 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComponent-Level Lesioning of Language Models Reveals Clinically Aligned Aphasia Phenotypes
Jan 27, 2026Large language models (LLMs) increasingly exhibit human-like linguistic behaviors and internal representations that they could serve as computational simulators of language cognition. We ask whether LLMs can be systematically manipulated to reproduce language-production impairments characteristic of aphasia following focal brain lesions. Such models could provide scalable proxies for testing rehabilitation hypotheses, and offer a controlled framework for probing the functional organization of language. We introduce a clinically grounded, component-level framework that simulates aphasia by selectively perturbing functional components in LLMs, and apply it to both modular Mixture-of-Experts models and dense Transformers using a unified intervention interface. Our pipeline (i) identifies subtype-linked components for Broca's and Wernicke's aphasia, (ii) interprets these components with linguistic probing tasks, and (iii) induces graded impairments by progressively perturbing the top-k subtype-linked components, evaluating outcomes with Western Aphasia Battery (WAB) subtests summarized by Aphasia Quotient (AQ). Across architectures and lesioning strategies, subtype-targeted perturbations yield more systematic, aphasia-like regressions than size-matched random perturbations, and MoE modularity supports more localized and interpretable phenotype-to-component mappings. These findings suggest that modular LLMs, combined with clinically informed component perturbations, provide a promising platform for simulating aphasic language production and studying how distinct language functions degrade under targeted disruptions.
How Syntax Specialization Emerges in Language Models
May 26, 2025Large language models (LLMs) have been found to develop surprising internal specializations: Individual neurons, attention heads, and circuits become selectively sensitive to syntactic structure, reflecting patterns observed in the human brain. While this specialization is well-documented, how it emerges during training and what influences its development remains largely unknown. In this work, we tap into the black box of specialization by tracking its formation over time. By quantifying internal syntactic consistency across minimal pairs from various syntactic phenomena, we identify a clear developmental trajectory: Syntactic sensitivity emerges gradually, concentrates in specific layers, and exhibits a 'critical period' of rapid internal specialization. This process is consistent across architectures and initialization parameters (e.g., random seeds), and is influenced by model scale and training data. We therefore reveal not only where syntax arises in LLMs but also how some models internalize it during training. To support future research, we will release the code, models, and training checkpoints upon acceptance.
Coherent Language Reconstruction from Brain Recordings with Flexible Multi-Modal Input Stimuli
May 15, 2025Decoding thoughts from brain activity offers valuable insights into human cognition and enables promising applications in brain-computer interaction. While prior studies have explored language reconstruction from fMRI data, they are typically limited to single-modality inputs such as images or audio. In contrast, human thought is inherently multimodal. To bridge this gap, we propose a unified and flexible framework for reconstructing coherent language from brain recordings elicited by diverse input modalities-visual, auditory, and textual. Our approach leverages visual-language models (VLMs), using modality-specific experts to jointly interpret information across modalities. Experiments demonstrate that our method achieves performance comparable to state-of-the-art systems while remaining adaptable and extensible. This work advances toward more ecologically valid and generalizable mind decoding.
X-Instruction: Aligning Language Model in Low-resource Languages with Self-curated Cross-lingual Instructions
May 30, 2024Large language models respond well in high-resource languages like English but struggle in low-resource languages. It may arise from the lack of high-quality instruction following data in these languages. Directly translating English samples into these languages can be a solution but unreliable, leading to responses with translation errors and lacking language-specific or cultural knowledge. To address this issue, we propose a novel method to construct cross-lingual instruction following samples with instruction in English and response in low-resource languages. Specifically, the language model first learns to generate appropriate English instructions according to the natural web texts in other languages as responses. The candidate cross-lingual instruction tuning samples are further refined and diversified. We have employed this method to build a large-scale cross-lingual instruction tuning dataset on 10 languages, namely X-Instruction. The instruction data built using our method incorporate more language-specific knowledge compared with the naive translation method. Experimental results have shown that the response quality of the model tuned on X-Instruction greatly exceeds the model distilled from a powerful teacher model, reaching or even surpassing the ones of ChatGPT. In addition, we find that models tuned on cross-lingual instruction following samples can follow the instruction in the output language without further tuning.
