 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDe-biased Multimodal Electrocardiogram Analysis
Nov 22, 2024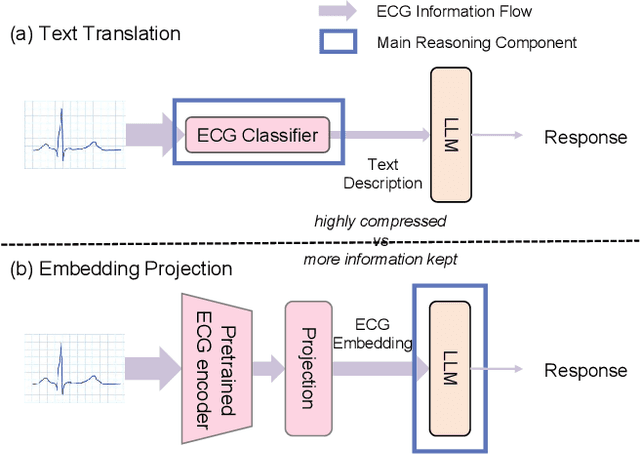

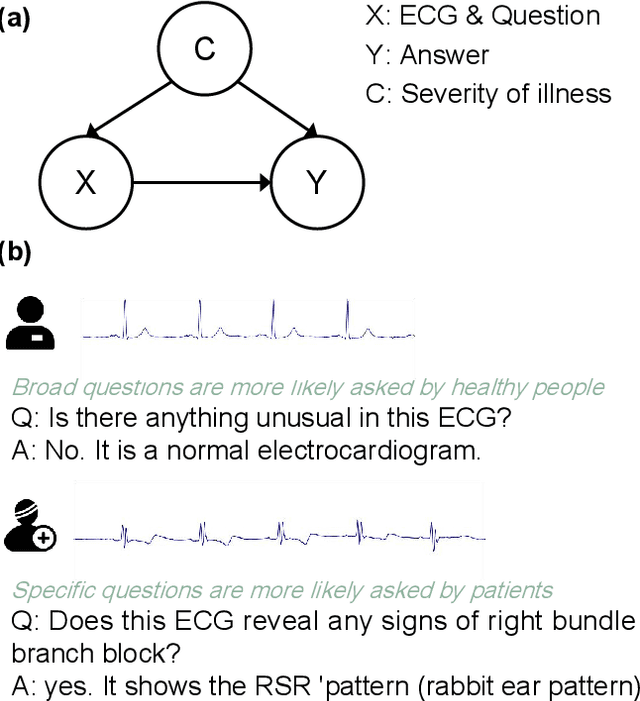

Multimodal large language models (MLLMs) are increasingly being applied in the medical field, particularly in medical imaging. However, developing MLLMs for ECG signals, which are crucial in clinical settings, has been a significant challenge beyond medical imaging. Previous studies have attempted to address this by converting ECGs into several text tags using an external classifier in a training-free manner. However, this approach significantly compresses the information in ECGs and underutilizes the reasoning capabilities of LLMs. In this work, we directly feed the embeddings of ECGs into the LLM through a projection layer, retaining more information about ECGs and better leveraging the reasoning abilities of LLMs. Our method can also effectively handle a common situation in clinical practice where it is necessary to compare two ECGs taken at different times. Recent studies found that MLLMs may rely solely on text input to provide answers, ignoring inputs from other modalities. We analyzed this phenomenon from a causal perspective in the context of ECG MLLMs and discovered that the confounder, severity of illness, introduces a spurious correlation between the question and answer, leading the model to rely on this spurious correlation and ignore the ECG input. Such models do not comprehend the ECG input and perform poorly in adversarial tests where different expressions of the same question are used in the training and testing sets. We designed a de-biased pre-training method to eliminate the confounder's effect according to the theory of backdoor adjustment. Our model performed well on the ECG-QA task under adversarial testing and demonstrated zero-shot capabilities. An interesting random ECG test further validated that our model effectively understands and utilizes the input ECG signal.
