 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 Challenge on Single Image Reflection Removal in the Wild: Datasets, Results, and Methods
Apr 11, 2026In this paper, we review the NTIRE 2026 challenge on single-image reflection removal (SIRR) in the Wild. SIRR is a fundamental task in image restoration. Despite progress in academic research, most methods are tested on synthetic images or limited real-world images, creating a gap in real-world applications. In this challenge, we provide participants with the OpenRR-5k dataset, which requires them to process real-world images that cover a range of reflection scenarios and intensities, with the goal of generating clean images without reflections. The challenge attracted more than 100 registrations, with 11 of them participating in the final testing phase. The top-ranked methods advanced the state-of-the-art reflection removal performance and earned unanimous recognition from the five experts in the field. The proposed OpenRR-5k dataset is available at https://huggingface.co/datasets/qiuzhangTiTi/OpenRR-5k, and the homepage of this challenge is at https://github.com/caijie0620/OpenRR-5k. Due to page limitations, this article only presents partial content; the full report and detailed analyses are available in the extended arXiv version.
From Ideal to Real: Stable Video Object Removal under Imperfect Conditions
Mar 10, 2026Removing objects from videos remains difficult in the presence of real-world imperfections such as shadows, abrupt motion, and defective masks. Existing diffusion-based video inpainting models often struggle to maintain temporal stability and visual consistency under these challenges. We propose Stable Video Object Removal (SVOR), a robust framework that achieves shadow-free, flicker-free, and mask-defect-tolerant removal through three key designs: (1) Mask Union for Stable Erasure (MUSE), a windowed union strategy applied during temporal mask downsampling to preserve all target regions observed within each window, effectively handling abrupt motion and reducing missed removals; (2) Denoising-Aware Segmentation (DA-Seg), a lightweight segmentation head on a decoupled side branch equipped with Denoising-Aware AdaLN and trained with mask degradation to provide an internal diffusion-aware localization prior without affecting content generation; and (3) Curriculum Two-Stage Training: where Stage I performs self-supervised pretraining on unpaired real-background videos with online random masks to learn realistic background and temporal priors, and Stage II refines on synthetic pairs using mask degradation and side-effect-weighted losses, jointly removing objects and their associated shadows/reflections while improving cross-domain robustness. Extensive experiments show that SVOR attains new state-of-the-art results across multiple datasets and degraded-mask benchmarks, advancing video object removal from ideal settings toward real-world applications.
Controllable Pedestrian Video Editing for Multi-View Driving Scenarios via Motion Sequence
Aug 01, 2025



Pedestrian detection models in autonomous driving systems often lack robustness due to insufficient representation of dangerous pedestrian scenarios in training datasets. To address this limitation, we present a novel framework for controllable pedestrian video editing in multi-view driving scenarios by integrating video inpainting and human motion control techniques. Our approach begins by identifying pedestrian regions of interest across multiple camera views, expanding detection bounding boxes with a fixed ratio, and resizing and stitching these regions into a unified canvas while preserving cross-view spatial relationships. A binary mask is then applied to designate the editable area, within which pedestrian editing is guided by pose sequence control conditions. This enables flexible editing functionalities, including pedestrian insertion, replacement, and removal. Extensive experiments demonstrate that our framework achieves high-quality pedestrian editing with strong visual realism, spatiotemporal coherence, and cross-view consistency. These results establish the proposed method as a robust and versatile solution for multi-view pedestrian video generation, with broad potential for applications in data augmentation and scenario simulation in autonomous driving.
