 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Deployment Approval for Learned Landing Controllers under Finite Rollout Validation
May 26, 2026Reinforcement learning and data-driven autonomous controllers are commonly evaluated using cumulative reward and empirical success frequency under finite simulation trajectories. However, such empirical metrics do not necessarily provide sufficient statistical evidence regarding deployment readiness under uncertainty. This work develops a Bayesian approval framework for learned autonomous landing controllers under finite rollout evidence. A probabilistic landing capability formulation is introduced based on touchdown safety satisfaction under uncertain operating conditions, while Bayesian posterior inference is used to quantify uncertainty regarding the true deployment capability of learned policies. Posterior approval probability and posterior deployment risk are further introduced for deployment-oriented evaluation, together with a sequential validation framework supporting approve/reject/continue decisions during progressive rollout testing. Simulation experiments using PPO and SAC controllers demonstrate that empirical success and reward optimization may produce overconfident deployment interpretation under limited validation evidence, whereas posterior approval inference provides a more uncertainty-calibrated assessment of deployment readiness. The proposed framework provides a practical statistical connection between conventional reinforcement-learning evaluation and deployment-oriented validation under uncertainty and may be generalized to broader classes of learned autonomous systems.
Latent Dynamics for Full Body Avatar Animation
May 20, 2026Pose-driven full-body avatars built on neural rendering produce high-quality novel views of a captured subject. Yet loose clothing and other dynamic elements deform in ways pose alone cannot explain: the same pose can correspond to many different states, because their motion depends on history, inertia, and contact. Explicit simulation and layered-garment methods can model such dynamics, but they require either a dedicated garment template, which raw multi-view capture does not naturally provide, or a test-time physics simulator with non-trivial runtime cost. A parallel line of work learns data-driven clothing avatars that avoid explicit garment layers. These methods add an auxiliary latent for variation beyond pose; at inference, they fix it, regress it from pose, or retrieve it from training data, without explicitly modeling how the latent evolves with its own dynamics. Additionally, even in everyday motion with loose clothing, existing architectures often struggle to capture fine-grained detail, producing blurry renderings and temporal artifacts. We augment a pose-conditioned 3D Gaussian avatar with a transformer-based decoder and a dynamics residual latent that captures temporal appearance and geometry variation beyond the driving signals. At inference, a learned latent dynamics model evolves the residual latent from a short pose history and the previous latent state. The model decomposes each update into driving, restoring, and dissipative forces, producing temporally coherent, history-dependent rollouts with negligible added cost. Different initial conditions yield diverse yet plausible motion trajectories, and the force decomposition exposes controls such as stiffness. Across nine captured sequences of everyday motion with diverse loose garments, quantitative metrics and a perceptual user study show improved animation quality over recent data-driven baselines.
MTServe: Efficient Serving for Generative Recommendation Models with Hierarchical Caches
Apr 24, 2026Generative recommendation (GR) offers superior modeling capabilities but suffers from prohibitive inference costs due to the repeated encoding of long user histories. While cross-request Key-Value (KV) cache reuse presents a significant optimization opportunity, the massive scale of individual user states creates a storage explosion that far exceeds physical GPU limits. We propose MTServe, a hierarchical cache management system that virtualizes GPU memory by leveraging host RAM as a scalable backup store. To bridge the I/O gap between tiers, MTServe introduces a suite of system-level optimizations, including a hybrid storage layout, an asynchronous data transfer pipeline, and a locality-driven replacement policy. On both public and production datasets, MTServe delivers up to 3.1* speedup while maintaining near-perfect hit ratios (>98.5%).
