 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTGR: Industrial-Scale Generative Recommendation Framework in Meituan
May 24, 2025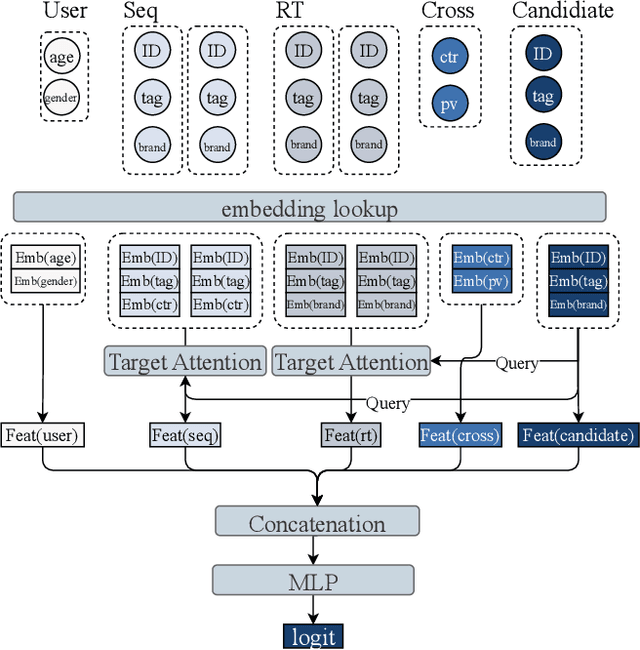
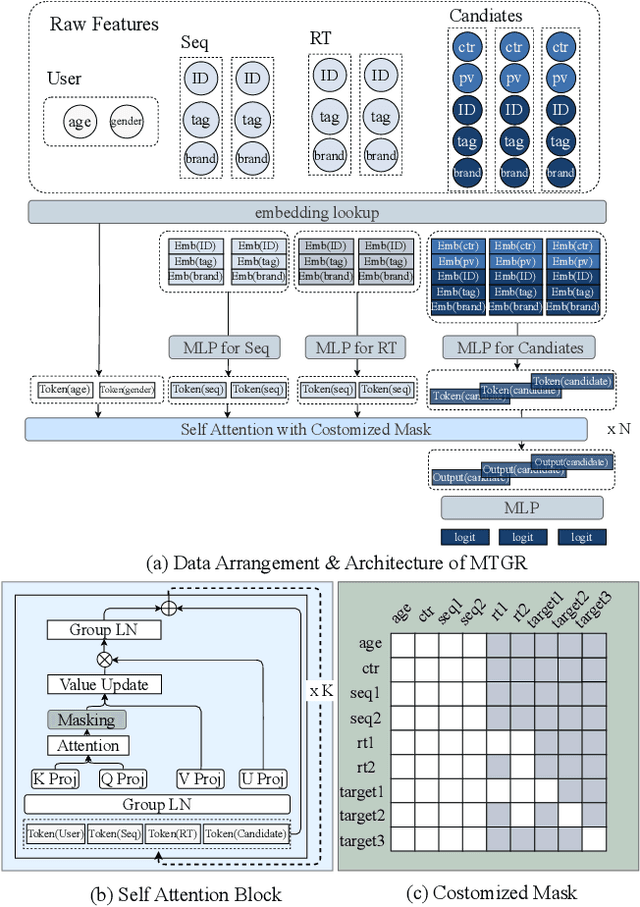

