 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCEvo: Path-Consistent Molecular Representation via Virtual Evolutionary
Jan 27, 2026Molecular representation learning aims to learn vector embeddings that capture molecular structure and geometry, thereby enabling property prediction and downstream scientific applications. In many AI for science tasks, labeled data are expensive to obtain and therefore limited in availability. Under the few-shot setting, models trained with scarce supervision often learn brittle structure-property relationships, resulting in substantially higher prediction errors and reduced generalization to unseen molecules. To address this limitation, we propose PCEvo, a path-consistent representation method that learns from virtual paths through dynamic structural evolution. PCEvo enumerates multiple chemically feasible edit paths between retrieved similar molecular pairs under topological dependency constraints. It transforms the labels of the two molecules into stepwise supervision along each virtual evolutionary path. It introduces a path-consistency objective that enforces prediction invariance across alternative paths connecting the same two molecules. Comprehensive experiments on the QM9 and MoleculeNet datasets demonstrate that PCEvo substantially improves the few-shot generalization performance of baseline methods. The code is available at https://anonymous.4open.science/r/PCEvo-4BF2.
Multi-Omics Analysis for Cancer Subtype Inference via Unrolling Graph Smoothness Priors
Aug 08, 2025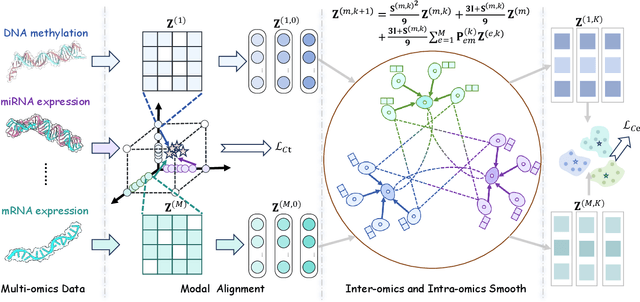
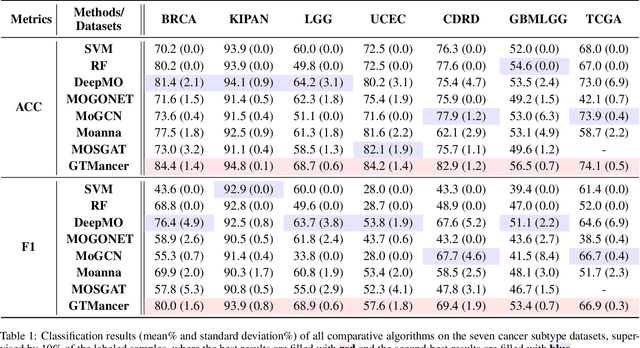
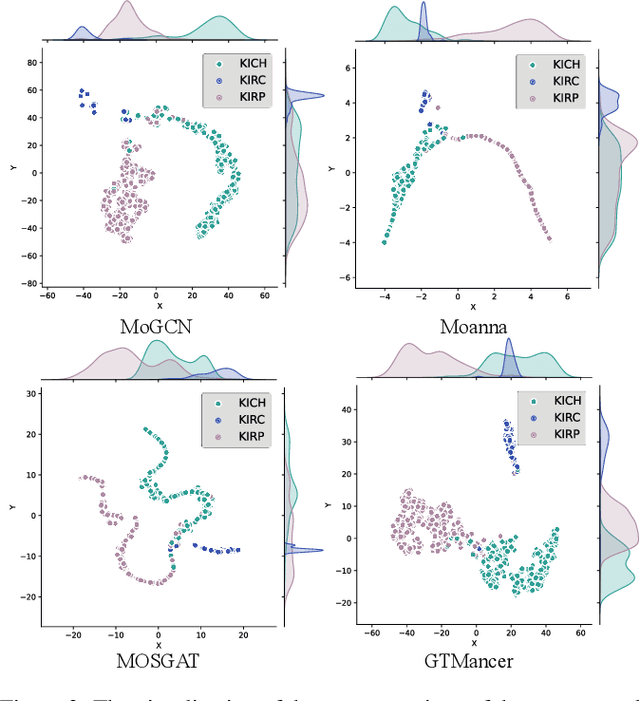
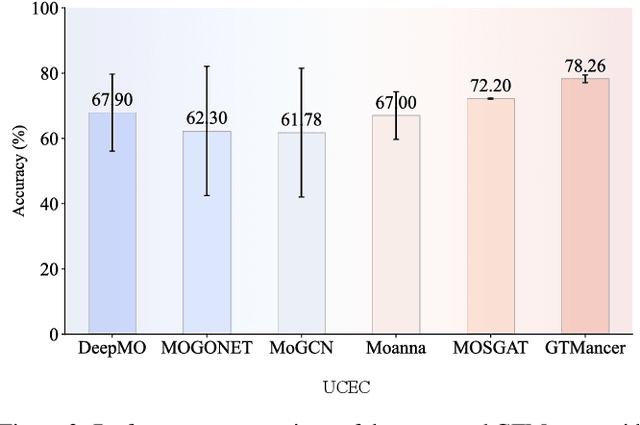
Integrating multi-omics datasets through data-driven analysis offers a comprehensive understanding of the complex biological processes underlying various diseases, particularly cancer. Graph Neural Networks (GNNs) have recently demonstrated remarkable ability to exploit relational structures in biological data, enabling advances in multi-omics integration for cancer subtype classification. Existing approaches often neglect the intricate coupling between heterogeneous omics, limiting their capacity to resolve subtle cancer subtype heterogeneity critical for precision oncology. To address these limitations, we propose a framework named Graph Transformer for Multi-omics Cancer Subtype Classification (GTMancer). This framework builds upon the GNN optimization problem and extends its application to complex multi-omics data. Specifically, our method leverages contrastive learning to embed multi-omics data into a unified semantic space. We unroll the multiplex graph optimization problem in that unified space and introduce dual sets of attention coefficients to capture structural graph priors both within and among multi-omics data. This approach enables global omics information to guide the refining of the representations of individual omics. Empirical experiments on seven real-world cancer datasets demonstrate that GTMancer outperforms existing state-of-the-art algorithms.
