 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistent-Point: Consistent Pseudo-Points for Semi-Supervised Crowd Counting and Localization
Mar 16, 2025
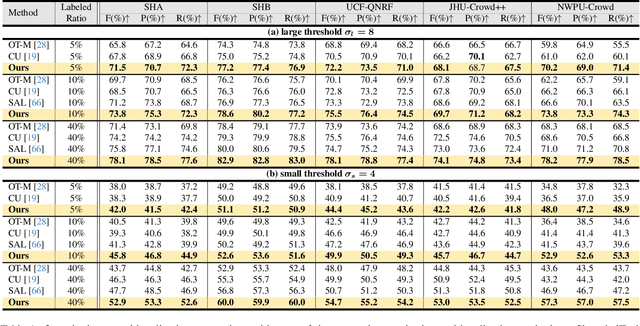
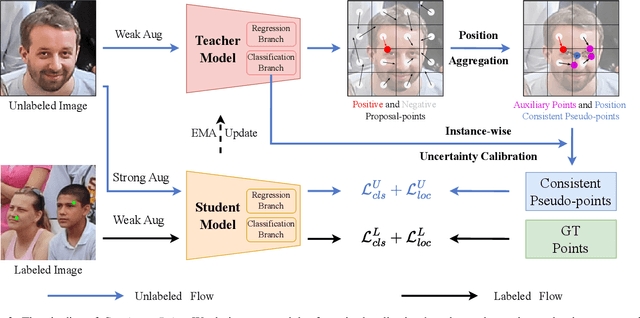
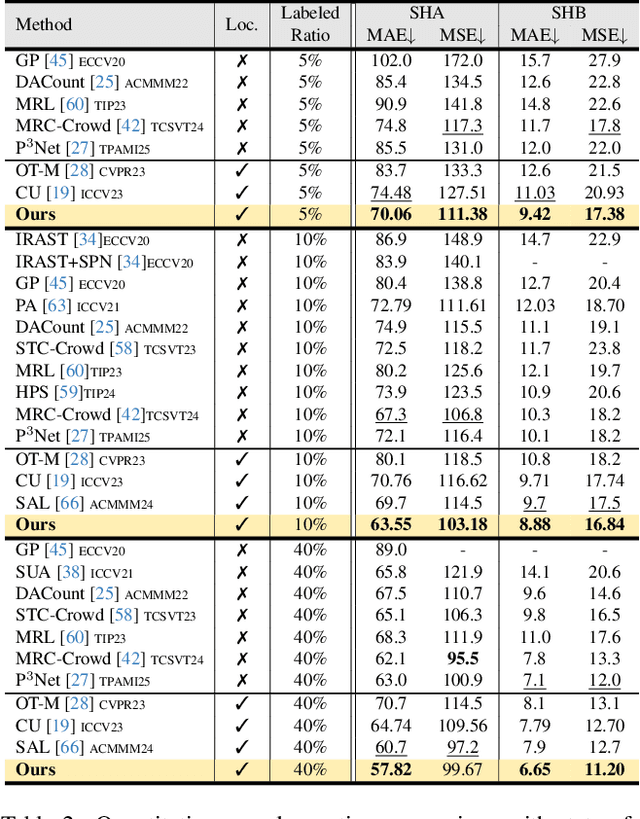
Crowd counting and localization are important in applications such as public security and traffic management. Existing methods have achieved impressive results thanks to extensive laborious annotations. This paper propose a novel point-localization-based semi-supervised crowd counting and localization method termed Consistent-Point. We identify and address two inconsistencies of pseudo-points, which have not been adequately explored. To enhance their position consistency, we aggregate the positions of neighboring auxiliary proposal-points. Additionally, an instance-wise uncertainty calibration is proposed to improve the class consistency of pseudo-points. By generating more consistent pseudo-points, Consistent-Point provides more stable supervision to the training process, yielding improved results. Extensive experiments across five widely used datasets and three different labeled ratio settings demonstrate that our method achieves state-of-the-art performance in crowd localization while also attaining impressive crowd counting results. The code will be available.
