 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Models Hear Like Us? Probing the Representational Alignment of Audio LLMs and Naturalistic EEG
Jan 23, 2026Audio Large Language Models (Audio LLMs) have demonstrated strong capabilities in integrating speech perception with language understanding. However, whether their internal representations align with human neural dynamics during naturalistic listening remains largely unexplored. In this work, we systematically examine layer-wise representational alignment between 12 open-source Audio LLMs and Electroencephalogram (EEG) signals across 2 datasets. Specifically, we employ 8 similarity metrics, such as Spearman-based Representational Similarity Analysis (RSA), to characterize within-sentence representational geometry. Our analysis reveals 3 key findings: (1) we observe a rank-dependence split, in which model rankings vary substantially across different similarity metrics; (2) we identify spatio-temporal alignment patterns characterized by depth-dependent alignment peaks and a pronounced increase in RSA within the 250-500 ms time window, consistent with N400-related neural dynamics; (3) we find an affective dissociation whereby negative prosody, identified using a proposed Tri-modal Neighborhood Consistency (TNC) criterion, reduces geometric similarity while enhancing covariance-based dependence. These findings provide new neurobiological insights into the representational mechanisms of Audio LLMs.
World to Code: Multi-modal Data Generation via Self-Instructed Compositional Captioning and Filtering
Sep 30, 2024



Recent advances in Vision-Language Models (VLMs) and the scarcity of high-quality multi-modal alignment data have inspired numerous researches on synthetic VLM data generation. The conventional norm in VLM data construction uses a mixture of specialists in caption and OCR, or stronger VLM APIs and expensive human annotation. In this paper, we present World to Code (W2C), a meticulously curated multi-modal data construction pipeline that organizes the final generation output into a Python code format. The pipeline leverages the VLM itself to extract cross-modal information via different prompts and filter the generated outputs again via a consistency filtering strategy. Experiments have demonstrated the high quality of W2C by improving various existing visual question answering and visual grounding benchmarks across different VLMs. Further analysis also demonstrates that the new code parsing ability of VLMs presents better cross-modal equivalence than the commonly used detail caption ability. Our code is available at https://github.com/foundation-multimodal-models/World2Code.
Seeing the Image: Prioritizing Visual Correlation by Contrastive Alignment
May 28, 2024



Existing image-text modality alignment in Vision Language Models (VLMs) treats each text token equally in an autoregressive manner. Despite being simple and effective, this method results in sub-optimal cross-modal alignment by over-emphasizing the text tokens that are less correlated with or even contradictory with the input images. In this paper, we advocate for assigning distinct contributions for each text token based on its visual correlation. Specifically, we present by contrasting image inputs, the difference in prediction logits on each text token provides strong guidance of visual correlation. We therefore introduce Contrastive ALignment (CAL), a simple yet effective re-weighting strategy that prioritizes training visually correlated tokens. Our experimental results demonstrate that CAL consistently improves different types of VLMs across different resolutions and model sizes on various benchmark datasets. Importantly, our method incurs minimal additional computational overhead, rendering it highly efficient compared to alternative data scaling strategies. Codes are available at https://github.com/foundation-multimodal-models/CAL.
Noised Autoencoders for Point Annotation Restoration in Object Counting
Dec 12, 2023Object counting is a field of growing importance in domains such as security surveillance, urban planning, and biology. The annotation is usually provided in terms of 2D points. However, the complexity of object shapes and subjective of annotators may lead to annotation inconsistency, potentially confusing the model during training. To alleviate this issue, we introduce the Noised Autoencoders (NAE) methodology, which extracts general positional knowledge from all annotations. The method involves adding random offsets to initial point annotations, followed by a UNet to restore them to their original positions. Similar to MAE, NAE faces challenges in restoring non-generic points, necessitating reliance on the most common positions inferred from general knowledge. This reliance forms the cornerstone of our method's effectiveness. Different from existing noise-resistance methods, our approach focus on directly improving initial point annotations. Extensive experiments show that NAE yields more consistent annotations compared to the original ones, steadily enhancing the performance of advanced models trained with these revised annotations. \textbf{Remarkably, the proposed approach helps to set new records in nine datasets}. We will make the NAE codes and refined point annotations available.
