 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\text{M}^{2}$LLM: Multi-view Molecular Representation Learning with Large Language Models
Aug 12, 2025Accurate molecular property prediction is a critical challenge with wide-ranging applications in chemistry, materials science, and drug discovery. Molecular representation methods, including fingerprints and graph neural networks (GNNs), achieve state-of-the-art results by effectively deriving features from molecular structures. However, these methods often overlook decades of accumulated semantic and contextual knowledge. Recent advancements in large language models (LLMs) demonstrate remarkable reasoning abilities and prior knowledge across scientific domains, leading us to hypothesize that LLMs can generate rich molecular representations when guided to reason in multiple perspectives. To address these gaps, we propose $\text{M}^{2}$LLM, a multi-view framework that integrates three perspectives: the molecular structure view, the molecular task view, and the molecular rules view. These views are fused dynamically to adapt to task requirements, and experiments demonstrate that $\text{M}^{2}$LLM achieves state-of-the-art performance on multiple benchmarks across classification and regression tasks. Moreover, we demonstrate that representation derived from LLM achieves exceptional performance by leveraging two core functionalities: the generation of molecular embeddings through their encoding capabilities and the curation of molecular features through advanced reasoning processes.
Collaborative Expert LLMs Guided Multi-Objective Molecular Optimization
Mar 05, 2025



Molecular optimization is a crucial yet complex and time-intensive process that often acts as a bottleneck for drug development. Traditional methods rely heavily on trial and error, making multi-objective optimization both time-consuming and resource-intensive. Current AI-based methods have shown limited success in handling multi-objective optimization tasks, hampering their practical utilization. To address this challenge, we present MultiMol, a collaborative large language model (LLM) system designed to guide multi-objective molecular optimization. MultiMol comprises two agents, including a data-driven worker agent and a literature-guided research agent. The data-driven worker agent is a large language model being fine-tuned to learn how to generate optimized molecules considering multiple objectives, while the literature-guided research agent is responsible for searching task-related literature to find useful prior knowledge that facilitates identifying the most promising optimized candidates. In evaluations across six multi-objective optimization tasks, MultiMol significantly outperforms existing methods, achieving a 82.30% success rate, in sharp contrast to the 27.50% success rate of current strongest methods. To further validate its practical impact, we tested MultiMol on two real-world challenges. First, we enhanced the selectivity of Xanthine Amine Congener (XAC), a promiscuous ligand that binds both A1R and A2AR, successfully biasing it towards A1R. Second, we improved the bioavailability of Saquinavir, an HIV-1 protease inhibitor with known bioavailability limitations. Overall, these results indicate that MultiMol represents a highly promising approach for multi-objective molecular optimization, holding great potential to accelerate the drug development process and contribute to the advancement of pharmaceutical research.