Conversational Disease Diagnosis via External Planner-Controlled Large Language Models
Apr 04, 2024



The advancement of medical artificial intelligence (AI) has set the stage for the realization of conversational diagnosis, where AI systems mimic human doctors by engaging in dialogue with patients to deduce diagnoses. This study introduces an innovative approach using external planners augmented with large language models (LLMs) to develop a medical task-oriented dialogue system. This system comprises a policy module for information gathering, a LLM based module for natural language understanding and generation, addressing the limitations of previous AI systems in these areas. By emulating the two-phase decision-making process of doctors disease screening and differential diagnosis. we designed two distinct planners. The first focuses on collecting patient symptoms to identify potential diseases, while the second delves into specific inquiries to confirm or exclude these diseases. Utilizing reinforcement learning and active learning with LLMs, we trained these planners to navigate medical dialogues effectively. Our evaluation on the MIMIC-IV dataset demonstrated the system's capability to outperform existing models, indicating a significant step towards achieving automated conversational disease diagnostics and enhancing the precision and accessibility of medical diagnoses.
Causal Interpretable Progression Trajectory Analysis of Chronic Disease
Aug 18, 2023Chronic disease is the leading cause of death, emphasizing the need for accurate prediction of disease progression trajectories and informed clinical decision-making. Machine learning (ML) models have shown promise in this domain by capturing non-linear patterns within patient features. However, existing ML-based models lack the ability to provide causal interpretable predictions and estimate treatment effects, limiting their decision-assisting perspective. In this study, we propose a novel model called causal trajectory prediction (CTP) to tackle the limitation. The CTP model combines trajectory prediction and causal discovery to enable accurate prediction of disease progression trajectories and uncovering causal relationships between features. By incorporating a causal graph into the prediction process, CTP ensures that ancestor features are not influenced by treatment on descendant features, thereby enhancing the interpretability of the model. By estimating the bounds of treatment effects, even in the presence of unmeasured confounders, the CTP provides valuable insights for clinical decision-making. We evaluate the performance of the CTP using simulated and real medical datasets. Experimental results demonstrate that our model achieves satisfactory performance, highlighting its potential to assist clinical decisions.
Replicating Complex Dialogue Policy of Humans via Offline Imitation Learning with Supervised Regularization
May 06, 2023Policy learning (PL) is a module of a task-oriented dialogue system that trains an agent to make actions in each dialogue turn. Imitating human action is a fundamental problem of PL. However, both supervised learning (SL) and reinforcement learning (RL) frameworks cannot imitate humans well. Training RL models require online interactions with user simulators, while simulating complex human policy is hard. Performances of SL-based models are restricted because of the covariate shift problem. Specifically, a dialogue is a sequential decision-making process where slight differences in current utterances and actions will cause significant differences in subsequent utterances. Therefore, the generalize ability of SL models is restricted because statistical characteristics of training and testing dialogue data gradually become different. This study proposed an offline imitation learning model that learns policy from real dialogue datasets and does not require user simulators. It also utilizes state transition information, which alleviates the influence of the covariate shift problem. We introduced a regularization trick to make our model can be effectively optimized. We investigated the performance of our model on four independent public dialogue datasets. The experimental result showed that our model performed better in the action prediction task.
