 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComponent-Level Lesioning of Language Models Reveals Clinically Aligned Aphasia Phenotypes
Jan 27, 2026Large language models (LLMs) increasingly exhibit human-like linguistic behaviors and internal representations that they could serve as computational simulators of language cognition. We ask whether LLMs can be systematically manipulated to reproduce language-production impairments characteristic of aphasia following focal brain lesions. Such models could provide scalable proxies for testing rehabilitation hypotheses, and offer a controlled framework for probing the functional organization of language. We introduce a clinically grounded, component-level framework that simulates aphasia by selectively perturbing functional components in LLMs, and apply it to both modular Mixture-of-Experts models and dense Transformers using a unified intervention interface. Our pipeline (i) identifies subtype-linked components for Broca's and Wernicke's aphasia, (ii) interprets these components with linguistic probing tasks, and (iii) induces graded impairments by progressively perturbing the top-k subtype-linked components, evaluating outcomes with Western Aphasia Battery (WAB) subtests summarized by Aphasia Quotient (AQ). Across architectures and lesioning strategies, subtype-targeted perturbations yield more systematic, aphasia-like regressions than size-matched random perturbations, and MoE modularity supports more localized and interpretable phenotype-to-component mappings. These findings suggest that modular LLMs, combined with clinically informed component perturbations, provide a promising platform for simulating aphasic language production and studying how distinct language functions degrade under targeted disruptions.
BubbleONet: A Physics-Informed Neural Operator for High-Frequency Bubble Dynamics
Aug 05, 2025



This paper introduces BubbleONet, an operator learning model designed to map pressure profiles from an input function space to corresponding bubble radius responses. BubbleONet is built upon the physics-informed deep operator network (PI-DeepONet) framework, leveraging DeepONet's powerful universal approximation capabilities for operator learning alongside the robust physical fidelity provided by the physics-informed neural networks. To mitigate the inherent spectral bias in deep learning, BubbleONet integrates the Rowdy adaptive activation function, enabling improved representation of high-frequency features. The model is evaluated across various scenarios, including: (1) Rayleigh-Plesset equation based bubble dynamics with a single initial radius, (2) Keller-Miksis equation based bubble dynamics with a single initial radius, and (3) Keller-Miksis equation based bubble dynamics with multiple initial radii. Moreover, the performance of single-step versus two-step training techniques for BubbleONet is investigated. The results demonstrate that BubbleONet serves as a promising surrogate model for simulating bubble dynamics, offering a computationally efficient alternative to traditional numerical solvers.
How Syntax Specialization Emerges in Language Models
May 26, 2025Large language models (LLMs) have been found to develop surprising internal specializations: Individual neurons, attention heads, and circuits become selectively sensitive to syntactic structure, reflecting patterns observed in the human brain. While this specialization is well-documented, how it emerges during training and what influences its development remains largely unknown. In this work, we tap into the black box of specialization by tracking its formation over time. By quantifying internal syntactic consistency across minimal pairs from various syntactic phenomena, we identify a clear developmental trajectory: Syntactic sensitivity emerges gradually, concentrates in specific layers, and exhibits a 'critical period' of rapid internal specialization. This process is consistent across architectures and initialization parameters (e.g., random seeds), and is influenced by model scale and training data. We therefore reveal not only where syntax arises in LLMs but also how some models internalize it during training. To support future research, we will release the code, models, and training checkpoints upon acceptance.
SparseVoxFormer: Sparse Voxel-based Transformer for Multi-modal 3D Object Detection
Mar 11, 2025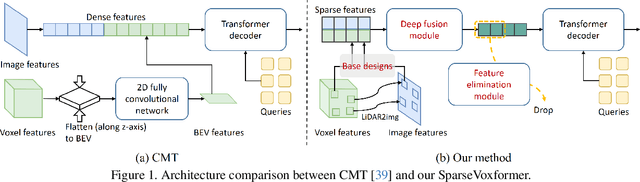