Navigating Brain Language Representations: A Comparative Analysis of Neural Language Models and Psychologically Plausible Models
Apr 30, 2024


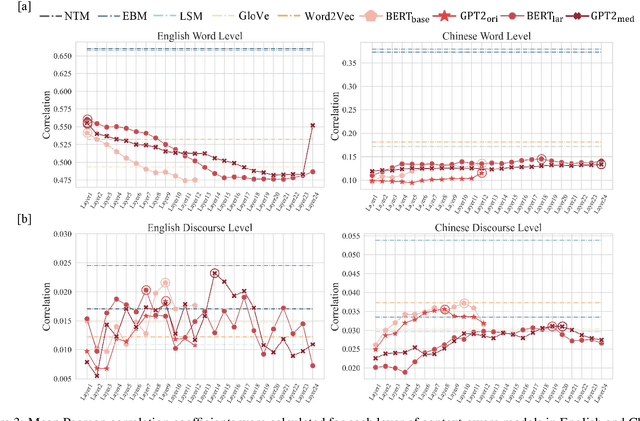
Neural language models, particularly large-scale ones, have been consistently proven to be most effective in predicting brain neural activity across a range of studies. However, previous research overlooked the comparison of these models with psychologically plausible ones. Moreover, evaluations were reliant on limited, single-modality, and English cognitive datasets. To address these questions, we conducted an analysis comparing encoding performance of various neural language models and psychologically plausible models. Our study utilized extensive multi-modal cognitive datasets, examining bilingual word and discourse levels. Surprisingly, our findings revealed that psychologically plausible models outperformed neural language models across diverse contexts, encompassing different modalities such as fMRI and eye-tracking, and spanning languages from English to Chinese. Among psychologically plausible models, the one incorporating embodied information emerged as particularly exceptional. This model demonstrated superior performance at both word and discourse levels, exhibiting robust prediction of brain activation across numerous regions in both English and Chinese.
MapGuide: A Simple yet Effective Method to Reconstruct Continuous Language from Brain Activities
Apr 02, 2024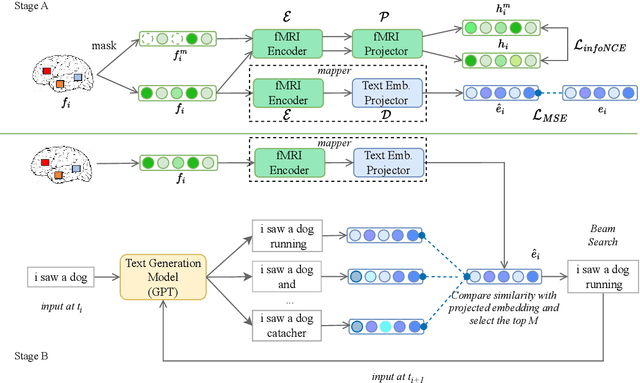
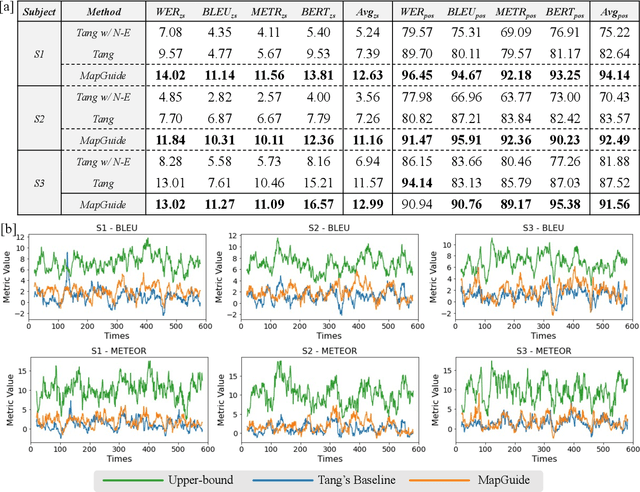
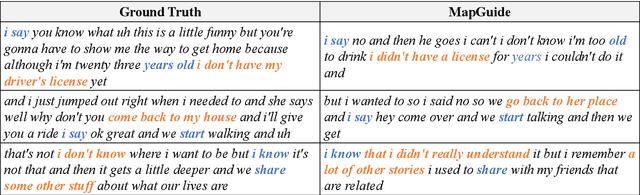
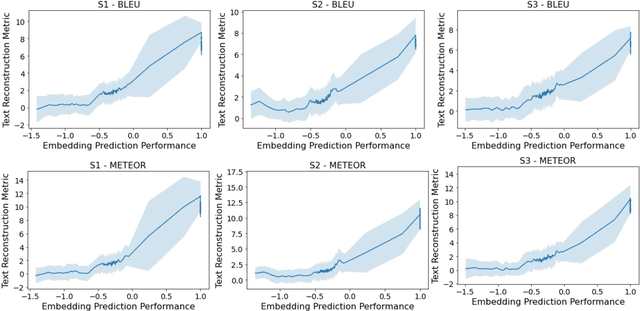
Decoding continuous language from brain activity is a formidable yet promising field of research. It is particularly significant for aiding people with speech disabilities to communicate through brain signals. This field addresses the complex task of mapping brain signals to text. The previous best attempt reverse-engineered this process in an indirect way: it began by learning to encode brain activity from text and then guided text generation by aligning with predicted brain responses. In contrast, we propose a simple yet effective method that guides text reconstruction by directly comparing them with the predicted text embeddings mapped from brain activities. Comprehensive experiments reveal that our method significantly outperforms the current state-of-the-art model, showing average improvements of 77% and 54% on BLEU and METEOR scores. We further validate the proposed modules through detailed ablation studies and case analyses and highlight a critical correlation: the more precisely we map brain activities to text embeddings, the better the text reconstruction results. Such insight can simplify the task of reconstructing language from brain activities for future work, emphasizing the importance of improving brain-to-text-embedding mapping techniques.
