 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the encoding competence of visual language models using uncommon actions
Jan 12, 2026We propose UAIT (Uncommon-sense Action Image-Text) dataset, a new evaluation benchmark designed to test the semantic understanding ability of visual language models (VLMs) in uncommon-sense action scenes. Unlike previous datasets that focus on common visual scenes with statistical frequency advantages, UAIT challenges models with grammatically reasonable but semantically counter-common sense image-text pairs. Such tasks require models to go beyond superficial pattern recognition and demonstrate a deep understanding of agent-patient relationships and physical feasibility. To build UAIT, we designed a semi-automated process to synthesize high-quality uncommon-sense image-text samples using large language models, few-shot prompt engineering, and text-to-image generation. Each sample is accompanied by a carefully designed multiple-choice question to test the model's competence in fine-grained reasoning. We evaluate multiple state-of-the-art visual language models and compare them with models based on contrastive learning. Experiments show that all models perform significantly worse than humans in semantic judgment, especially in distinguishing grammatical correctness from semantic rationality. Further experiments show that even the lightweight model can improve its accuracy after fine-tuning, demonstrating the great potential of directional adaptation. This study not only reveals the key weaknesses of VLMs, but also provides diagnostic tools and research directions for the development of robust models with real visual semantic reasoning capabilities.
Active Use of Latent Constituency Representation in both Humans and Large Language Models
May 28, 2024



Understanding how sentences are internally represented in the human brain, as well as in large language models (LLMs) such as ChatGPT, is a major challenge for cognitive science. Classic linguistic theories propose that the brain represents a sentence by parsing it into hierarchically organized constituents. In contrast, LLMs do not explicitly parse linguistic constituents and their latent representations remains poorly explained. Here, we demonstrate that humans and LLMs construct similar latent representations of hierarchical linguistic constituents by analyzing their behaviors during a novel one-shot learning task, in which they infer which words should be deleted from a sentence. Both humans and LLMs tend to delete a constituent, instead of a nonconstituent word string. In contrast, a naive sequence processing model that has access to word properties and ordinal positions does not show this property. Based on the word deletion behaviors, we can reconstruct the latent constituency tree representation of a sentence for both humans and LLMs. These results demonstrate that a latent tree-structured constituency representation can emerge in both the human brain and LLMs.
Probing the Creativity of Large Language Models: Can models produce divergent semantic association?
Oct 17, 2023



Large language models possess remarkable capacity for processing language, but it remains unclear whether these models can further generate creative content. The present study aims to investigate the creative thinking of large language models through a cognitive perspective. We utilize the divergent association task (DAT), an objective measurement of creativity that asks models to generate unrelated words and calculates the semantic distance between them. We compare the results across different models and decoding strategies. Our findings indicate that: (1) When using the greedy search strategy, GPT-4 outperforms 96% of humans, while GPT-3.5-turbo exceeds the average human level. (2) Stochastic sampling and temperature scaling are effective to obtain higher DAT scores for models except GPT-4, but face a trade-off between creativity and stability. These results imply that advanced large language models have divergent semantic associations, which is a fundamental process underlying creativity.
Holistic Dynamic Frequency Transformer for Image Fusion and Exposure Correction
Sep 03, 2023