A Label-Free Heterophily-Guided Approach for Unsupervised Graph Fraud Detection
Feb 18, 2025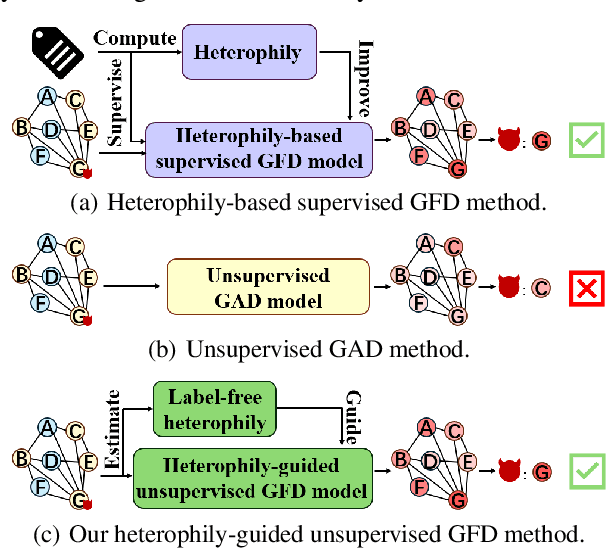

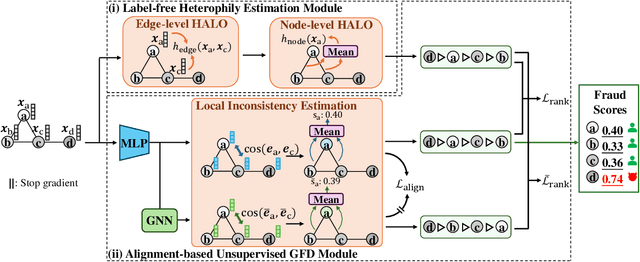
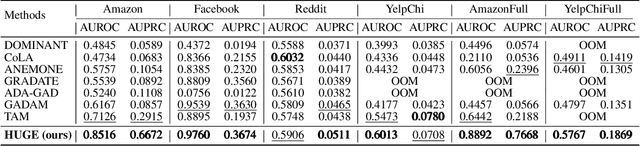
Graph fraud detection (GFD) has rapidly advanced in protecting online services by identifying malicious fraudsters. Recent supervised GFD research highlights that heterophilic connections between fraudsters and users can greatly impact detection performance, since fraudsters tend to camouflage themselves by building more connections to benign users. Despite the promising performance of supervised GFD methods, the reliance on labels limits their applications to unsupervised scenarios; Additionally, accurately capturing complex and diverse heterophily patterns without labels poses a further challenge. To fill the gap, we propose a Heterophily-guided Unsupervised Graph fraud dEtection approach (HUGE) for unsupervised GFD, which contains two essential components: a heterophily estimation module and an alignment-based fraud detection module. In the heterophily estimation module, we design a novel label-free heterophily metric called HALO, which captures the critical graph properties for GFD, enabling its outstanding ability to estimate heterophily from node attributes. In the alignment-based fraud detection module, we develop a joint MLP-GNN architecture with ranking loss and asymmetric alignment loss. The ranking loss aligns the predicted fraud score with the relative order of HALO, providing an extra robustness guarantee by comparing heterophily among non-adjacent nodes. Moreover, the asymmetric alignment loss effectively utilizes structural information while alleviating the feature-smooth effects of GNNs.Extensive experiments on 6 datasets demonstrate that HUGE significantly outperforms competitors, showcasing its effectiveness and robustness. The source code of HUGE is at https://github.com/CampanulaBells/HUGE-GAD.
Large Language Models in Drug Discovery and Development: From Disease Mechanisms to Clinical Trials
Sep 06, 2024
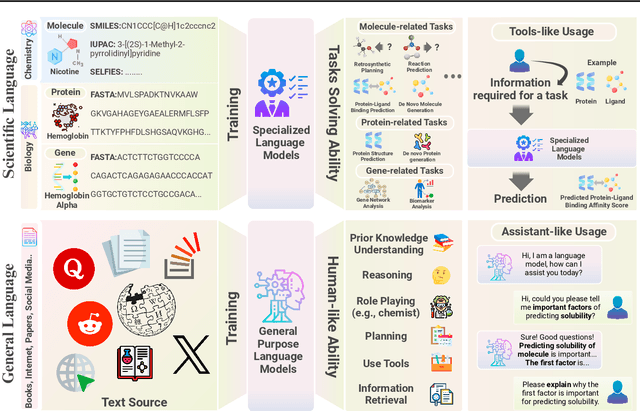
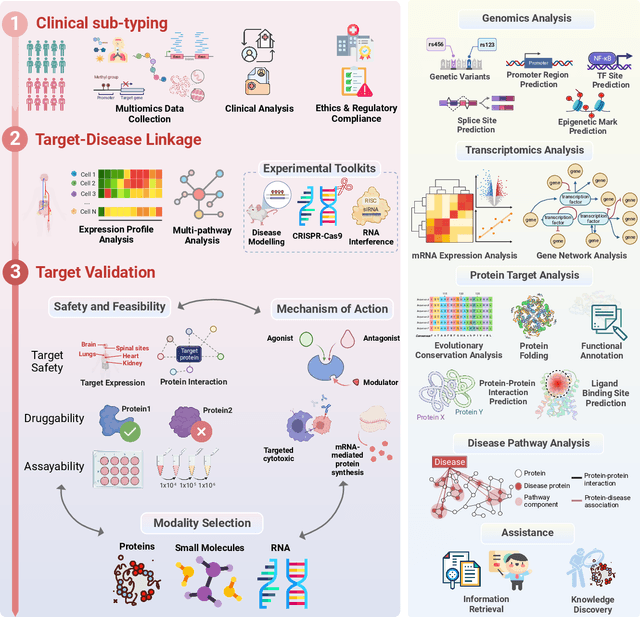
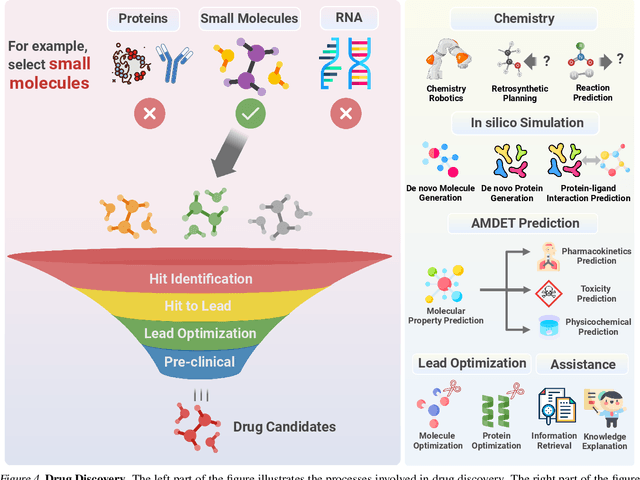
The integration of Large Language Models (LLMs) into the drug discovery and development field marks a significant paradigm shift, offering novel methodologies for understanding disease mechanisms, facilitating drug discovery, and optimizing clinical trial processes. This review highlights the expanding role of LLMs in revolutionizing various stages of the drug development pipeline. We investigate how these advanced computational models can uncover target-disease linkage, interpret complex biomedical data, enhance drug molecule design, predict drug efficacy and safety profiles, and facilitate clinical trial processes. Our paper aims to provide a comprehensive overview for researchers and practitioners in computational biology, pharmacology, and AI4Science by offering insights into the potential transformative impact of LLMs on drug discovery and development.
PREM: A Simple Yet Effective Approach for Node-Level Graph Anomaly Detection
Oct 18, 2023