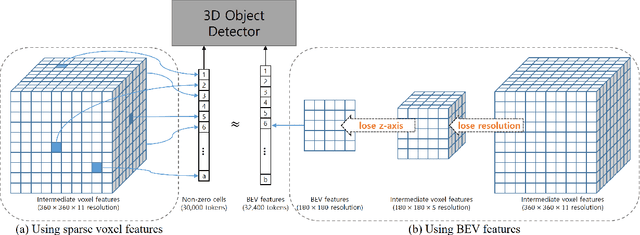
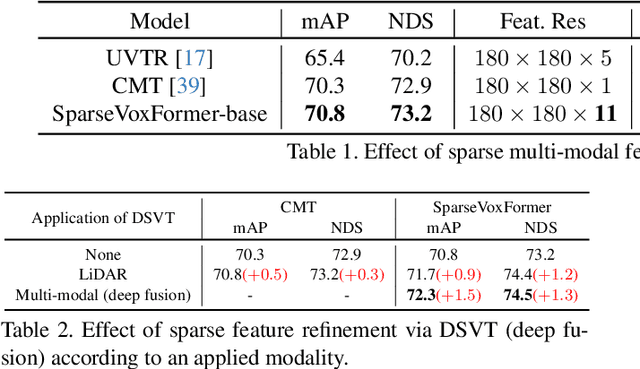
Most previous 3D object detection methods that leverage the multi-modality of LiDAR and cameras utilize the Bird's Eye View (BEV) space for intermediate feature representation. However, this space uses a low x, y-resolution and sacrifices z-axis information to reduce the overall feature resolution, which may result in declined accuracy. To tackle the problem of using low-resolution features, this paper focuses on the sparse nature of LiDAR point cloud data. From our observation, the number of occupied cells in the 3D voxels constructed from a LiDAR data can be even fewer than the number of total cells in the BEV map, despite the voxels' significantly higher resolution. Based on this, we introduce a novel sparse voxel-based transformer network for 3D object detection, dubbed as SparseVoxFormer. Instead of performing BEV feature extraction, we directly leverage sparse voxel features as the input for a transformer-based detector. Moreover, with regard to the camera modality, we introduce an explicit modality fusion approach that involves projecting 3D voxel coordinates onto 2D images and collecting the corresponding image features. Thanks to these components, our approach can leverage geometrically richer multi-modal features while even reducing the computational cost. Beyond the proof-of-concept level, we further focus on facilitating better multi-modal fusion and flexible control over the number of sparse features. Finally, thorough experimental results demonstrate that utilizing a significantly smaller number of sparse features drastically reduces computational costs in a 3D object detector while enhancing both overall and long-range performance.
LinSATNet: The Positive Linear Satisfiability Neural Networks
Jul 18, 2024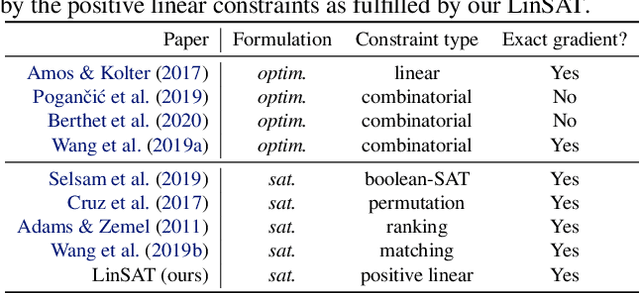
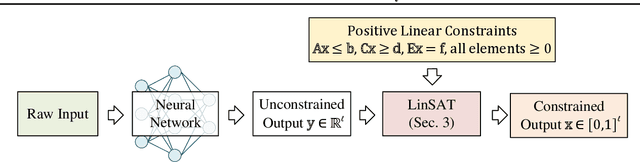
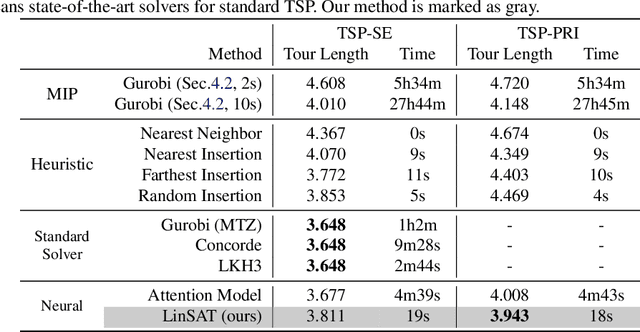
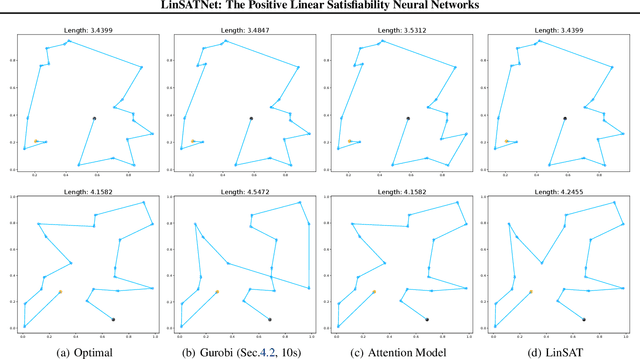
Encoding constraints into neural networks is attractive. This paper studies how to introduce the popular positive linear satisfiability to neural networks. We propose the first differentiable satisfiability layer based on an extension of the classic Sinkhorn algorithm for jointly encoding multiple sets of marginal distributions. We further theoretically characterize the convergence property of the Sinkhorn algorithm for multiple marginals. In contrast to the sequential decision e.g.\ reinforcement learning-based solvers, we showcase our technique in solving constrained (specifically satisfiability) problems by one-shot neural networks, including i) a neural routing solver learned without supervision of optimal solutions; ii) a partial graph matching network handling graphs with unmatchable outliers on both sides; iii) a predictive network for financial portfolios with continuous constraints. To our knowledge, there exists no one-shot neural solver for these scenarios when they are formulated as satisfiability problems. Source code is available at https://github.com/Thinklab-SJTU/LinSATNet
Navigating Brain Language Representations: A Comparative Analysis of Neural Language Models and Psychologically Plausible Models
Apr 30, 2024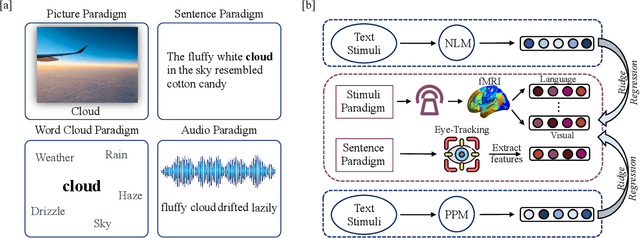


