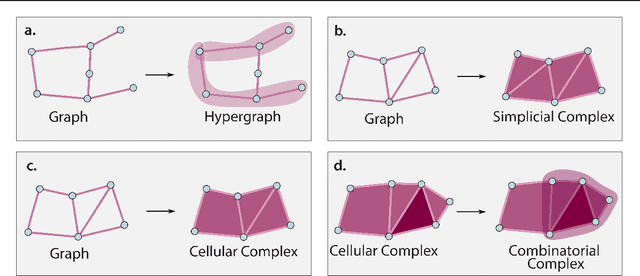
This paper describes the 2nd edition of the ICML Topological Deep Learning Challenge that was hosted within the ICML 2024 ELLIS Workshop on Geometry-grounded Representation Learning and Generative Modeling (GRaM). The challenge focused on the problem of representing data in different discrete topological domains in order to bridge the gap between Topological Deep Learning (TDL) and other types of structured datasets (e.g. point clouds, graphs). Specifically, participants were asked to design and implement topological liftings, i.e. mappings between different data structures and topological domains --like hypergraphs, or simplicial/cell/combinatorial complexes. The challenge received 52 submissions satisfying all the requirements. This paper introduces the main scope of the challenge, and summarizes the main results and findings.
Decoupled and Interactive Regression Modeling for High-performance One-stage 3D Object Detection
Sep 01, 2024



Inadequate bounding box modeling in regression tasks constrains the performance of one-stage 3D object detection. Our study reveals that the primary reason lies in two aspects: (1) The limited center-offset prediction seriously impairs the bounding box localization since many highest response positions significantly deviate from object centers. (2) The low-quality sample ignored in regression tasks significantly impacts the bounding box prediction since it produces unreliable quality (IoU) rectification. To tackle these problems, we propose Decoupled and Interactive Regression Modeling (DIRM) for one-stage detection. Specifically, Decoupled Attribute Regression (DAR) is implemented to facilitate long regression range modeling for the center attribute through an adaptive multi-sample assignment strategy that deeply decouples bounding box attributes. On the other hand, to enhance the reliability of IoU predictions for low-quality results, Interactive Quality Prediction (IQP) integrates the classification task, proficient in modeling negative samples, with quality prediction for joint optimization. Extensive experiments on Waymo and ONCE datasets demonstrate that DIRM significantly improves the performance of several state-of-the-art methods with minimal additional inference latency. Notably, DIRM achieves state-of-the-art detection performance on both the Waymo and ONCE datasets.
Learning production functions for supply chains with graph neural networks
Jul 26, 2024The global economy relies on the flow of goods over supply chain networks, with nodes as firms and edges as transactions between firms. While we may observe these external transactions, they are governed by unseen production functions, which determine how firms internally transform the input products they receive into output products that they sell. In this setting, it can be extremely valuable to infer these production functions, to better understand and improve supply chains, and to forecast future transactions more accurately. However, existing graph neural networks (GNNs) cannot capture these hidden relationships between nodes' inputs and outputs. Here, we introduce a new class of models for this setting, by combining temporal GNNs with a novel inventory module, which learns production functions via attention weights and a special loss function. We evaluate our models extensively on real supply chains data, along with data generated from our new open-source simulator, SupplySim. Our models successfully infer production functions, with a 6-50% improvement over baselines, and forecast future transactions on real and synthetic data, outperforming baselines by 11-62%.
Rapid and Precise Topological Comparison with Merge Tree Neural Networks
Apr 08, 2024
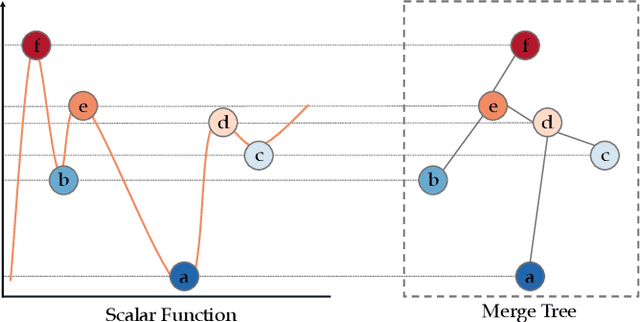
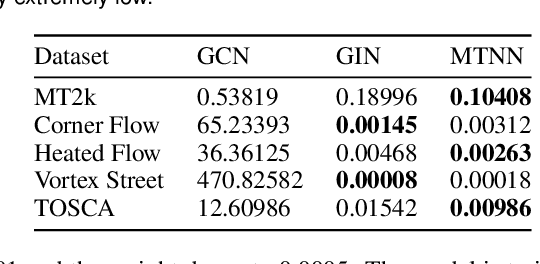
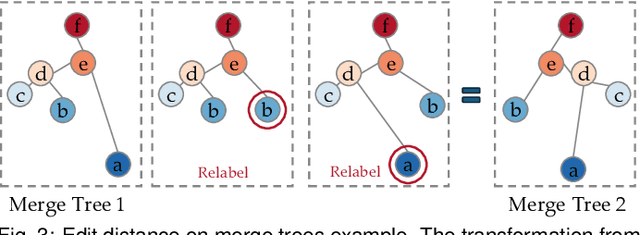
Merge trees are a valuable tool in scientific visualization of scalar fields; however, current methods for merge tree comparisons are computationally expensive, primarily due to the exhaustive matching between tree nodes. To address this challenge, we introduce the merge tree neural networks (MTNN), a learned neural network model designed for merge tree comparison. The MTNN enables rapid and high-quality similarity computation. We first demonstrate how graph neural networks (GNNs), which emerged as an effective encoder for graphs, can be trained to produce embeddings of merge trees in vector spaces that enable efficient similarity comparison. Next, we formulate the novel MTNN model that further improves the similarity comparisons by integrating the tree and node embeddings with a new topological attention mechanism. We demonstrate the effectiveness of our model on real-world data in different domains and examine our model's generalizability across various datasets. Our experimental analysis demonstrates our approach's superiority in accuracy and efficiency. In particular, we speed up the prior state-of-the-art by more than 100x on the benchmark datasets while maintaining an error rate below 0.1%.
Derivative-free tree optimization for complex systems
Apr 05, 2024