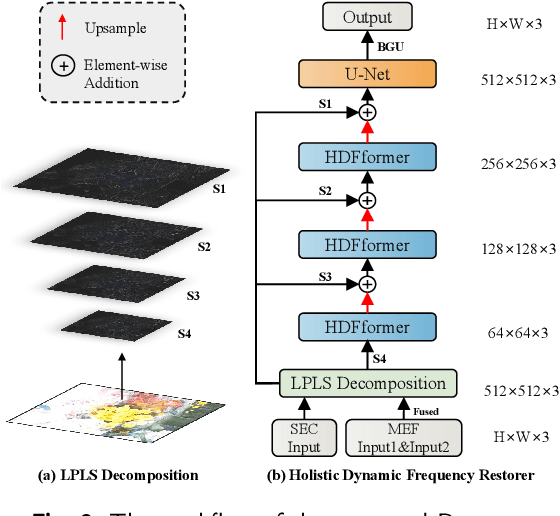

The correction of exposure-related issues is a pivotal component in enhancing the quality of images, offering substantial implications for various computer vision tasks. Historically, most methodologies have predominantly utilized spatial domain recovery, offering limited consideration to the potentialities of the frequency domain. Additionally, there has been a lack of a unified perspective towards low-light enhancement, exposure correction, and multi-exposure fusion, complicating and impeding the optimization of image processing. In response to these challenges, this paper proposes a novel methodology that leverages the frequency domain to improve and unify the handling of exposure correction tasks. Our method introduces Holistic Frequency Attention and Dynamic Frequency Feed-Forward Network, which replace conventional correlation computation in the spatial-domain. They form a foundational building block that facilitates a U-shaped Holistic Dynamic Frequency Transformer as a filter to extract global information and dynamically select important frequency bands for image restoration. Complementing this, we employ a Laplacian pyramid to decompose images into distinct frequency bands, followed by multiple restorers, each tuned to recover specific frequency-band information. The pyramid fusion allows a more detailed and nuanced image restoration process. Ultimately, our structure unifies the three tasks of low-light enhancement, exposure correction, and multi-exposure fusion, enabling comprehensive treatment of all classical exposure errors. Benchmarking on mainstream datasets for these tasks, our proposed method achieves state-of-the-art results, paving the way for more sophisticated and unified solutions in exposure correction.
Causal Interpretable Progression Trajectory Analysis of Chronic Disease
Aug 18, 2023Chronic disease is the leading cause of death, emphasizing the need for accurate prediction of disease progression trajectories and informed clinical decision-making. Machine learning (ML) models have shown promise in this domain by capturing non-linear patterns within patient features. However, existing ML-based models lack the ability to provide causal interpretable predictions and estimate treatment effects, limiting their decision-assisting perspective. In this study, we propose a novel model called causal trajectory prediction (CTP) to tackle the limitation. The CTP model combines trajectory prediction and causal discovery to enable accurate prediction of disease progression trajectories and uncovering causal relationships between features. By incorporating a causal graph into the prediction process, CTP ensures that ancestor features are not influenced by treatment on descendant features, thereby enhancing the interpretability of the model. By estimating the bounds of treatment effects, even in the presence of unmeasured confounders, the CTP provides valuable insights for clinical decision-making. We evaluate the performance of the CTP using simulated and real medical datasets. Experimental results demonstrate that our model achieves satisfactory performance, highlighting its potential to assist clinical decisions.
Replicating Complex Dialogue Policy of Humans via Offline Imitation Learning with Supervised Regularization
May 06, 2023Policy learning (PL) is a module of a task-oriented dialogue system that trains an agent to make actions in each dialogue turn. Imitating human action is a fundamental problem of PL. However, both supervised learning (SL) and reinforcement learning (RL) frameworks cannot imitate humans well. Training RL models require online interactions with user simulators, while simulating complex human policy is hard. Performances of SL-based models are restricted because of the covariate shift problem. Specifically, a dialogue is a sequential decision-making process where slight differences in current utterances and actions will cause significant differences in subsequent utterances. Therefore, the generalize ability of SL models is restricted because statistical characteristics of training and testing dialogue data gradually become different. This study proposed an offline imitation learning model that learns policy from real dialogue datasets and does not require user simulators. It also utilizes state transition information, which alleviates the influence of the covariate shift problem. We introduced a regularization trick to make our model can be effectively optimized. We investigated the performance of our model on four independent public dialogue datasets. The experimental result showed that our model performed better in the action prediction task.
Acoustic correlates of the syllabic rhythm of speech: Modulation spectrum or local features of the temporal envelope
Jan 14, 2023The syllable is a perceptually salient unit in speech. Since both the syllable and its acoustic correlate, i.e., the speech envelope, have a preferred range of rhythmicity between 4 and 8 Hz, it is hypothesized that theta-band neural oscillations play a major role in extracting syllables based on the envelope. A literature survey, however, reveals inconsistent evidence about the relationship between speech envelope and syllables, and the current study revisits this question by analyzing large speech corpora. It is shown that the center frequency of speech envelope, characterized by the modulation spectrum, reliably correlates with the rate of syllables only when the analysis is pooled over minutes of speech recordings. In contrast, in the time domain, a component of the speech envelope is reliably phase-locked to syllable onsets. Based on a speaker-independent model, the timing of syllable onsets explains about 24% variance of the speech envelope. These results indicate that local features in the speech envelope, instead of the modulation spectrum, are a more reliable acoustic correlate of syllables.
Language Cognition and Language Computation -- Human and Machine Language Understanding
Jan 12, 2023Language understanding is a key scientific issue in the fields of cognitive and computer science. However, the two disciplines differ substantially in the specific research questions. Cognitive science focuses on analyzing the specific mechanism of the brain and investigating the brain's response to language; few studies have examined the brain's language system as a whole. By contrast, computer scientists focus on the efficiency of practical applications when choosing research questions but may ignore the most essential laws of language. Given these differences, can a combination of the disciplines offer new insights for building intelligent language models and studying language cognitive mechanisms? In the following text, we first review the research questions, history, and methods of language understanding in cognitive and computer science, focusing on the current progress and challenges. We then compare and contrast the research of language understanding in cognitive and computer sciences. Finally, we review existing work that combines insights from language cognition and language computation and offer prospects for future development trends.
Interpretation and Analysis of the Steady-State Neural Response to Complex Sequential Structures: a Methodological Note
Jan 03, 2023



Frequency tagging is a powerful approach to investigate the neural processing of sensory features, and is recently adapted to study the neural correlates of superordinate structures, i.e., chunks, in complex sequences such as speech and music. The nesting of sequence structures, the necessity to control the periodicity in sensory features, and the low-frequency nature of sequence structures pose new challenges for data analysis and interpretation. Here, I discuss how to interpret the frequency of a sequential structure, and factors that need to be considered when analyzing the periodicity in a signal. Finally, a safe procedure is recommended for the analysis of frequency-tagged responses.
The Neural Correlates of Linguistic Structure Building: Comments on Kazanina & Tavano (2022)
Dec 08, 2022
A recent perspective paper by Kazanina & Tavano (referred to as the KT perspective in the following) argues how neural oscillations cannot provide a potential neural correlate for syntactic structure building. The view that neural oscillations can provide a potential neural correlate for syntactic structure building is largely attributed to a study by Ding, Melloni, Zhang, Tian, and Poeppel in 2016 (referred to as the DMZTP study). The KT perspective is thought provoking, but has severe misinterpretations about the arguments in DMZTP and other studies, and contains contradictory conclusions in different parts of the perspective, making it impossible to understand the position of the authors. In the following, I summarize a few misinterpretations and inconsistent arguments in the KT perspective, and put forward a few suggestions for future studies.