 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcoustic correlates of the syllabic rhythm of speech: Modulation spectrum or local features of the temporal envelope
Jan 14, 2023The syllable is a perceptually salient unit in speech. Since both the syllable and its acoustic correlate, i.e., the speech envelope, have a preferred range of rhythmicity between 4 and 8 Hz, it is hypothesized that theta-band neural oscillations play a major role in extracting syllables based on the envelope. A literature survey, however, reveals inconsistent evidence about the relationship between speech envelope and syllables, and the current study revisits this question by analyzing large speech corpora. It is shown that the center frequency of speech envelope, characterized by the modulation spectrum, reliably correlates with the rate of syllables only when the analysis is pooled over minutes of speech recordings. In contrast, in the time domain, a component of the speech envelope is reliably phase-locked to syllable onsets. Based on a speaker-independent model, the timing of syllable onsets explains about 24% variance of the speech envelope. These results indicate that local features in the speech envelope, instead of the modulation spectrum, are a more reliable acoustic correlate of syllables.
Deep Neural Networks Evolve Human-like Attention Distribution during Reading Comprehension
Jul 13, 2021



Attention is a key mechanism for information selection in both biological brains and many state-of-the-art deep neural networks (DNNs). Here, we investigate whether humans and DNNs allocate attention in comparable ways when reading a text passage to subsequently answer a specific question. We analyze 3 transformer-based DNNs that reach human-level performance when trained to perform the reading comprehension task. We find that the DNN attention distribution quantitatively resembles human attention distribution measured by fixation times. Human readers fixate longer on words that are more relevant to the question-answering task, demonstrating that attention is modulated by top-down reading goals, on top of lower-level visual and text features of the stimulus. Further analyses reveal that the attention weights in DNNs are also influenced by both top-down reading goals and lower-level stimulus features, with the shallow layers more strongly influenced by lower-level text features and the deep layers attending more to task-relevant words. Additionally, deep layers' attention to task-relevant words gradually emerges when pre-trained DNN models are fine-tuned to perform the reading comprehension task, which coincides with the improvement in task performance. These results demonstrate that DNNs can evolve human-like attention distribution through task optimization, which suggests that human attention during goal-directed reading comprehension is a consequence of task optimization.
PALRACE: Reading Comprehension Dataset with Human Data and Labeled Rationales
Jun 23, 2021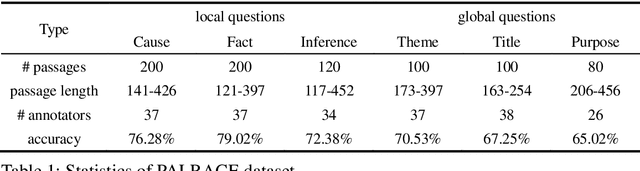
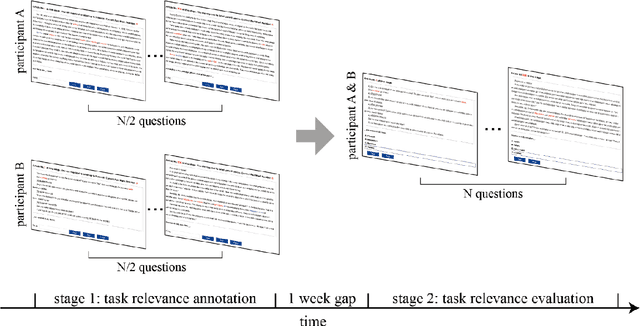
Pre-trained language models achieves high performance on machine reading comprehension (MRC) tasks but the results are hard to explain. An appealing approach to make models explainable is to provide rationales for its decision. To facilitate supervised learning of human rationales, here we present PALRACE (Pruned And Labeled RACE), a new MRC dataset with human labeled rationales for 800 passages selected from the RACE dataset. We further classified the question to each passage into 6 types. Each passage was read by at least 26 participants, who labeled their rationales to answer the question. Besides, we conducted a rationale evaluation session in which participants were asked to answering the question solely based on labeled rationales, confirming that the labeled rationales were of high quality and can sufficiently support question answering.
Using Adversarial Attacks to Reveal the Statistical Bias in Machine Reading Comprehension Models
May 25, 2021



Pre-trained language models have achieved human-level performance on many Machine Reading Comprehension (MRC) tasks, but it remains unclear whether these models truly understand language or answer questions by exploiting statistical biases in datasets. Here, we demonstrate a simple yet effective method to attack MRC models and reveal the statistical biases in these models. We apply the method to the RACE dataset, for which the answer to each MRC question is selected from 4 options. It is found that several pre-trained language models, including BERT, ALBERT, and RoBERTa, show consistent preference to some options, even when these options are irrelevant to the question. When interfered by these irrelevant options, the performance of MRC models can be reduced from human-level performance to the chance-level performance. Human readers, however, are not clearly affected by these irrelevant options. Finally, we propose an augmented training method that can greatly reduce models' statistical biases.