 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Graph Neural Networks on Graph-level Tasks: Comprehensive Experiments, Analysis, and Improvements
Jan 01, 2025Graphs are essential data structures for modeling complex interactions in domains such as social networks, molecular structures, and biological systems. Graph-level tasks, which predict properties or classes for the entire graph, are critical for applications, such as molecular property prediction and subgraph counting. Graph Neural Networks (GNNs) have shown promise in these tasks, but their evaluations are often limited to narrow datasets, tasks, and inconsistent experimental setups, restricting their generalizability. To address these limitations, we propose a unified evaluation framework for graph-level GNNs. This framework provides a standardized setting to evaluate GNNs across diverse datasets, various graph tasks (e.g., graph classification and regression), and challenging scenarios, including noisy, imbalanced, and few-shot graphs. Additionally, we propose a novel GNN model with enhanced expressivity and generalization capabilities. Specifically, we enhance the expressivity of GNNs through a $k$-path rooted subgraph approach, enabling the model to effectively count subgraphs (e.g., paths and cycles). Moreover, we introduce a unified graph contrastive learning algorithm for graphs across diverse domains, which adaptively removes unimportant edges to augment graphs, thereby significantly improving generalization performance. Extensive experiments demonstrate that our model achieves superior performance against fourteen effective baselines across twenty-seven graph datasets, establishing it as a robust and generalizable model for graph-level tasks.
Epidemiology-informed Graph Neural Network for Heterogeneity-aware Epidemic Forecasting
Nov 26, 2024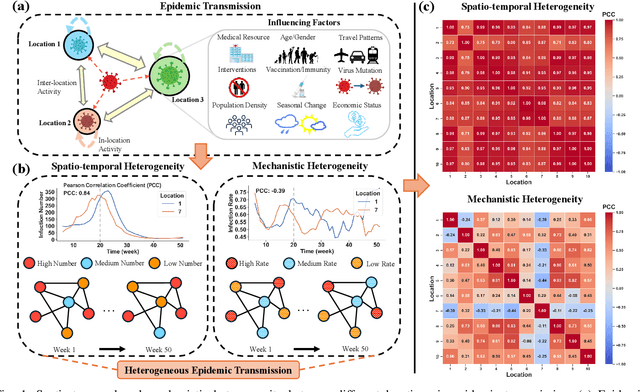
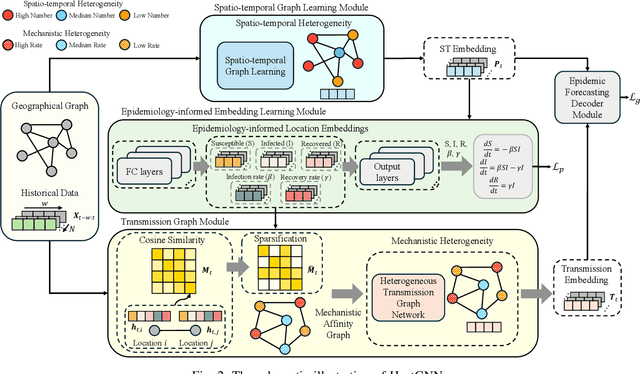
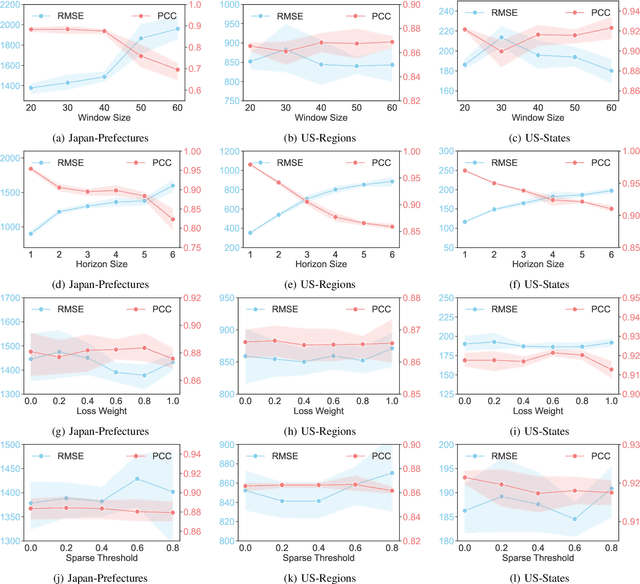
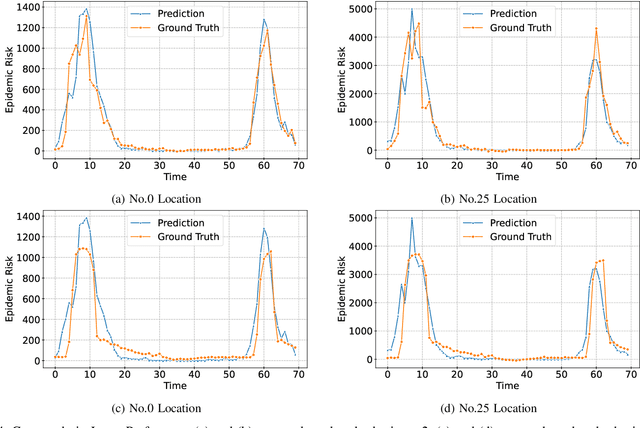
Among various spatio-temporal prediction tasks, epidemic forecasting plays a critical role in public health management. Recent studies have demonstrated the strong potential of spatio-temporal graph neural networks (STGNNs) in extracting heterogeneous spatio-temporal patterns for epidemic forecasting. However, most of these methods bear an over-simplified assumption that two locations (e.g., cities) with similar observed features in previous time steps will develop similar infection numbers in the future. In fact, for any epidemic disease, there exists strong heterogeneity of its intrinsic evolution mechanisms across geolocation and time, which can eventually lead to diverged infection numbers in two ``similar'' locations. However, such mechanistic heterogeneity is non-trivial to be captured due to the existence of numerous influencing factors like medical resource accessibility, virus mutations, mobility patterns, etc., most of which are spatio-temporal yet unreachable or even unobservable. To address this challenge, we propose a Heterogeneous Epidemic-Aware Transmission Graph Neural Network (HeatGNN), a novel epidemic forecasting framework. By binding the epidemiology mechanistic model into a GNN, HeatGNN learns epidemiology-informed location embeddings of