Spatial-aware Attention Generative Adversarial Network for Semi-supervised Anomaly Detection in Medical Image
May 21, 2024


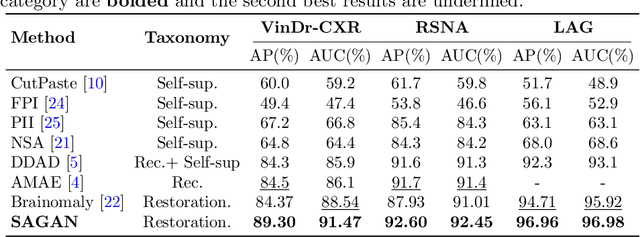
Medical anomaly detection is a critical research area aimed at recognizing abnormal images to aid in diagnosis.Most existing methods adopt synthetic anomalies and image restoration on normal samples to detect anomaly. The unlabeled data consisting of both normal and abnormal data is not well explored. We introduce a novel Spatial-aware Attention Generative Adversarial Network (SAGAN) for one-class semi-supervised generation of health images.Our core insight is the utilization of position encoding and attention to accurately focus on restoring abnormal regions and preserving normal regions. To fully utilize the unlabelled data, SAGAN relaxes the cyclic consistency requirement of the existing unpaired image-to-image conversion methods, and generates high-quality health images corresponding to unlabeled data, guided by the reconstruction of normal images and restoration of pseudo-anomaly images.Subsequently, the discrepancy between the generated healthy image and the original image is utilized as an anomaly score.Extensive experiments on three medical datasets demonstrate that the proposed SAGAN outperforms the state-of-the-art methods.
MRAnnotator: A Multi-Anatomy Deep Learning Model for MRI Segmentation
Feb 01, 2024



Purpose To develop a deep learning model for multi-anatomy and many-class segmentation of diverse anatomic structures on MRI imaging. Materials and Methods In this retrospective study, two datasets were curated and annotated for model development and evaluation. An internal dataset of 1022 MRI sequences from various clinical sites within a health system and an external dataset of 264 MRI sequences from an independent imaging center were collected. In both datasets, 49 anatomic structures were annotated as the ground truth. The internal dataset was divided into training, validation, and test sets and used to train and evaluate an nnU-Net model. The external dataset was used to evaluate nnU-Net model generalizability and performance in all classes on independent imaging data. Dice scores were calculated to evaluate model segmentation performance. Results The model achieved an average Dice score of 0.801 on the internal test set, and an average score of 0.814 on the complete external dataset across 49 classes. Conclusion The developed model achieves robust and generalizable segmentation of 49 anatomic structures on MRI imaging. A future direction is focused on the incorporation of additional anatomic regions and structures into the datasets and model.
VISION-MAE: A Foundation Model for Medical Image Segmentation and Classification
Feb 01, 2024Artificial Intelligence (AI) has the potential to revolutionize diagnosis and segmentation in medical imaging. However, development and clinical implementation face multiple challenges including limited data availability, lack of generalizability, and the necessity to incorporate multi-modal data effectively. A foundation model, which is a large-scale pre-trained AI model, offers a versatile base that can be adapted to a variety of specific tasks and contexts. Here, we present a novel foundation model, VISION-MAE, specifically designed for medical imaging. Specifically, VISION-MAE is trained on a dataset of 2.5 million unlabeled images from various modalities (CT, MR, PET, X-rays, and ultrasound), using self-supervised learning techniques. It is then adapted to classification and segmentation tasks using explicit labels. VISION-MAE has high label efficiency, outperforming several benchmark models in both in-domain and out-of-domain applications, and achieves high performance even with reduced availability of labeled data. This model represents a significant advancement in medical imaging AI, offering a generalizable and robust solution for improving segmentation and classification tasks while reducing the data annotation workload.
Dual Structure-Preserving Image Filterings for Semi-supervised Medical Image Segmentation
Dec 12, 2023Semi-supervised image segmentation has attracted great attention recently. The key is how to leverage unlabeled images in the training process. Most methods maintain consistent predictions of the unlabeled images under variations (e.g., adding noise/perturbations, or creating alternative versions) in the image and/or model level. In most image-level variation, medical images often have prior structure information, which has not been well explored. In this paper, we propose novel dual structure-preserving image filterings (DSPIF) as the image-level variations for semi-supervised medical image segmentation. Motivated by connected filtering that simplifies image via filtering in structure-aware tree-based image representation, we resort to the dual contrast invariant Max-tree and Min-tree representation. Specifically, we propose a novel connected filtering that removes topologically equivalent nodes (i.e. connected components) having no siblings in the Max/Min-tree. This results in two filtered images preserving topologically critical structure. Applying such dual structure-preserving image filterings in mutual supervision is beneficial for semi-supervised medical image segmentation. Extensive experimental results on three benchmark datasets demonstrate that the proposed method significantly/consistently outperforms some state-of-the-art methods. The source codes will be publicly available.