On Tracking Dialogue State by Inheriting Slot Values in Mentioned Slot Pools
Feb 15, 2022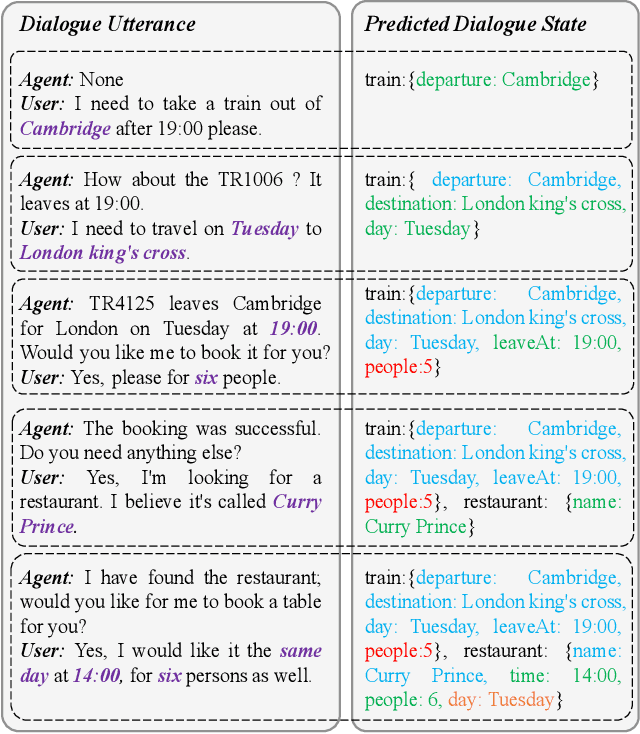
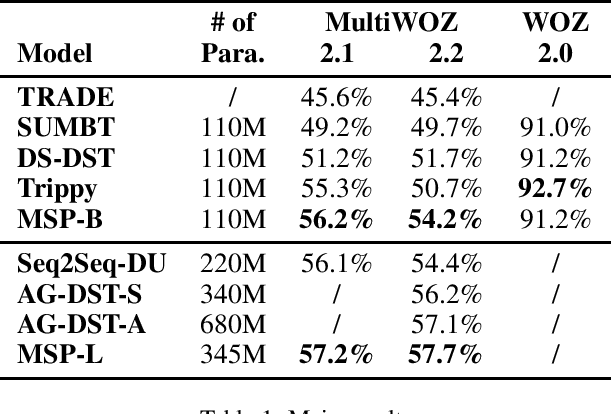
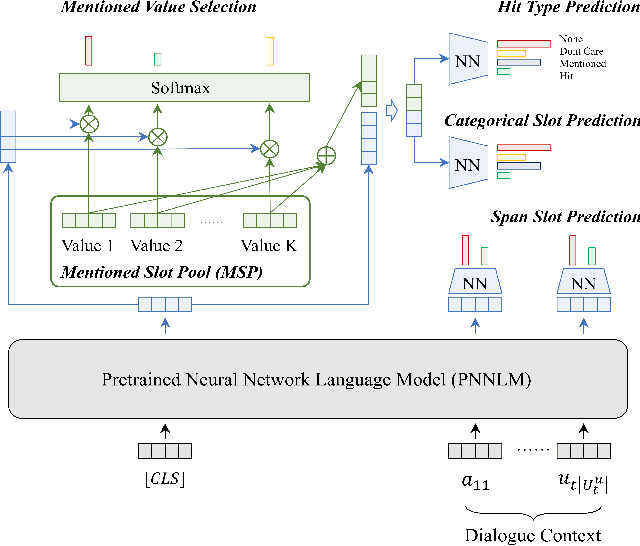
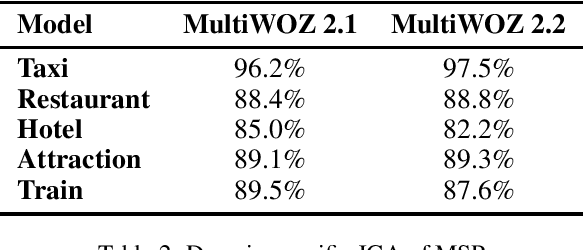
Dialogue state tracking (DST) is a component of the task-oriented dialogue system. It is responsible for extracting and managing slot values according to dialogue utterances, where each slot represents an essential part of the information to accomplish a task, and slot value is updated recurrently in each dialogue turn. However, many DST models cannot update slot values appropriately. These models may repeatedly inherit wrong slot values extracted in previous turns, resulting in the fail of the entire DST task.They cannot update indirectly mentioned slots well, either. This study designed a model with a mentioned slot pool (MSP) to tackle the update problem. The MSP is a slot-specific memory that records all mentioned slot values that may be inherited, and our model updates slot values according to the MSP and the dialogue context. Our model rejects inheriting the previous slot value when it predicates the value is wrong. Then, it re-extracts the slot value from the current dialogue context. As the contextual information accumulates with the dialogue progress, the new value is more likely to be correct. It also can track the indirectly mentioned slot by picking a value from the MSP. Experimental results showed our model reached state-of-the-art DST performance on MultiWOZ 2.1 and 2.2 datasets.