different locations that reflect their own transmission mechanisms over time. With the time-varying mechanistic affinity graphs computed with the epidemiology-informed location embeddings, a heterogeneous transmission graph network is designed to encode the mechanistic heterogeneity among locations, providing additional predictive signals to facilitate accurate forecasting. Experiments on three benchmark datasets have revealed that HeatGNN outperforms various strong baselines. Moreover, our efficiency analysis verifies the real-world practicality of HeatGNN on datasets of different sizes.
MRAnnotator: A Multi-Anatomy Deep Learning Model for MRI Segmentation
Feb 01, 2024



Purpose To develop a deep learning model for multi-anatomy and many-class segmentation of diverse anatomic structures on MRI imaging. Materials and Methods In this retrospective study, two datasets were curated and annotated for model development and evaluation. An internal dataset of 1022 MRI sequences from various clinical sites within a health system and an external dataset of 264 MRI sequences from an independent imaging center were collected. In both datasets, 49 anatomic structures were annotated as the ground truth. The internal dataset was divided into training, validation, and test sets and used to train and evaluate an nnU-Net model. The external dataset was used to evaluate nnU-Net model generalizability and performance in all classes on independent imaging data. Dice scores were calculated to evaluate model segmentation performance. Results The model achieved an average Dice score of 0.801 on the internal test set, and an average score of 0.814 on the complete external dataset across 49 classes. Conclusion The developed model achieves robust and generalizable segmentation of 49 anatomic structures on MRI imaging. A future direction is focused on the incorporation of additional anatomic regions and structures into the datasets and model.
VISION-MAE: A Foundation Model for Medical Image Segmentation and Classification
Feb 01, 2024Artificial Intelligence (AI) has the potential to revolutionize diagnosis and segmentation in medical imaging. However, development and clinical implementation face multiple challenges including limited data availability, lack of generalizability, and the necessity to incorporate multi-modal data effectively. A foundation model, which is a large-scale pre-trained AI model, offers a versatile base that can be adapted to a variety of specific tasks and contexts. Here, we present a novel foundation model, VISION-MAE, specifically designed for medical imaging. Specifically, VISION-MAE is trained on a dataset of 2.5 million unlabeled images from various modalities (CT, MR, PET, X-rays, and ultrasound), using self-supervised learning techniques. It is then adapted to classification and segmentation tasks using explicit labels. VISION-MAE has high label efficiency, outperforming several benchmark models in both in-domain and out-of-domain applications, and achieves high performance even with reduced availability of labeled data. This model represents a significant advancement in medical imaging AI, offering a generalizable and robust solution for improving segmentation and classification tasks while reducing the data annotation workload.
