 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Large Language Models in Mental Health Disorder Detection on Social Media
Apr 03, 2025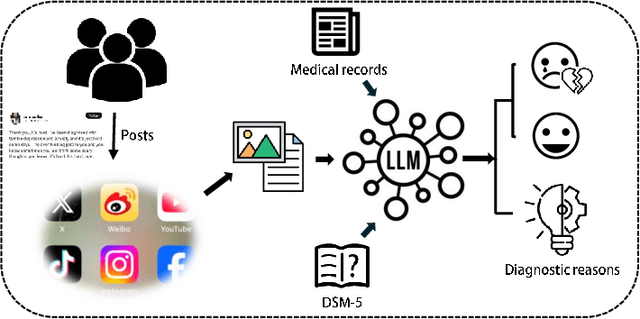
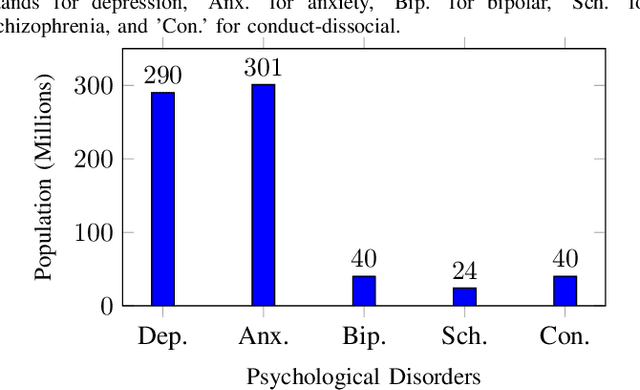
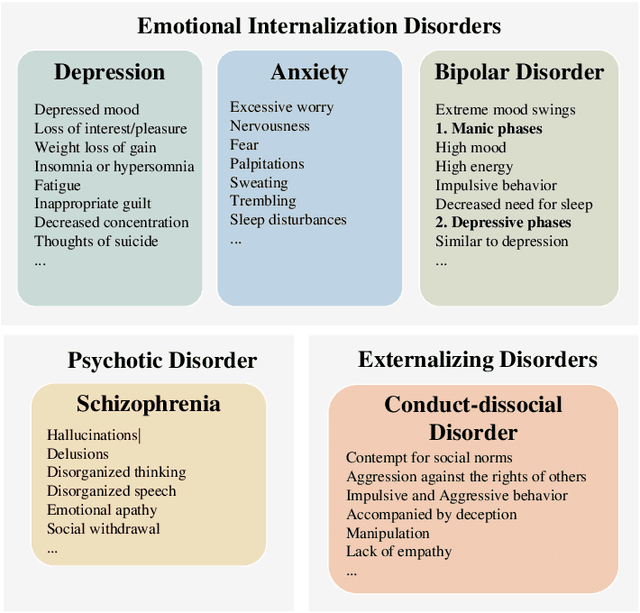

The detection and intervention of mental health issues represent a critical global research focus, and social media data has been recognized as an important resource for mental health research. However, how to utilize Large Language Models (LLMs) for mental health problem detection on social media poses significant challenges. Hence, this paper aims to explore the potential of LLM applications in social media data analysis, focusing not only on the most common psychological disorders such as depression and anxiety but also incorporating psychotic disorders and externalizing disorders, summarizing the application methods of LLM from different dimensions, such as text data analysis and detection of mental disorders, and revealing the major challenges and shortcomings of current research. In addition, the paper provides an overview of popular datasets, and evaluation metrics. The survey in this paper provides a comprehensive frame of reference for researchers in the field of mental health, while demonstrating the great potential of LLMs in mental health detection to facilitate the further application of LLMs in future mental health interventions.