DiningBench: A Hierarchical Multi-view Benchmark for Perception and Reasoning in the Dietary Domain
Apr 12, 2026Recent advancements in Vision-Language Models (VLMs) have revolutionized general visual understanding. However, their application in the food domain remains constrained by benchmarks that rely on coarse-grained categories, single-view imagery, and inaccurate metadata. To bridge this gap, we introduce DiningBench, a hierarchical, multi-view benchmark designed to evaluate VLMs across three levels of cognitive complexity: Fine-Grained Classification, Nutrition Estimation, and Visual Question Answering. Unlike previous datasets, DiningBench comprises 3,021 distinct dishes with an average of 5.27 images per entry, incorporating fine-grained "hard" negatives from identical menus and rigorous, verification-based nutritional data. We conduct an extensive evaluation of 29 state-of-the-art open-source and proprietary models. Our experiments reveal that while current VLMs excel at general reasoning, they struggle significantly with fine-grained visual discrimination and precise nutritional reasoning. Furthermore, we systematically investigate the impact of multi-view inputs and Chain-of-Thought reasoning, identifying five primary failure modes. DiningBench serves as a challenging testbed to drive the next generation of food-centric VLM research. All codes are released in https://github.com/meituan/DiningBench.
Distributional Deep Learning for Super-Resolution of 4D Flow MRI under Domain Shift
Feb 16, 2026Super-resolution is widely used in medical imaging to enhance low-quality data, reducing scan time and improving abnormality detection. Conventional super-resolution approaches typically rely on paired datasets of downsampled and original high resolution images, training models to reconstruct high resolution images from their artificially degraded counterparts. However, in real-world clinical settings, low resolution data often arise from acquisition mechanisms that differ significantly from simple downsampling. As a result, these inputs may lie outside the domain of the training data, leading to poor model generalization due to domain shift. To address this limitation, we propose a distributional deep learning framework that improves model robustness and domain generalization. We develop this approch for enhancing the resolution of 4D Flow MRI (4DF). This is a novel imaging modality that captures hemodynamic flow velocity and clinically relevant metrics such as vessel wall stress. These metrics are critical for assessing aneurysm rupture risk. Our model is initially trained on high resolution computational fluid dynamics (CFD) simulations and their downsampled counterparts. It is then fine-tuned on a small, harmonized dataset of paired 4D Flow MRI and CFD samples. We derive the theoretical properties of our distributional estimators and demonstrate that our framework significantly outperforms traditional deep learning approaches through real data applications. This highlights the effectiveness of distributional learning in addressing domain shift and improving super-resolution performance in clinically realistic scenarios.
MTFM: A Scalable and Alignment-free Foundation Model for Industrial Recommendation in Meituan
Feb 13, 2026Industrial recommendation systems typically involve multiple scenarios, yet existing cross-domain (CDR) and multi-scenario (MSR) methods often require prohibitive resources and strict input alignment, limiting their extensibility. We propose MTFM (Meituan Foundation Model for Recommendation), a transformer-based framework that addresses these challenges. Instead of pre-aligning inputs, MTFM transforms cross-domain data into heterogeneous tokens, capturing multi-scenario knowledge in an alignment-free manner. To enhance efficiency, we first introduce a multi-scenario user-level sample aggregation that significantly enhances training throughput by reducing the total number of instances. We further integrate Grouped-Query Attention and a customized Hybrid Target Attention to minimize memory usage and computational complexity. Furthermore, we implement various system-level optimizations, such as kernel fusion and the elimination of CPU-GPU blocking, to further enhance both training and inference throughput. Offline and online experiments validate the effectiveness of MTFM, demonstrating that significant performance gains are achieved by scaling both model capacity and multi-scenario training data.