Computational Models to Study Language Processing in the Human Brain: A Survey
Mar 20, 2024



Despite differing from the human language processing mechanism in implementation and algorithms, current language models demonstrate remarkable human-like or surpassing language capabilities. Should computational language models be employed in studying the brain, and if so, when and how? To delve into this topic, this paper reviews efforts in using computational models for brain research, highlighting emerging trends. To ensure a fair comparison, the paper evaluates various computational models using consistent metrics on the same dataset. Our analysis reveals that no single model outperforms others on all datasets, underscoring the need for rich testing datasets and rigid experimental control to draw robust conclusions in studies involving computational models.
MulCogBench: A Multi-modal Cognitive Benchmark Dataset for Evaluating Chinese and English Computational Language Models
Mar 02, 2024Pre-trained computational language models have recently made remarkable progress in harnessing the language abilities which were considered unique to humans. Their success has raised interest in whether these models represent and process language like humans. To answer this question, this paper proposes MulCogBench, a multi-modal cognitive benchmark dataset collected from native Chinese and English participants. It encompasses a variety of cognitive data, including subjective semantic ratings, eye-tracking, functional magnetic resonance imaging (fMRI), and magnetoencephalography (MEG). To assess the relationship between language models and cognitive data, we conducted a similarity-encoding analysis which decodes cognitive data based on its pattern similarity with textual embeddings. Results show that language models share significant similarities with human cognitive data and the similarity patterns are modulated by the data modality and stimuli complexity. Specifically, context-aware models outperform context-independent models as language stimulus complexity increases. The shallow layers of context-aware models are better aligned with the high-temporal-resolution MEG signals whereas the deeper layers show more similarity with the high-spatial-resolution fMRI. These results indicate that language models have a delicate relationship with brain language representations. Moreover, the results between Chinese and English are highly consistent, suggesting the generalizability of these findings across languages.
A Self-supervised Pressure Map human keypoint Detection Approch: Optimizing Generalization and Computational Efficiency Across Datasets
Feb 22, 2024



In environments where RGB images are inadequate, pressure maps is a viable alternative, garnering scholarly attention. This study introduces a novel self-supervised pressure map keypoint detection (SPMKD) method, addressing the current gap in specialized designs for human keypoint extraction from pressure maps. Central to our contribution is the Encoder-Fuser-Decoder (EFD) model, which is a robust framework that integrates a lightweight encoder for precise human keypoint detection, a fuser for efficient gradient propagation, and a decoder that transforms human keypoints into reconstructed pressure maps. This structure is further enhanced by the Classification-to-Regression Weight Transfer (CRWT) method, which fine-tunes accuracy through initial classification task training. This innovation not only enhances human keypoint generalization without manual annotations but also showcases remarkable efficiency and generalization, evidenced by a reduction to only $5.96\%$ in FLOPs and $1.11\%$ in parameter count compared to the baseline methods.
Align after Pre-train: Improving Multilingual Generative Models with Cross-lingual Alignment
Nov 14, 2023Multilingual generative models obtain remarkable cross-lingual capabilities through pre-training on large-scale corpora. However, they still exhibit a performance bias toward high-resource languages, and learn isolated distributions of sentence representations across languages. To bridge this gap, we propose a simple yet effective alignment framework exploiting pairs of translation sentences. It aligns the internal sentence representations across different languages via multilingual contrastive learning and aligns model outputs by answering prompts in different languages. Experimental results demonstrate that even with less than 0.1 {\textperthousand} of pre-training tokens, our alignment framework significantly boosts the cross-lingual abilities of generative models and mitigates the performance gap. Further analysis reveals that it results in a better internal multilingual representation distribution of multilingual models.