Not All Pixels Are Equal: Learning Pixel Hardness for Semantic Segmentation
May 15, 2023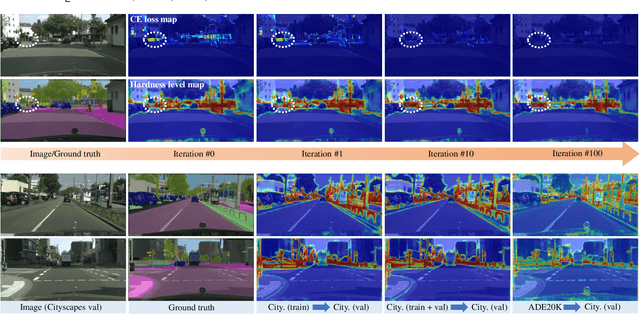
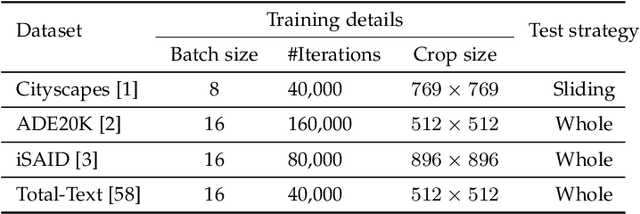
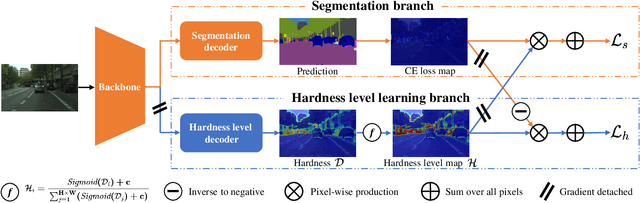
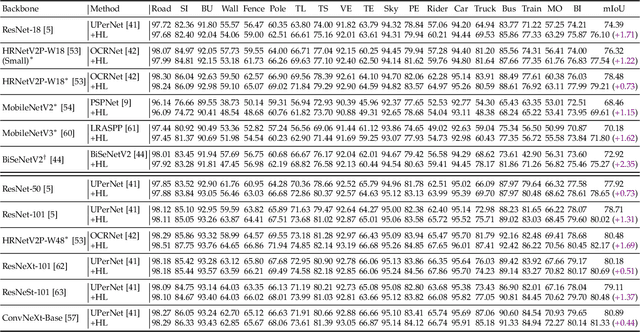
Semantic segmentation has recently witnessed great progress. Despite the impressive overall results, the segmentation performance in some hard areas (e.g., small objects or thin parts) is still not promising. A straightforward solution is hard sample mining, which is widely used in object detection. Yet, most existing hard pixel mining strategies for semantic segmentation often rely on pixel's loss value, which tends to decrease during training. Intuitively, the pixel hardness for segmentation mainly depends on image structure and is expected to be stable. In this paper, we propose to learn pixel hardness for semantic segmentation, leveraging hardness information contained in global and historical loss values. More precisely, we add a gradient-independent branch for learning a hardness level (HL) map by maximizing hardness-weighted segmentation loss, which is minimized for the segmentation head. This encourages large hardness values in difficult areas, leading to appropriate and stable HL map. Despite its simplicity, the proposed method can be applied to most segmentation methods with no and marginal extra cost during inference and training, respectively. Without bells and whistles, the proposed method achieves consistent/significant improvement (1.37% mIoU on average) over most popular semantic segmentation methods on Cityscapes dataset, and demonstrates good generalization ability across domains. The source codes are available at https://github.com/Menoly-xin/Hardness-Level-Learning .
Progressive refinement: a method of coarse-to-fine image parsing using stacked network
Apr 23, 2018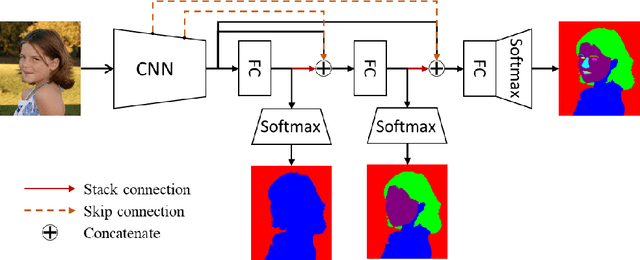


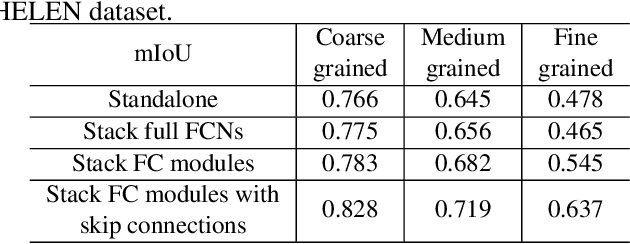
To parse images into fine-grained semantic parts, the complex fine-grained elements will put it in trouble when using off-the-shelf semantic segmentation networks. In this paper, for image parsing task, we propose to parse images from coarse to fine with progressively refined semantic classes. It is achieved by stacking the segmentation layers in a segmentation network several times. The former segmentation module parses images at a coarser-grained level, and the result will be feed to the following one to provide effective contextual clues for the finer-grained parsing. To recover the details of small structures, we add skip connections from shallow layers of the network to fine-grained parsing modules. As for the network training, we merge classes in groundtruth to get coarse-to-fine label maps, and train the stacked network with these hierarchical supervision end-to-end. Our coarse-to-fine stacked framework can be injected into many advanced neural networks to improve the parsing results. Extensive evaluations on several public datasets including face parsing and human parsing well demonstrate the superiority of our method.