Collaborative Expert LLMs Guided Multi-Objective Molecular Optimization
Mar 05, 2025



Molecular optimization is a crucial yet complex and time-intensive process that often acts as a bottleneck for drug development. Traditional methods rely heavily on trial and error, making multi-objective optimization both time-consuming and resource-intensive. Current AI-based methods have shown limited success in handling multi-objective optimization tasks, hampering their practical utilization. To address this challenge, we present MultiMol, a collaborative large language model (LLM) system designed to guide multi-objective molecular optimization. MultiMol comprises two agents, including a data-driven worker agent and a literature-guided research agent. The data-driven worker agent is a large language model being fine-tuned to learn how to generate optimized molecules considering multiple objectives, while the literature-guided research agent is responsible for searching task-related literature to find useful prior knowledge that facilitates identifying the most promising optimized candidates. In evaluations across six multi-objective optimization tasks, MultiMol significantly outperforms existing methods, achieving a 82.30% success rate, in sharp contrast to the 27.50% success rate of current strongest methods. To further validate its practical impact, we tested MultiMol on two real-world challenges. First, we enhanced the selectivity of Xanthine Amine Congener (XAC), a promiscuous ligand that binds both A1R and A2AR, successfully biasing it towards A1R. Second, we improved the bioavailability of Saquinavir, an HIV-1 protease inhibitor with known bioavailability limitations. Overall, these results indicate that MultiMol represents a highly promising approach for multi-objective molecular optimization, holding great potential to accelerate the drug development process and contribute to the advancement of pharmaceutical research.
Navigating Brain Language Representations: A Comparative Analysis of Neural Language Models and Psychologically Plausible Models
Apr 30, 2024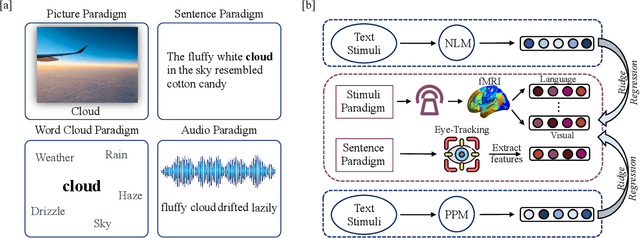


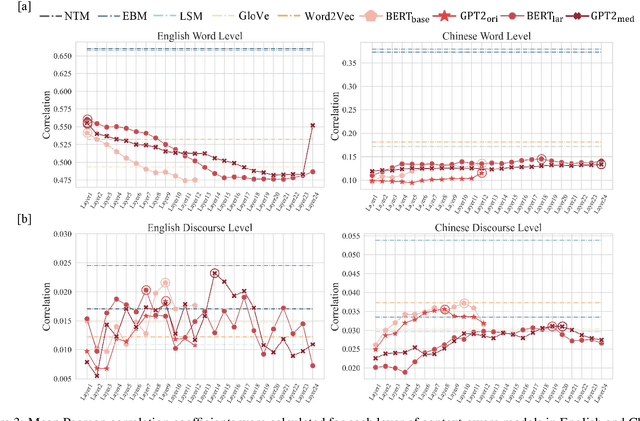
Neural language models, particularly large-scale ones, have been consistently proven to be most effective in predicting brain neural activity across a range of studies. However, previous research overlooked the comparison of these models with psychologically plausible ones. Moreover, evaluations were reliant on limited, single-modality, and English cognitive datasets. To address these questions, we conducted an analysis comparing encoding performance of various neural language models and psychologically plausible models. Our study utilized extensive multi-modal cognitive datasets, examining bilingual word and discourse levels. Surprisingly, our findings revealed that psychologically plausible models outperformed neural language models across diverse contexts, encompassing different modalities such as fMRI and eye-tracking, and spanning languages from English to Chinese. Among psychologically plausible models, the one incorporating embodied information emerged as particularly exceptional. This model demonstrated superior performance at both word and discourse levels, exhibiting robust prediction of brain activation across numerous regions in both English and Chinese.