Dual Structure-Preserving Image Filterings for Semi-supervised Medical Image Segmentation
Dec 12, 2023Semi-supervised image segmentation has attracted great attention recently. The key is how to leverage unlabeled images in the training process. Most methods maintain consistent predictions of the unlabeled images under variations (e.g., adding noise/perturbations, or creating alternative versions) in the image and/or model level. In most image-level variation, medical images often have prior structure information, which has not been well explored. In this paper, we propose novel dual structure-preserving image filterings (DSPIF) as the image-level variations for semi-supervised medical image segmentation. Motivated by connected filtering that simplifies image via filtering in structure-aware tree-based image representation, we resort to the dual contrast invariant Max-tree and Min-tree representation. Specifically, we propose a novel connected filtering that removes topologically equivalent nodes (i.e. connected components) having no siblings in the Max/Min-tree. This results in two filtered images preserving topologically critical structure. Applying such dual structure-preserving image filterings in mutual supervision is beneficial for semi-supervised medical image segmentation. Extensive experimental results on three benchmark datasets demonstrate that the proposed method significantly/consistently outperforms some state-of-the-art methods. The source codes will be publicly available.
Generalization Bounds for Neural Belief Propagation Decoders
May 17, 2023



Machine learning based approaches are being increasingly used for designing decoders for next generation communication systems. One widely used framework is neural belief propagation (NBP), which unfolds the belief propagation (BP) iterations into a deep neural network and the parameters are trained in a data-driven manner. NBP decoders have been shown to improve upon classical decoding algorithms. In this paper, we investigate the generalization capabilities of NBP decoders. Specifically, the generalization gap of a decoder is the difference between empirical and expected bit-error-rate(s). We present new theoretical results which bound this gap and show the dependence on the decoder complexity, in terms of code parameters (blocklength, message length, variable/check node degrees), decoding iterations, and the training dataset size. Results are presented for both regular and irregular parity-check matrices. To the best of our knowledge, this is the first set of theoretical results on generalization performance of neural network based decoders. We present experimental results to show the dependence of generalization gap on the training dataset size, and decoding iterations for different codes.
Not All Pixels Are Equal: Learning Pixel Hardness for Semantic Segmentation
May 15, 2023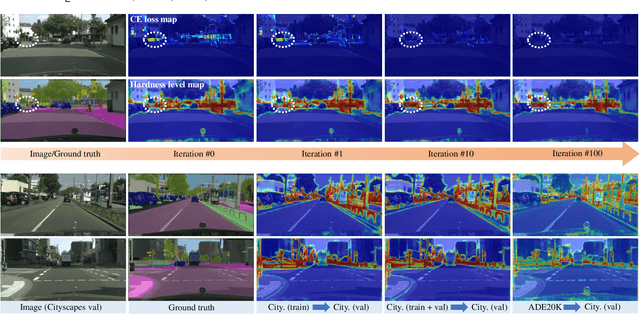
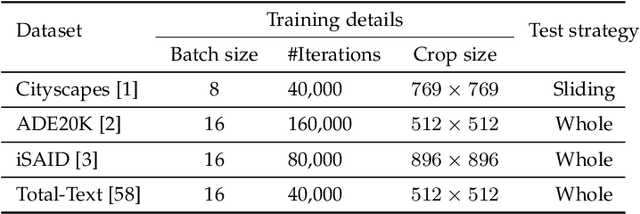
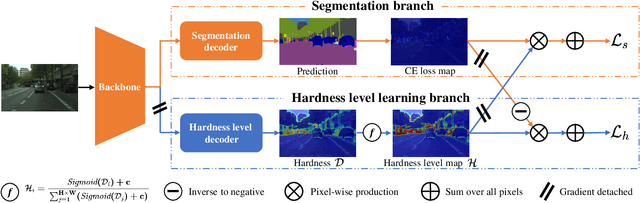
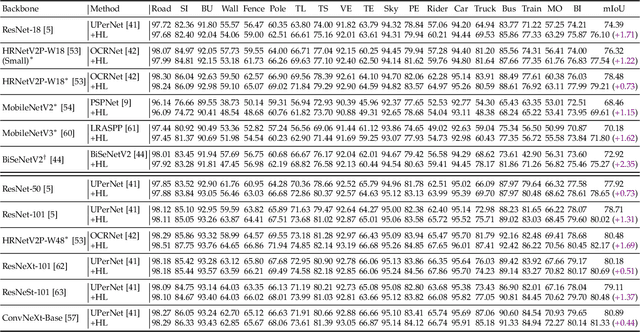
Semantic segmentation has recently witnessed great progress. Despite the impressive overall results, the segmentation performance in some hard areas (e.g., small objects or thin parts) is still not promising. A straightforward solution is hard sample mining, which is widely used in object detection. Yet, most existing hard pixel mining strategies for semantic segmentation often rely on pixel's loss value, which tends to decrease during training. Intuitively, the pixel hardness for segmentation mainly depends on image structure and is expected to be stable. In this paper, we propose to learn pixel hardness for semantic segmentation, leveraging hardness information contained in global and historical loss values. More precisely, we add a gradient-independent branch for learning a hardness level (HL) map by maximizing hardness-weighted segmentation loss, which is minimized for the segmentation head. This encourages large hardness values in difficult areas, leading to appropriate and stable HL map. Despite its simplicity, the proposed method can be applied to most segmentation methods with no and marginal extra cost during inference and training, respectively. Without bells and whistles, the proposed method achieves consistent/significant improvement (1.37% mIoU on average) over most popular semantic segmentation methods on Cityscapes dataset, and demonstrates good generalization ability across domains. The source codes are available at https://github.com/Menoly-xin/Hardness-Level-Learning .