Node-level graph anomaly detection (GAD) plays a critical role in identifying anomalous nodes from graph-structured data in various domains such as medicine, social networks, and e-commerce. However, challenges have arisen due to the diversity of anomalies and the dearth of labeled data. Existing methodologies - reconstruction-based and contrastive learning - while effective, often suffer from efficiency issues, stemming from their complex objectives and elaborate modules. To improve the efficiency of GAD, we introduce a simple method termed PREprocessing and Matching (PREM for short). Our approach streamlines GAD, reducing time and memory consumption while maintaining powerful anomaly detection capabilities. Comprising two modules - a pre-processing module and an ego-neighbor matching module - PREM eliminates the necessity for message-passing propagation during training, and employs a simple contrastive loss, leading to considerable reductions in training time and memory usage. Moreover, through rigorous evaluations of five real-world datasets, our method demonstrated robustness and effectiveness. Notably, when validated on the ACM dataset, PREM achieved a 5% improvement in AUC, a 9-fold increase in training speed, and sharply reduce memory usage compared to the most efficient baseline.
Large Language Models for Scientific Synthesis, Inference and Explanation
Oct 12, 2023Large language models are a form of artificial intelligence systems whose primary knowledge consists of the statistical patterns, semantic relationships, and syntactical structures of language1. Despite their limited forms of "knowledge", these systems are adept at numerous complex tasks including creative writing, storytelling, translation, question-answering, summarization, and computer code generation. However, they have yet to demonstrate advanced applications in natural science. Here we show how large language models can perform scientific synthesis, inference, and explanation. We present a method for using general-purpose large language models to make inferences from scientific datasets of the form usually associated with special-purpose machine learning algorithms. We show that the large language model can augment this "knowledge" by synthesizing from the scientific literature. When a conventional machine learning system is augmented with this synthesized and inferred knowledge it can outperform the current state of the art across a range of benchmark tasks for predicting molecular properties. This approach has the further advantage that the large language model can explain the machine learning system's predictions. We anticipate that our framework will open new avenues for AI to accelerate the pace of scientific discovery.
Integrating Graphs with Large Language Models: Methods and Prospects
Oct 09, 2023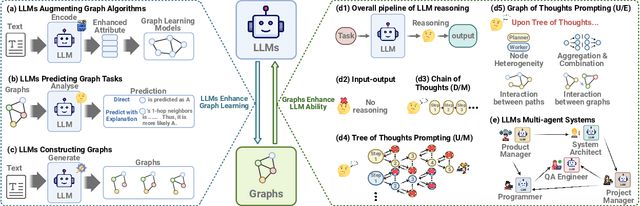
Large language models (LLMs) such as GPT-4 have emerged as frontrunners, showcasing unparalleled prowess in diverse applications, including answering queries, code generation, and more. Parallelly, graph-structured data, an intrinsic data type, is pervasive in real-world scenarios. Merging the capabilities of LLMs with graph-structured data has been a topic of keen interest. This paper bifurcates such integrations into two predominant categories. The first leverages LLMs for graph learning, where LLMs can not only augment existing graph algorithms but also stand as prediction models for various graph tasks. Conversely, the second category underscores the pivotal role of graphs in advancing LLMs. Mirroring human cognition, we solve complex tasks by adopting graphs in either reasoning or collaboration. Integrating with such structures can significantly boost the performance of LLMs in various complicated tasks. We also discuss and propose open questions for integrating LLMs with graph-structured data for the future direction of the field.