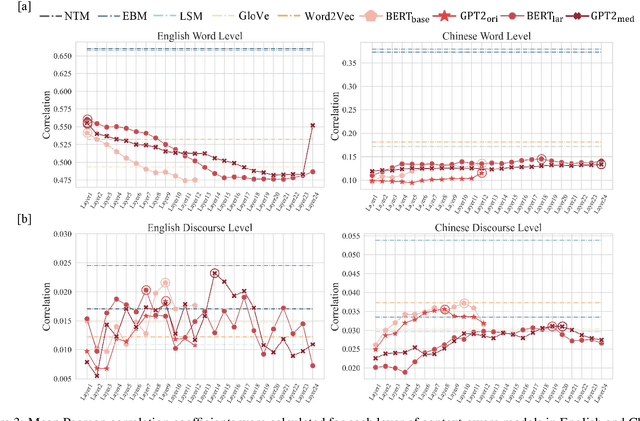
Neural language models, particularly large-scale ones, have been consistently proven to be most effective in predicting brain neural activity across a range of studies. However, previous research overlooked the comparison of these models with psychologically plausible ones. Moreover, evaluations were reliant on limited, single-modality, and English cognitive datasets. To address these questions, we conducted an analysis comparing encoding performance of various neural language models and psychologically plausible models. Our study utilized extensive multi-modal cognitive datasets, examining bilingual word and discourse levels. Surprisingly, our findings revealed that psychologically plausible models outperformed neural language models across diverse contexts, encompassing different modalities such as fMRI and eye-tracking, and spanning languages from English to Chinese. Among psychologically plausible models, the one incorporating embodied information emerged as particularly exceptional. This model demonstrated superior performance at both word and discourse levels, exhibiting robust prediction of brain activation across numerous regions in both English and Chinese.
Computational Models to Study Language Processing in the Human Brain: A Survey
Mar 20, 2024



Despite differing from the human language processing mechanism in implementation and algorithms, current language models demonstrate remarkable human-like or surpassing language capabilities. Should computational language models be employed in studying the brain, and if so, when and how? To delve into this topic, this paper reviews efforts in using computational models for brain research, highlighting emerging trends. To ensure a fair comparison, the paper evaluates various computational models using consistent metrics on the same dataset. Our analysis reveals that no single model outperforms others on all datasets, underscoring the need for rich testing datasets and rigid experimental control to draw robust conclusions in studies involving computational models.
MulCogBench: A Multi-modal Cognitive Benchmark Dataset for Evaluating Chinese and English Computational Language Models
Mar 02, 2024Pre-trained computational language models have recently made remarkable progress in harnessing the language abilities which were considered unique to humans. Their success has raised interest in whether these models represent and process language like humans. To answer this question, this paper proposes MulCogBench, a multi-modal cognitive benchmark dataset collected from native Chinese and English participants. It encompasses a variety of cognitive data, including subjective semantic ratings, eye-tracking, functional magnetic resonance imaging (fMRI), and magnetoencephalography (MEG). To assess the relationship between language models and cognitive data, we conducted a similarity-encoding analysis which decodes cognitive data based on its pattern similarity with textual embeddings. Results show that language models share significant similarities with human cognitive data and the similarity patterns are modulated by the data modality and stimuli complexity. Specifically, context-aware models outperform context-independent models as language stimulus complexity increases. The shallow layers of context-aware models are better aligned with the high-temporal-resolution MEG signals whereas the deeper layers show more similarity with the high-spatial-resolution fMRI. These results indicate that language models have a delicate relationship with brain language representations. Moreover, the results between Chinese and English are highly consistent, suggesting the generalizability of these findings across languages.
Interpreting and Exploiting Functional Specialization in Multi-Head Attention under Multi-task Learning
Oct 16, 2023