RadImageGAN -- A Multi-modal Dataset-Scale Generative AI for Medical Imaging
Dec 10, 2023



Deep learning in medical imaging often requires large-scale, high-quality data or initiation with suitably pre-trained weights. However, medical datasets are limited by data availability, domain-specific knowledge, and privacy concerns, and the creation of large and diverse radiologic databases like RadImageNet is highly resource-intensive. To address these limitations, we introduce RadImageGAN, the first multi-modal radiologic data generator, which was developed by training StyleGAN-XL on the real RadImageNet dataset of 102,774 patients. RadImageGAN can generate high-resolution synthetic medical imaging datasets across 12 anatomical regions and 130 pathological classes in 3 modalities. Furthermore, we demonstrate that RadImageGAN generators can be utilized with BigDatasetGAN to generate multi-class pixel-wise annotated paired synthetic images and masks for diverse downstream segmentation tasks with minimal manual annotation. We showed that using synthetic auto-labeled data from RadImageGAN can significantly improve performance on four diverse downstream segmentation datasets by augmenting real training data and/or developing pre-trained weights for fine-tuning. This shows that RadImageGAN combined with BigDatasetGAN can improve model performance and address data scarcity while reducing the resources needed for annotations for segmentation tasks.
ReFRS: Resource-efficient Federated Recommender System for Dynamic and Diversified User Preferences
Jul 28, 2022
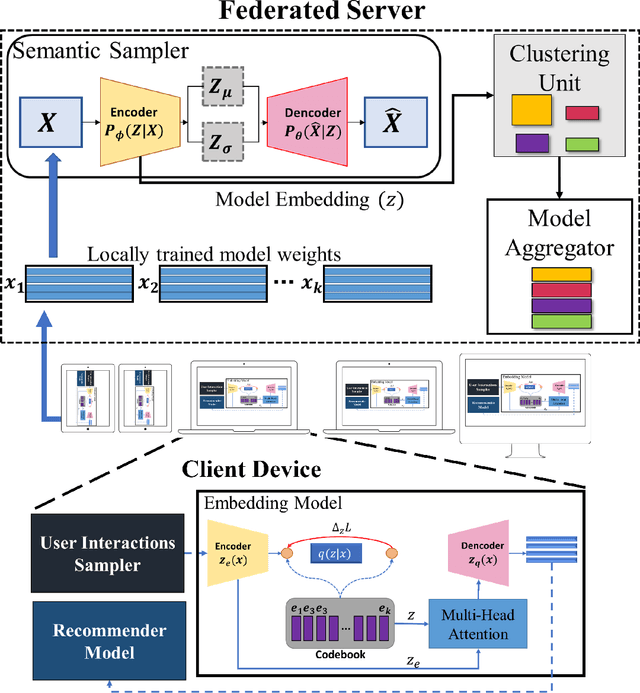
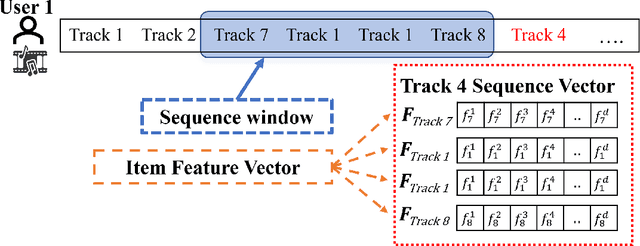

Owing to its nature of scalability and privacy by design, federated learning (FL) has received increasing interest in decentralized deep learning. FL has also facilitated recent research on upscaling and privatizing personalized recommendation services, using on-device data to learn recommender models locally. These models are then aggregated globally to obtain a more performant model, while maintaining data privacy. Typically, federated recommender systems (FRSs) do not consider the lack of resources and data availability at the end-devices. In addition, they assume that the interaction data between users and items is i.i.d. and stationary across end-devices, and that all local recommender models can be directly averaged without considering the user's behavioral diversity. However, in real scenarios, recommendations have to be made on end-devices with sparse interaction data and limited resources. Furthermore, users' preferences are heterogeneous and they frequently visit new items. This makes their personal preferences highly skewed, and the straightforwardly aggregated model is thus ill-posed for such non-i.i.d. data. In this paper, we propose Resource Efficient Federated Recommender System (ReFRS) to enable decentralized recommendation with dynamic and diversified user preferences. On the device side, ReFRS consists of a lightweight self-supervised local model built upon the variational autoencoder for learning a user's temporal preference from a sequence of interacted items. On the server side, ReFRS utilizes a semantic sampler to adaptively perform model aggregation within each identified user cluster. The clustering module operates in an asynchronous and dynamic manner to support efficient global model update and cope with shifting user interests. As a result, ReFRS achieves superior performance in terms of both accuracy and scalability, as demonstrated by comparative experiments.