RadImageGAN -- A Multi-modal Dataset-Scale Generative AI for Medical Imaging
Dec 10, 2023



Deep learning in medical imaging often requires large-scale, high-quality data or initiation with suitably pre-trained weights. However, medical datasets are limited by data availability, domain-specific knowledge, and privacy concerns, and the creation of large and diverse radiologic databases like RadImageNet is highly resource-intensive. To address these limitations, we introduce RadImageGAN, the first multi-modal radiologic data generator, which was developed by training StyleGAN-XL on the real RadImageNet dataset of 102,774 patients. RadImageGAN can generate high-resolution synthetic medical imaging datasets across 12 anatomical regions and 130 pathological classes in 3 modalities. Furthermore, we demonstrate that RadImageGAN generators can be utilized with BigDatasetGAN to generate multi-class pixel-wise annotated paired synthetic images and masks for diverse downstream segmentation tasks with minimal manual annotation. We showed that using synthetic auto-labeled data from RadImageGAN can significantly improve performance on four diverse downstream segmentation datasets by augmenting real training data and/or developing pre-trained weights for fine-tuning. This shows that RadImageGAN combined with BigDatasetGAN can improve model performance and address data scarcity while reducing the resources needed for annotations for segmentation tasks.
Generative AI for Medical Imaging: extending the MONAI Framework
Jul 27, 2023Recent advances in generative AI have brought incredible breakthroughs in several areas, including medical imaging. These generative models have tremendous potential not only to help safely share medical data via synthetic datasets but also to perform an array of diverse applications, such as anomaly detection, image-to-image translation, denoising, and MRI reconstruction. However, due to the complexity of these models, their implementation and reproducibility can be difficult. This complexity can hinder progress, act as a use barrier, and dissuade the comparison of new methods with existing works. In this study, we present MONAI Generative Models, a freely available open-source platform that allows researchers and developers to easily train, evaluate, and deploy generative models and related applications. Our platform reproduces state-of-art studies in a standardised way involving different architectures (such as diffusion models, autoregressive transformers, and GANs), and provides pre-trained models for the community. We have implemented these models in a generalisable fashion, illustrating that their results can be extended to 2D or 3D scenarios, including medical images with different modalities (like CT, MRI, and X-Ray data) and from different anatomical areas. Finally, we adopt a modular and extensible approach, ensuring long-term maintainability and the extension of current applications for future features.
Label Mask for Multi-Label Text Classification
Jun 18, 2021
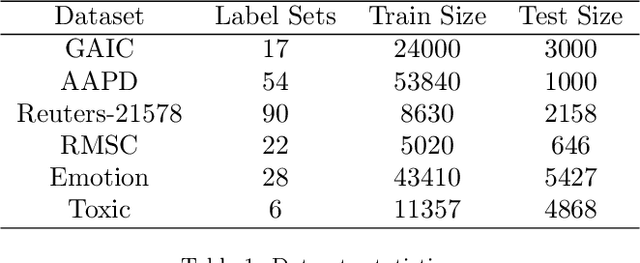
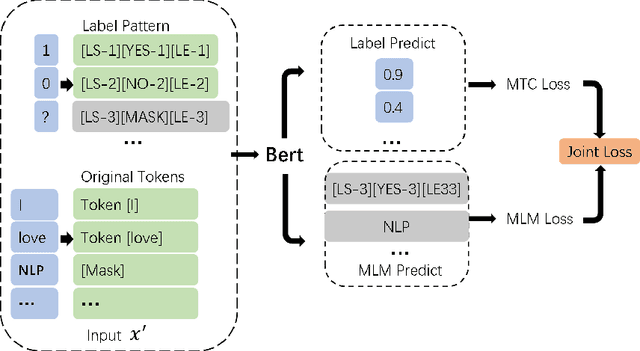
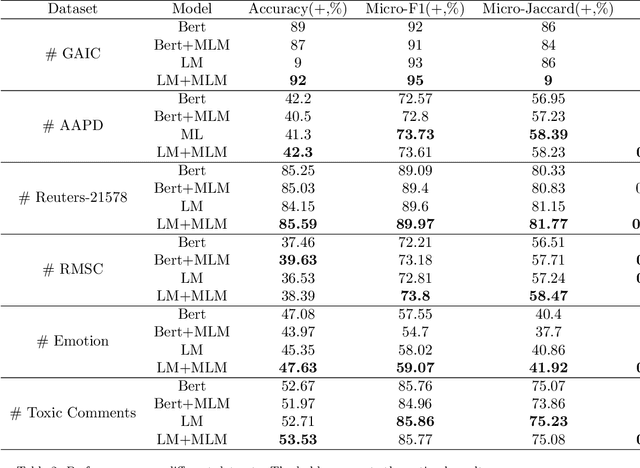
One of the key problems in multi-label text classification is how to take advantage of the correlation among labels. However, it is very challenging to directly model the correlations among labels in a complex and unknown label space. In this paper, we propose a Label Mask multi-label text classification model (LM-MTC), which is inspired by the idea of cloze questions of language model. LM-MTC is able to capture implicit relationships among labels through the powerful ability of pre-train language models. On the basis, we assign a different token to each potential label, and randomly mask the token with a certain probability to build a label based Masked Language Model (MLM). We train the MTC and MLM together, further improving the generalization ability of the model. A large number of experiments on multiple datasets demonstrate the effectiveness of our method.