Scaling law has been extensively validated in many domains such as natural language processing and computer vision. In the recommendation system, recent work has adopted generative recommendations to achieve scalability, but their generative approaches require abandoning the carefully constructed cross features of traditional recommendation models. We found that this approach significantly degrades model performance, and scaling up cannot compensate for it at all. In this paper, we propose MTGR (Meituan Generative Recommendation) to address this issue. MTGR is modeling based on the HSTU architecture and can retain the original deep learning recommendation model (DLRM) features, including cross features. Additionally, MTGR achieves training and inference acceleration through user-level compression to ensure efficient scaling. We also propose Group-Layer Normalization (GLN) to enhance the performance of encoding within different semantic spaces and the dynamic masking strategy to avoid information leakage. We further optimize the training frameworks, enabling support for our models with 10 to 100 times computational complexity compared to the DLRM, without significant cost increases. MTGR achieved 65x FLOPs for single-sample forward inference compared to the DLRM model, resulting in the largest gain in nearly two years both offline and online. This breakthrough was successfully deployed on Meituan, the world's largest food delivery platform, where it has been handling the main traffic.
Teleology-Driven Affective Computing: A Causal Framework for Sustained Well-Being
Feb 24, 2025Affective computing has made significant strides in emotion recognition and generation, yet current approaches mainly focus on short-term pattern recognition and lack a comprehensive framework to guide affective agents toward long-term human well-being. To address this, we propose a teleology-driven affective computing framework that unifies major emotion theories (basic emotion, appraisal, and constructivist approaches) under the premise that affect is an adaptive, goal-directed process that facilitates survival and development. Our framework emphasizes aligning agent responses with both personal/individual and group/collective well-being over extended timescales. We advocate for creating a "dataverse" of personal affective events, capturing the interplay between beliefs, goals, actions, and outcomes through real-world experience sampling and immersive virtual reality. By leveraging causal modeling, this "dataverse" enables AI systems to infer individuals' unique affective concerns and provide tailored interventions for sustained well-being. Additionally, we introduce a meta-reinforcement learning paradigm to train agents in simulated environments, allowing them to adapt to evolving affective concerns and balance hierarchical goals - from immediate emotional needs to long-term self-actualization. This framework shifts the focus from statistical correlations to causal reasoning, enhancing agents' ability to predict and respond proactively to emotional challenges, and offers a foundation for developing personalized, ethically aligned affective systems that promote meaningful human-AI interactions and societal well-being.
LARR: Large Language Model Aided Real-time Scene Recommendation with Semantic Understanding
Aug 21, 2024

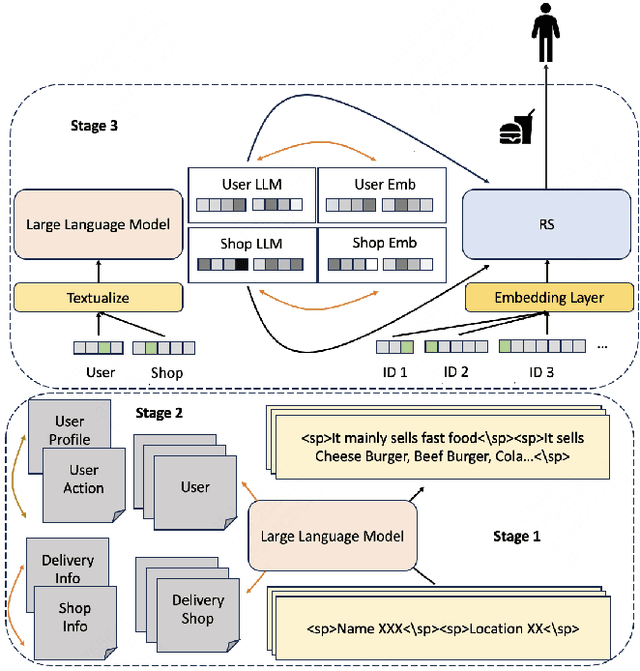

Click-Through Rate (CTR) prediction is crucial for Recommendation System(RS), aiming to provide personalized recommendation services for users in many aspects such as food delivery, e-commerce and so on. However, traditional RS relies on collaborative signals, which lacks semantic understanding to real-time scenes. We also noticed that a major challenge in utilizing Large Language Models (LLMs) for practical recommendation purposes is their efficiency in dealing with long text input. To break through the problems above, we propose Large Language Model Aided Real-time Scene Recommendation(LARR), adopt LLMs for semantic understanding, utilizing real-time scene information in RS without requiring LLM to process the entire real-time scene text directly, thereby enhancing the efficiency of LLM-based CTR modeling. Specifically, recommendation domain-specific knowledge is injected into LLM and then RS employs an aggregation encoder to build real-time scene information from separate LLM's outputs. Firstly, a LLM is continual pretrained on corpus built from recommendation data with the aid of special tokens. Subsequently, the LLM is fine-tuned via contrastive learning on three kinds of sample construction strategies. Through this step, LLM is transformed into a text embedding model. Finally, LLM's separate outputs for different scene features are aggregated by an encoder, aligning to collaborative signals in RS, enhancing the performance of recommendation model.
Context-based Fast Recommendation Strategy for Long User Behavior Sequence in Meituan Waimai
Mar 19, 2024



