 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Disease Prediction based on Reinforcement Path Reasoning over Knowledge Graphs
Oct 16, 2020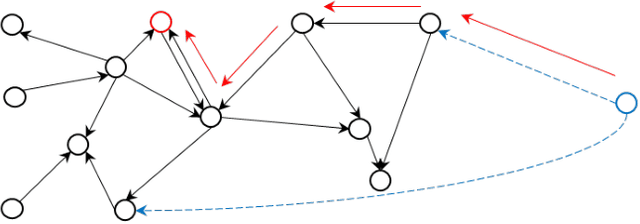
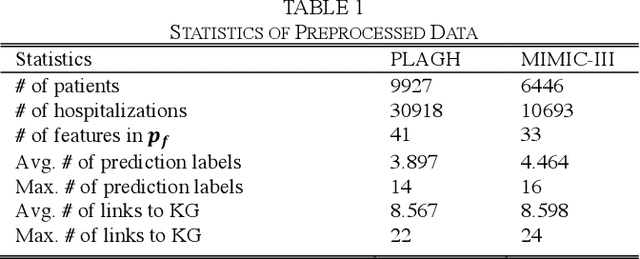
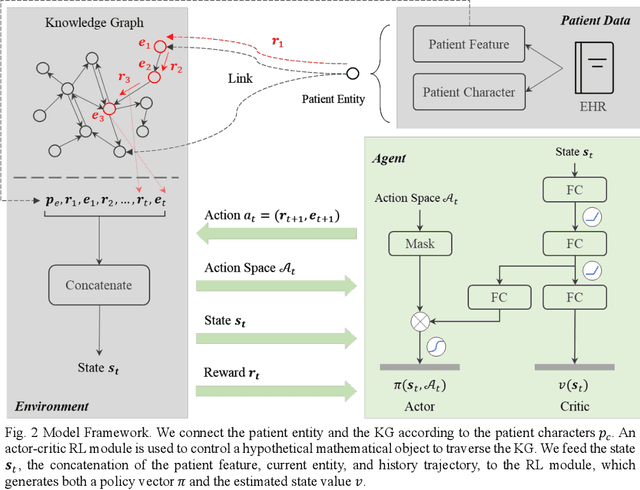
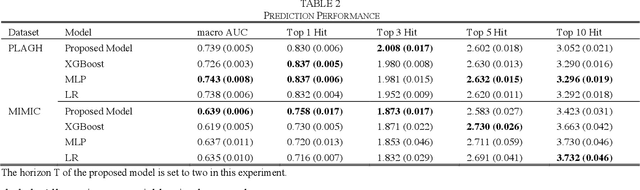
Objective: To combine medical knowledge and medical data to interpretably predict the risk of disease. Methods: We formulated the disease prediction task as a random walk along a knowledge graph (KG). Specifically, we build a KG to record relationships between diseases and risk factors according to validated medical knowledge. Then, a mathematical object walks along the KG. It starts walking at a patient entity, which connects the KG based on the patient current diseases or risk factors and stops at a disease entity, which represents the predicted disease. The trajectory generated by the object represents an interpretable disease progression path of the given patient. The dynamics of the object are controlled by a policy-based reinforcement learning (RL) module, which is trained by electronic health records (EHRs). Experiments: We utilized two real-world EHR datasets to evaluate the performance of our model. In the disease prediction task, our model achieves 0.743 and 0.639 in terms of macro area under the curve (AUC) in predicting 53 circulation system diseases in the two datasets, respectively. This performance is comparable to the commonly used machine learning (ML) models in medical research. In qualitative analysis, our clinical collaborator reviewed the disease progression paths generated by our model and advocated their interpretability and reliability. Conclusion: Experimental results validate the proposed model in interpretably evaluating and optimizing disease prediction. Significance: Our work contributes to leveraging the potential of medical knowledge and medical data jointly for interpretable prediction tasks.
Progressive refinement: a method of coarse-to-fine image parsing using stacked network
Apr 23, 2018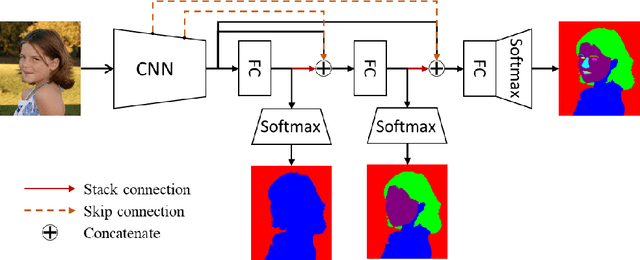


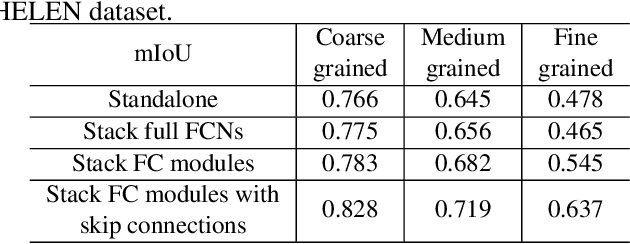
To parse images into fine-grained semantic parts, the complex fine-grained elements will put it in trouble when using off-the-shelf semantic segmentation networks. In this paper, for image parsing task, we propose to parse images from coarse to fine with progressively refined semantic classes. It is achieved by stacking the segmentation layers in a segmentation network several times. The former segmentation module parses images at a coarser-grained level, and the result will be feed to the following one to provide effective contextual clues for the finer-grained parsing. To recover the details of small structures, we add skip connections from shallow layers of the network to fine-grained parsing modules. As for the network training, we merge classes in groundtruth to get coarse-to-fine label maps, and train the stacked network with these hierarchical supervision end-to-end. Our coarse-to-fine stacked framework can be injected into many advanced neural networks to improve the parsing results. Extensive evaluations on several public datasets including face parsing and human parsing well demonstrate the superiority of our method.