FAID Diversity via Neural Networks
May 10, 2021

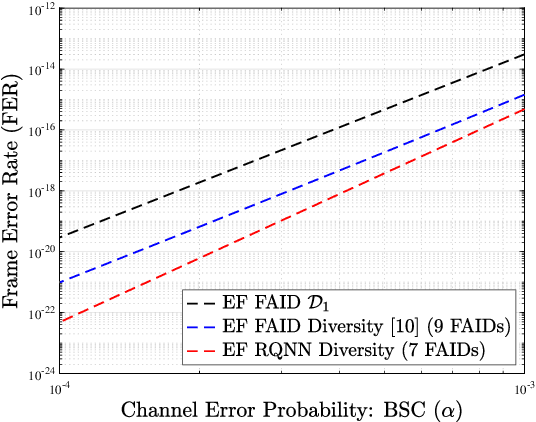
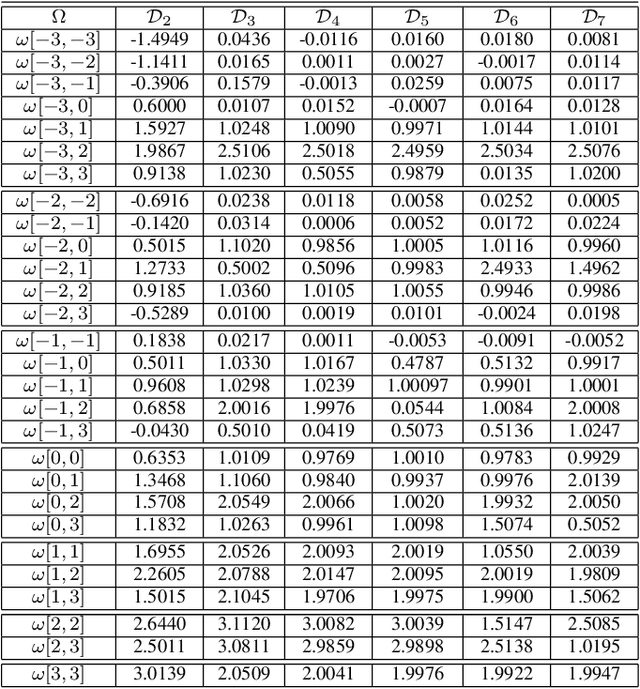
Decoder diversity is a powerful error correction framework in which a collection of decoders collaboratively correct a set of error patterns otherwise uncorrectable by any individual decoder. In this paper, we propose a new approach to design the decoder diversity of finite alphabet iterative decoders (FAIDs) for Low-Density Parity Check (LDPC) codes over the binary symmetric channel (BSC), for the purpose of lowering the error floor while guaranteeing the waterfall performance. The proposed decoder diversity is achieved by training a recurrent quantized neural network (RQNN) to learn/design FAIDs. We demonstrated for the first time that a machine-learned decoder can surpass in performance a man-made decoder of the same complexity. As RQNNs can model a broad class of FAIDs, they are capable of learning an arbitrary FAID. To provide sufficient knowledge of the error floor to the RQNN, the training sets are constructed by sampling from the set of most problematic error patterns - trapping sets. In contrast to the existing methods that use the cross-entropy function as the loss function, we introduce a frame-error-rate (FER) based loss function to train the RQNN with the objective of correcting specific error patterns rather than reducing the bit error rate (BER). The examples and simulation results show that the RQNN-aided decoder diversity increases the error correction capability of LDPC codes and lowers the error floor.
On the Sensitivity of Shape Fitting Problems
Oct 10, 2012In this article, we study shape fitting problems, $\epsilon$-coresets, and total sensitivity. We focus on the $(j,k)$-projective clustering problems, including $k$-median/$k$-means, $k$-line clustering, $j$-subspace approximation, and the integer $(j,k)$-projective clustering problem. We derive upper bounds of total sensitivities for these problems, and obtain $\epsilon$-coresets using these upper bounds. Using a dimension-reduction type argument, we are able to greatly simplify earlier results on total sensitivity for the $k$-median/$k$-means clustering problems, and obtain positively-weighted $\epsilon$-coresets for several variants of the $(j,k)$-projective clustering problem. We also extend an earlier result on $\epsilon$-coresets for the integer $(j,k)$-projective clustering problem in fixed dimension to the case of high dimension.