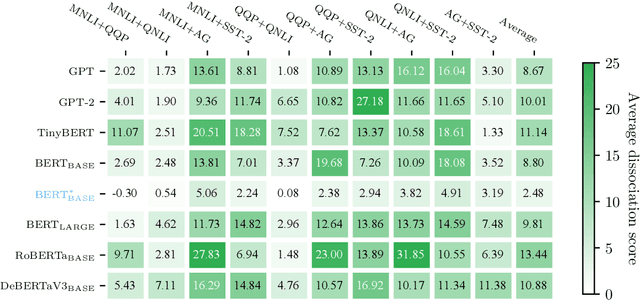

Transformer-based models, even though achieving super-human performance on several downstream tasks, are often regarded as a black box and used as a whole. It is still unclear what mechanisms they have learned, especially their core module: multi-head attention. Inspired by functional specialization in the human brain, which helps to efficiently handle multiple tasks, this work attempts to figure out whether the multi-head attention module will evolve similar function separation under multi-tasking training. If it is, can this mechanism further improve the model performance? To investigate these questions, we introduce an interpreting method to quantify the degree of functional specialization in multi-head attention. We further propose a simple multi-task training method to increase functional specialization and mitigate negative information transfer in multi-task learning. Experimental results on seven pre-trained transformer models have demonstrated that multi-head attention does evolve functional specialization phenomenon after multi-task training which is affected by the similarity of tasks. Moreover, the multi-task training strategy based on functional specialization boosts performance in both multi-task learning and transfer learning without adding any parameters.
Contrast, Attend and Diffuse to Decode High-Resolution Images from Brain Activities
May 26, 2023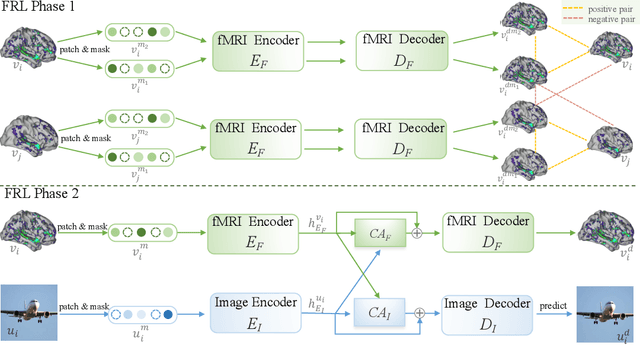
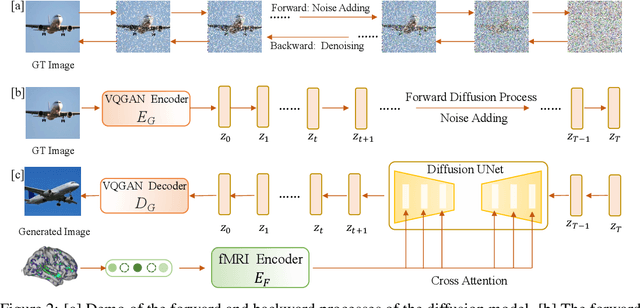


Decoding visual stimuli from neural responses recorded by functional Magnetic Resonance Imaging (fMRI) presents an intriguing intersection between cognitive neuroscience and machine learning, promising advancements in understanding human visual perception and building non-invasive brain-machine interfaces. However, the task is challenging due to the noisy nature of fMRI signals and the intricate pattern of brain visual representations. To mitigate these challenges, we introduce a two-phase fMRI representation learning framework. The first phase pre-trains an fMRI feature learner with a proposed Double-contrastive Mask Auto-encoder to learn denoised representations. The second phase tunes the feature learner to attend to neural activation patterns most informative for visual reconstruction with guidance from an image auto-encoder. The optimized fMRI feature learner then conditions a latent diffusion model to reconstruct image stimuli from brain activities. Experimental results demonstrate our model's superiority in generating high-resolution and semantically accurate images, substantially exceeding previous state-of-the-art methods by 39.34% in the 50-way-top-1 semantic classification accuracy. Our research invites further exploration of the decoding task's potential and contributes to the development of non-invasive brain-machine interfaces.