Finding the Missing-half: Graph Complementary Learning for Homophily-prone and Heterophily-prone Graphs
Jun 13, 2023



Real-world graphs generally have only one kind of tendency in their connections. These connections are either homophily-prone or heterophily-prone. While graphs with homophily-prone edges tend to connect nodes with the same class (i.e., intra-class nodes), heterophily-prone edges tend to build relationships between nodes with different classes (i.e., inter-class nodes). Existing GNNs only take the original graph during training. The problem with this approach is that it forgets to take into consideration the ``missing-half" structural information, that is, heterophily-prone topology for homophily-prone graphs and homophily-prone topology for heterophily-prone graphs. In our paper, we introduce Graph cOmplementAry Learning, namely GOAL, which consists of two components: graph complementation and complemented graph convolution. The first component finds the missing-half structural information for a given graph to complement it. The complemented graph has two sets of graphs including both homophily- and heterophily-prone topology. In the latter component, to handle complemented graphs, we design a new graph convolution from the perspective of optimisation. The experiment results show that GOAL consistently outperforms all baselines in eight real-world datasets.
A Survey on Fairness-aware Recommender Systems
Jun 01, 2023



As information filtering services, recommender systems have extremely enriched our daily life by providing personalized suggestions and facilitating people in decision-making, which makes them vital and indispensable to human society in the information era. However, as people become more dependent on them, recent studies show that recommender systems potentially own unintentional impacts on society and individuals because of their unfairness (e.g., gender discrimination in job recommendations). To develop trustworthy services, it is crucial to devise fairness-aware recommender systems that can mitigate these bias issues. In this survey, we summarise existing methodologies and practices of fairness in recommender systems. Firstly, we present concepts of fairness in different recommendation scenarios, comprehensively categorize current advances, and introduce typical methods to promote fairness in different stages of recommender systems. Next, after introducing datasets and evaluation metrics applied to assess the fairness of recommender systems, we will delve into the significant influence that fairness-aware recommender systems exert on real-world industrial applications. Subsequently, we highlight the connection between fairness and other principles of trustworthy recommender systems, aiming to consider trustworthiness principles holistically while advocating for fairness. Finally, we summarize this review, spotlighting promising opportunities in comprehending concepts, frameworks, the balance between accuracy and fairness, and the ties with trustworthiness, with the ultimate goal of fostering the development of fairness-aware recommender systems.
Dual Intent Enhanced Graph Neural Network for Session-based New Item Recommendation
May 10, 2023Recommender systems are essential to various fields, e.g., e-commerce, e-learning, and streaming media. At present, graph neural networks (GNNs) for session-based recommendations normally can only recommend items existing in users' historical sessions. As a result, these GNNs have difficulty recommending items that users have never interacted with (new items), which leads to a phenomenon of information cocoon. Therefore, it is necessary to recommend new items to users. As there is no interaction between new items and users, we cannot include new items when building session graphs for GNN session-based recommender systems. Thus, it is challenging to recommend new items for users when using GNN-based methods. We regard this challenge as '\textbf{G}NN \textbf{S}ession-based \textbf{N}ew \textbf{I}tem \textbf{R}ecommendation (GSNIR)'. To solve this problem, we propose a dual-intent enhanced graph neural network for it. Due to the fact that new items are not tied to historical sessions, the users' intent is difficult to predict. We design a dual-intent network to learn user intent from an attention mechanism and the distribution of historical data respectively, which can simulate users' decision-making process in interacting with a new item. To solve the challenge that new items cannot be learned by GNNs, inspired by zero-shot learning (ZSL), we infer the new item representation in GNN space by using their attributes. By outputting new item probabilities, which contain recommendation scores of the corresponding items, the new items with higher scores are recommended to users. Experiments on two representative real-world datasets show the superiority of our proposed method. The case study from the real-world verifies interpretability benefits brought by the dual-intent module and the new item reasoning module. The code is available at Github: https://github.com/Ee1s/NirGNN