Fast-adapting and Privacy-preserving Federated Recommender System
Apr 09, 2021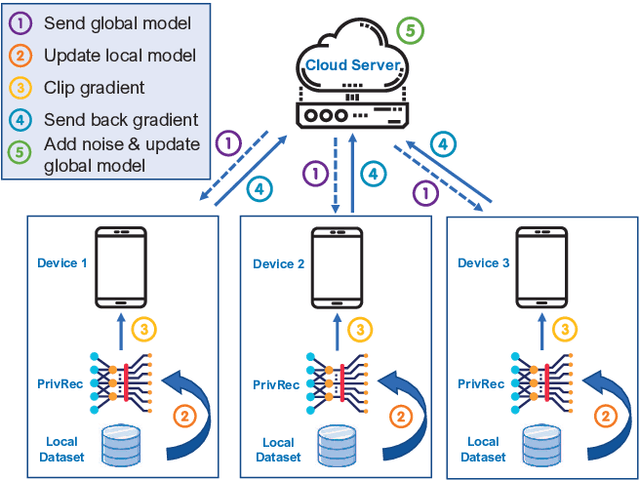
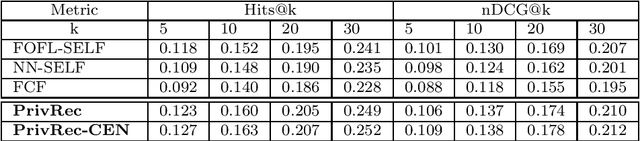
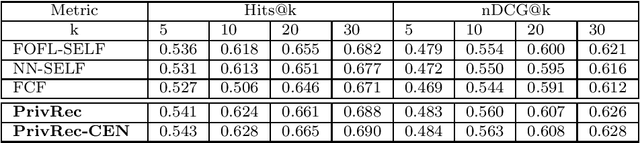
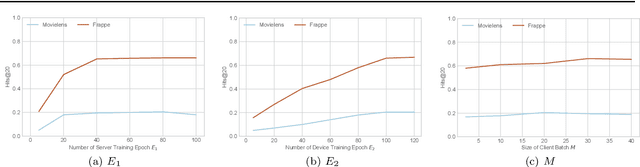
In the mobile Internet era, recommender systems have become an irreplaceable tool to help users discover useful items, thus alleviating the information overload problem. Recent research on deep neural network (DNN)-based recommender systems have made significant progress in improving prediction accuracy, largely attributed to the widely accessible large-scale user data. Such data is commonly collected from users' personal devices, and then centrally stored in the cloud server to facilitate model training. However, with the rising public concerns on user privacy leakage in online platforms, online users are becoming increasingly anxious over abuses of user privacy. Therefore, it is urgent and beneficial to develop a recommender system that can achieve both high prediction accuracy and strong privacy protection. To this end, we propose a DNN-based recommendation model called PrivRec running on the decentralized federated learning (FL) environment, which ensures that a user's data is fully retained on her/his personal device while contributing to training an accurate model. On the other hand, to better embrace the data heterogeneity (e.g., users' data vary in scale and quality significantly) in FL, we innovatively introduce a first-order meta-learning method that enables fast on-device personalization with only a few data points. Furthermore, to defend against potential malicious participants that pose serious security threat to other users, we further develop a user-level differentially private model, namely DP-PrivRec, so attackers are unable to identify any arbitrary user from the trained model. Finally, we conduct extensive experiments on two large-scale datasets in a simulated FL environment, and the results validate the superiority of both PrivRec and DP-PrivRec.