Interpretable Disease Prediction based on Reinforcement Path Reasoning over Knowledge Graphs
Oct 16, 2020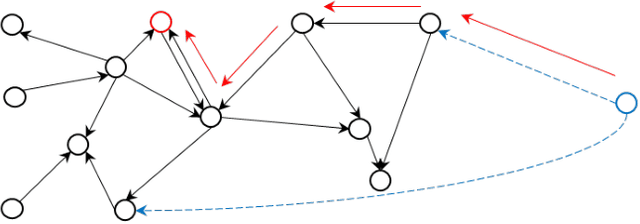
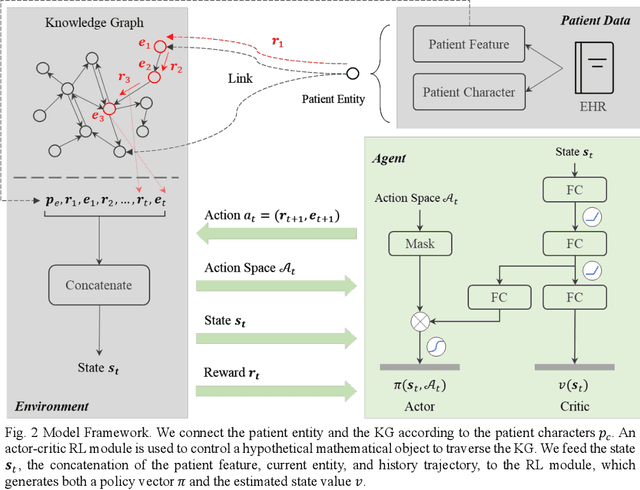
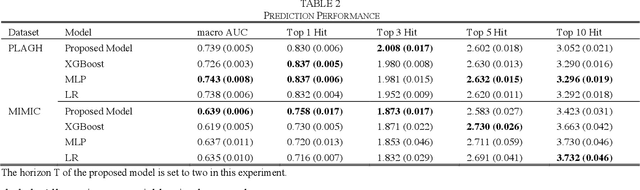
Objective: To combine medical knowledge and medical data to interpretably predict the risk of disease. Methods: We formulated the disease prediction task as a random walk along a knowledge graph (KG). Specifically, we build a KG to record relationships between diseases and risk factors according to validated medical knowledge. Then, a mathematical object walks along the KG. It starts walking at a patient entity, which connects the KG based on the patient current diseases or risk factors and stops at a disease entity, which represents the predicted disease. The trajectory generated by the object represents an interpretable disease progression path of the given patient. The dynamics of the object are controlled by a policy-based reinforcement learning (RL) module, which is trained by electronic health records (EHRs). Experiments: We utilized two real-world EHR datasets to evaluate the performance of our model. In the disease prediction task, our model achieves 0.743 and 0.639 in terms of macro area under the curve (AUC) in predicting 53 circulation system diseases in the two datasets, respectively. This performance is comparable to the commonly used machine learning (ML) models in medical research. In qualitative analysis, our clinical collaborator reviewed the disease progression paths generated by our model and advocated their interpretability and reliability. Conclusion: Experimental results validate the proposed model in interpretably evaluating and optimizing disease prediction. Significance: Our work contributes to leveraging the potential of medical knowledge and medical data jointly for interpretable prediction tasks.