CAAL: Confidence-Aware Active Learning for Heteroscedastic Atmospheric Regression
Feb 12, 2026Quantifying the impacts of air pollution on health and climate relies on key atmospheric particle properties such as toxicity and hygroscopicity. However, these properties typically require complex observational techniques or expensive particle-resolved numerical simulations, limiting the availability of labeled data. We therefore estimate these hard-to-measure particle properties from routinely available observations (e.g., air pollutant concentrations and meteorological conditions). Because routine observations only indirectly reflect particle composition and structure, the mapping from routine observations to particle properties is noisy and input-dependent, yielding a heteroscedastic regression setting. With a limited and costly labeling budget, the central challenge is to select which samples to measure or simulate. While active learning is a natural approach, most acquisition strategies rely on predictive uncertainty. Under heteroscedastic noise, this signal conflates reducible epistemic uncertainty with irreducible aleatoric uncertainty, causing limited budgets to be wasted in noise-dominated regions. To address this challenge, we propose a confidence-aware active learning framework (CAAL) for efficient and robust sample selection in heteroscedastic settings. CAAL consists of two components: a decoupled uncertainty-aware training objective that separately optimises the predictive mean and noise level to stabilise uncertainty estimation, and a confidence-aware acquisition function that dynamically weights epistemic uncertainty using predicted aleatoric uncertainty as a reliability signal. Experiments on particle-resolved numerical simulations and real atmospheric observations show that CAAL consistently outperforms standard AL baselines. The proposed framework provides a practical and general solution for the efficient expansion of high-cost atmospheric particle property databases.
DS-HGCN: A Dual-Stream Hypergraph Convolutional Network for Predicting Student Engagement via Social Contagion
Dec 23, 2025Student engagement is a critical factor influencing academic success and learning outcomes. Accurately predicting student engagement is essential for optimizing teaching strategies and providing personalized interventions. However, most approaches focus on single-dimensional feature analysis and assessing engagement based on individual student factors. In this work, we propose a dual-stream multi-feature fusion model based on hypergraph convolutional networks (DS-HGCN), incorporating social contagion of student engagement. DS-HGCN enables accurate prediction of student engagement states by modeling multi-dimensional features and their propagation mechanisms between students. The framework constructs a hypergraph structure to encode engagement contagion among students and captures the emotional and behavioral differences and commonalities by multi-frequency signals. Furthermore, we introduce a hypergraph attention mechanism to dynamically weigh the influence of each student, accounting for individual differences in the propagation process. Extensive experiments on public benchmark datasets demonstrate that our proposed method achieves superior performance and significantly outperforms existing state-of-the-art approaches.
FactorPortrait: Controllable Portrait Animation via Disentangled Expression, Pose, and Viewpoint
Dec 12, 2025We introduce FactorPortrait, a video diffusion method for controllable portrait animation that enables lifelike synthesis from disentangled control signals of facial expressions, head movement, and camera viewpoints. Given a single portrait image, a driving video, and camera trajectories, our method animates the portrait by transferring facial expressions and head movements from the driving video while simultaneously enabling novel view synthesis from arbitrary viewpoints. We utilize a pre-trained image encoder to extract facial expression latents from the driving video as control signals for animation generation. Such latents implicitly capture nuanced facial expression dynamics with identity and pose information disentangled, and they are efficiently injected into the video diffusion transformer through our proposed expression controller. For camera and head pose control, we employ Plücker ray maps and normal maps rendered from 3D body mesh tracking. To train our model, we curate a large-scale synthetic dataset containing diverse combinations of camera viewpoints, head poses, and facial expression dynamics. Extensive experiments demonstrate that our method outperforms existing approaches in realism, expressiveness, control accuracy, and view consistency.