A tremendous range of design tasks in materials, physics, and biology can be formulated as finding the optimum of an objective function depending on many parameters without knowing its closed-form expression or the derivative. Traditional derivative-free optimization techniques often rely on strong assumptions about objective functions, thereby failing at optimizing non-convex systems beyond 100 dimensions. Here, we present a tree search method for derivative-free optimization that enables accelerated optimal design of high-dimensional complex systems. Specifically, we introduce stochastic tree expansion, dynamic upper confidence bound, and short-range backpropagation mechanism to evade local optimum, iteratively approximating the global optimum using machine learning models. This development effectively confronts the dimensionally challenging problems, achieving convergence to global optima across various benchmark functions up to 2,000 dimensions, surpassing the existing methods by 10- to 20-fold. Our method demonstrates wide applicability to a wide range of real-world complex systems spanning materials, physics, and biology, considerably outperforming state-of-the-art algorithms. This enables efficient autonomous knowledge discovery and facilitates self-driving virtual laboratories. Although we focus on problems within the realm of natural science, the advancements in optimization techniques achieved herein are applicable to a broader spectrum of challenges across all quantitative disciplines.
Context-based Fast Recommendation Strategy for Long User Behavior Sequence in Meituan Waimai
Mar 19, 2024



In the recommender system of Meituan Waimai, we are dealing with ever-lengthening user behavior sequences, which pose an increasing challenge to modeling user preference effectively. Existing sequential recommendation models often fail to capture long-term dependencies or are too complex, complicating the fulfillment of Meituan Waimai's unique business needs. To better model user interests, we consider selecting relevant sub-sequences from users' extensive historical behaviors based on their preferences. In this specific scenario, we've noticed that the contexts in which users interact have a significant impact on their preferences. For this purpose, we introduce a novel method called Context-based Fast Recommendation Strategy to tackle the issue of long sequences. We first identify contexts that share similar user preferences with the target context and then locate the corresponding PoIs based on these identified contexts. This approach eliminates the necessity to select a sub-sequence for every candidate PoI, thereby avoiding high time complexity. Specifically, we implement a prototype-based approach to pinpoint contexts that mirror similar user preferences. To amplify accuracy and interpretability, we employ JS divergence of PoI attributes such as categories and prices as a measure of similarity between contexts. A temporal graph integrating both prototype and context nodes helps incorporate temporal information. We then identify appropriate prototypes considering both target contexts and short-term user preferences. Following this, we utilize contexts aligned with these prototypes to generate a sub-sequence, aimed at predicting CTR and CTCVR scores with target attention. Since its inception in 2023, this strategy has been adopted in Meituan Waimai's display recommender system, leading to a 4.6% surge in CTR and a 4.2% boost in GMV.
Enhancing the "Immunity" of Mixture-of-Experts Networks for Adversarial Defense
Feb 29, 2024



Recent studies have revealed the vulnerability of Deep Neural Networks (DNNs) to adversarial examples, which can easily fool DNNs into making incorrect predictions. To mitigate this deficiency, we propose a novel adversarial defense method called "Immunity" (Innovative MoE with MUtual information \& positioN stabilITY) based on a modified Mixture-of-Experts (MoE) architecture in this work. The key enhancements to the standard MoE are two-fold: 1) integrating of Random Switch Gates (RSGs) to obtain diverse network structures via random permutation of RSG parameters at evaluation time, despite of RSGs being determined after one-time training; 2) devising innovative Mutual Information (MI)-based and Position Stability-based loss functions by capitalizing on Grad-CAM's explanatory power to increase the diversity and the causality of expert networks. Notably, our MI-based loss operates directly on the heatmaps, thereby inducing subtler negative impacts on the classification performance when compared to other losses of the same type, theoretically. Extensive evaluation validates the efficacy of the proposed approach in improving adversarial robustness against a wide range of attacks.