In the recommender system of Meituan Waimai, we are dealing with ever-lengthening user behavior sequences, which pose an increasing challenge to modeling user preference effectively. Existing sequential recommendation models often fail to capture long-term dependencies or are too complex, complicating the fulfillment of Meituan Waimai's unique business needs. To better model user interests, we consider selecting relevant sub-sequences from users' extensive historical behaviors based on their preferences. In this specific scenario, we've noticed that the contexts in which users interact have a significant impact on their preferences. For this purpose, we introduce a novel method called Context-based Fast Recommendation Strategy to tackle the issue of long sequences. We first identify contexts that share similar user preferences with the target context and then locate the corresponding PoIs based on these identified contexts. This approach eliminates the necessity to select a sub-sequence for every candidate PoI, thereby avoiding high time complexity. Specifically, we implement a prototype-based approach to pinpoint contexts that mirror similar user preferences. To amplify accuracy and interpretability, we employ JS divergence of PoI attributes such as categories and prices as a measure of similarity between contexts. A temporal graph integrating both prototype and context nodes helps incorporate temporal information. We then identify appropriate prototypes considering both target contexts and short-term user preferences. Following this, we utilize contexts aligned with these prototypes to generate a sub-sequence, aimed at predicting CTR and CTCVR scores with target attention. Since its inception in 2023, this strategy has been adopted in Meituan Waimai's display recommender system, leading to a 4.6% surge in CTR and a 4.2% boost in GMV.
Heterogeneous Knowledge Fusion: A Novel Approach for Personalized Recommendation via LLM
Aug 18, 2023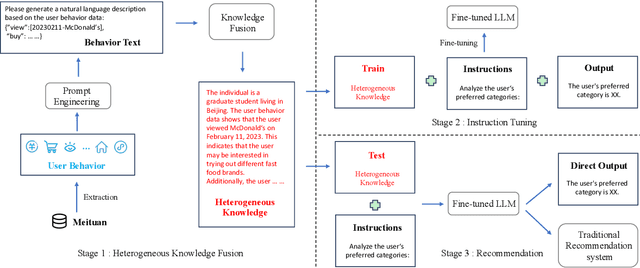
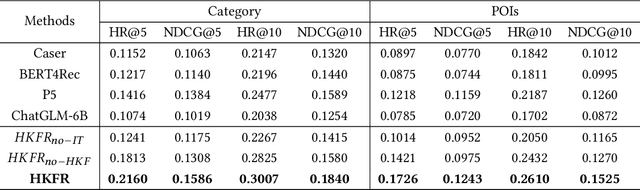
The analysis and mining of user heterogeneous behavior are of paramount importance in recommendation systems. However, the conventional approach of incorporating various types of heterogeneous behavior into recommendation models leads to feature sparsity and knowledge fragmentation issues. To address this challenge, we propose a novel approach for personalized recommendation via Large Language Model (LLM), by extracting and fusing heterogeneous knowledge from user heterogeneous behavior information. In addition, by combining heterogeneous knowledge and recommendation tasks, instruction tuning is performed on LLM for personalized recommendations. The experimental results demonstrate that our method can effectively integrate user heterogeneous behavior and significantly improve recommendation performance.
PerCoNet: News Recommendation with Explicit Persona and Contrastive Learning
Apr 17, 2023



Personalized news recommender systems help users quickly find content of their interests from the sea of information. Today, the mainstream technology for personalized news recommendation is based on deep neural networks that can accurately model the semantic match between news items and users' interests. In this paper, we present \textbf{PerCoNet}, a novel deep learning approach to personalized news recommendation which features two new findings: (i) representing users through \emph{explicit persona analysis} based on the prominent entities in their recent news reading history could be more effective than latent persona analysis employed by most existing work, with a side benefit of enhanced explainability; (ii) utilizing the title and abstract of each news item via cross-view \emph{contrastive learning} would work better than just combining them directly. Extensive experiments on two real-world news datasets clearly show the superior performance of our proposed approach in comparison with current state-of-the-art techniques.
HomoDistil: Homotopic Task-Agnostic Distillation of Pre-trained Transformers
Feb 19, 2023Knowledge distillation has been shown to be a powerful model compression approach to facilitate the deployment of pre-trained language models in practice. This paper focuses on task-agnostic distillation. It produces a compact pre-trained model that can be easily fine-tuned on various tasks with small computational costs and memory footprints. Despite the practical benefits, task-agnostic distillation is challenging. Since the teacher model has a significantly larger capacity and stronger representation power than the student model, it is very difficult for the student to produce predictions that match the teacher's over a massive amount of open-domain training data. Such a large prediction discrepancy often diminishes the benefits of knowledge distillation. To address this challenge, we propose Homotopic Distillation (HomoDistil), a novel task-agnostic distillation approach equipped with iterative pruning. Specifically, we initialize the student model from the teacher model, and iteratively prune the student's neurons until the target width is reached. Such an approach maintains a small discrepancy between the teacher's and student's predictions throughout the distillation process, which ensures the effectiveness of knowledge transfer. Extensive experiments demonstrate that HomoDistil achieves significant improvements on existing baselines.