MTGR: Industrial-Scale Generative Recommendation Framework in Meituan
May 24, 2025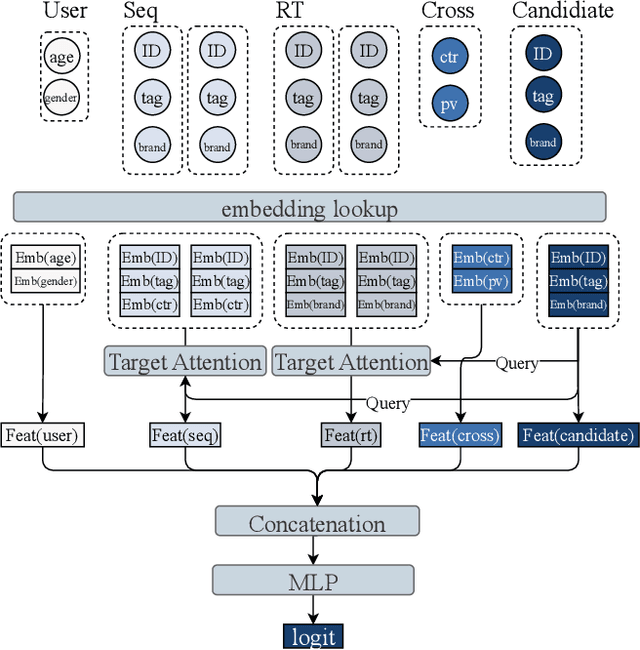
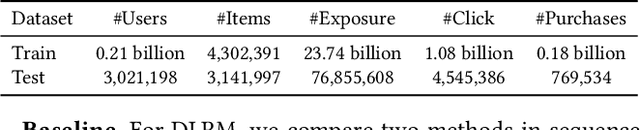
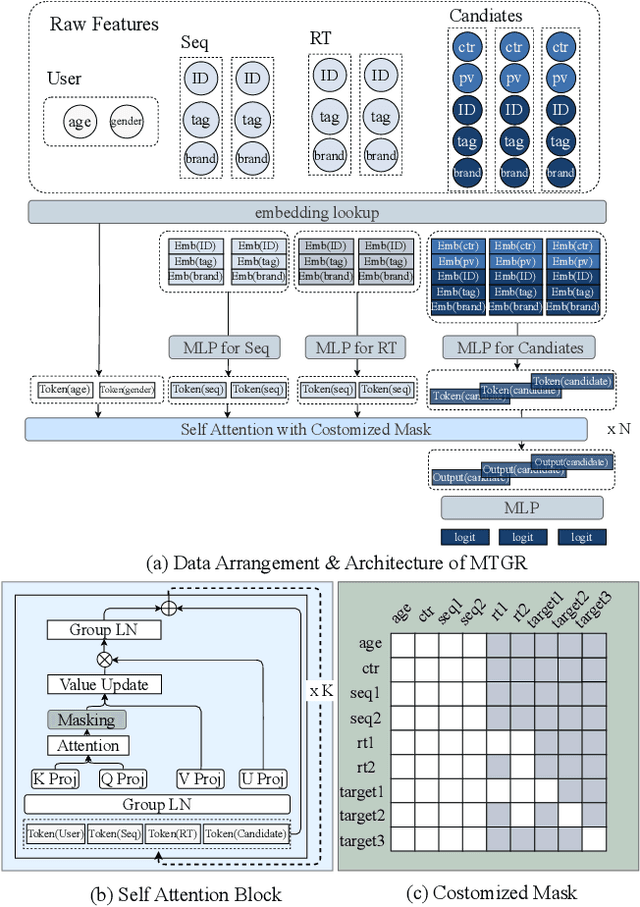

Scaling law has been extensively validated in many domains such as natural language processing and computer vision. In the recommendation system, recent work has adopted generative recommendations to achieve scalability, but their generative approaches require abandoning the carefully constructed cross features of traditional recommendation models. We found that this approach significantly degrades model performance, and scaling up cannot compensate for it at all. In this paper, we propose MTGR (Meituan Generative Recommendation) to address this issue. MTGR is modeling based on the HSTU architecture and can retain the original deep learning recommendation model (DLRM) features, including cross features. Additionally, MTGR achieves training and inference acceleration through user-level compression to ensure efficient scaling. We also propose Group-Layer Normalization (GLN) to enhance the performance of encoding within different semantic spaces and the dynamic masking strategy to avoid information leakage. We further optimize the training frameworks, enabling support for our models with 10 to 100 times computational complexity compared to the DLRM, without significant cost increases. MTGR achieved 65x FLOPs for single-sample forward inference compared to the DLRM model, resulting in the largest gain in nearly two years both offline and online. This breakthrough was successfully deployed on Meituan, the world's largest food delivery platform, where it has been handling the main traffic.