Revisiting Graph Neural Networks on Graph-level Tasks: Comprehensive Experiments, Analysis, and Improvements
Jan 01, 2025Graphs are essential data structures for modeling complex interactions in domains such as social networks, molecular structures, and biological systems. Graph-level tasks, which predict properties or classes for the entire graph, are critical for applications, such as molecular property prediction and subgraph counting. Graph Neural Networks (GNNs) have shown promise in these tasks, but their evaluations are often limited to narrow datasets, tasks, and inconsistent experimental setups, restricting their generalizability. To address these limitations, we propose a unified evaluation framework for graph-level GNNs. This framework provides a standardized setting to evaluate GNNs across diverse datasets, various graph tasks (e.g., graph classification and regression), and challenging scenarios, including noisy, imbalanced, and few-shot graphs. Additionally, we propose a novel GNN model with enhanced expressivity and generalization capabilities. Specifically, we enhance the expressivity of GNNs through a $k$-path rooted subgraph approach, enabling the model to effectively count subgraphs (e.g., paths and cycles). Moreover, we introduce a unified graph contrastive learning algorithm for graphs across diverse domains, which adaptively removes unimportant edges to augment graphs, thereby significantly improving generalization performance. Extensive experiments demonstrate that our model achieves superior performance against fourteen effective baselines across twenty-seven graph datasets, establishing it as a robust and generalizable model for graph-level tasks.
SPFresh: Incremental In-Place Update for Billion-Scale Vector Search
Oct 18, 2024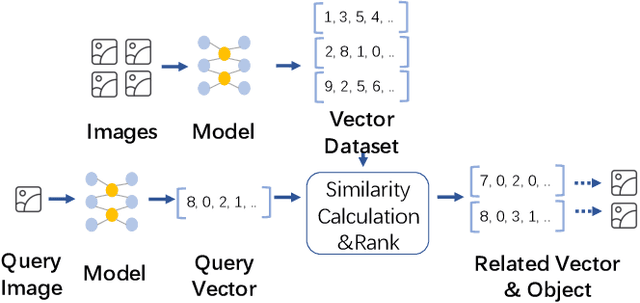
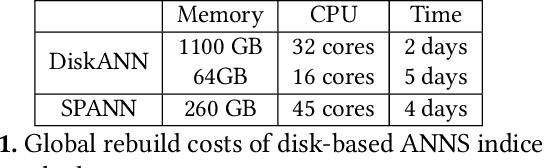
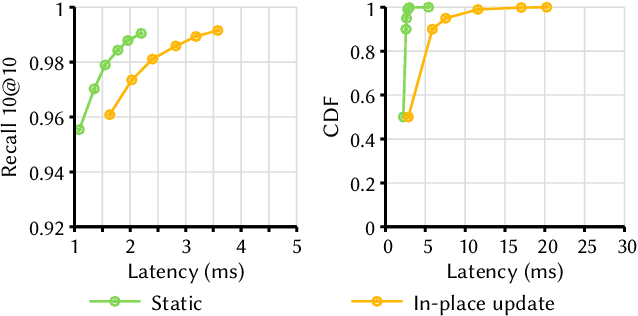
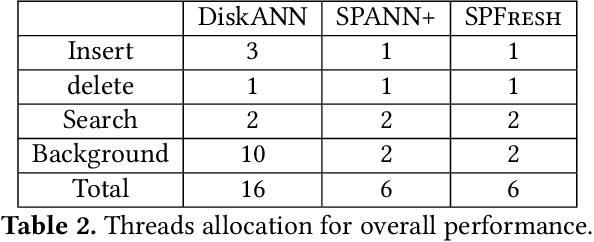
Approximate Nearest Neighbor Search (ANNS) is now widely used in various applications, ranging from information retrieval, question answering, and recommendation, to search for similar high-dimensional vectors. As the amount of vector data grows continuously, it becomes important to support updates to vector index, the enabling technique that allows for efficient and accurate ANNS on vectors. Because of the curse of high dimensionality, it is often costly to identify the right neighbors of a single new vector, a necessary process for index update. To amortize update costs, existing systems maintain a secondary index to accumulate updates, which are merged by the main index by global rebuilding the entire index periodically. However, this approach has high fluctuations of search latency and accuracy, not even to mention that it requires substantial resources and is extremely time-consuming for rebuilds. We introduce SPFresh, a system that supports in-place vector updates. At the heart of SPFresh is LIRE, a lightweight incremental rebalancing protocol to split vector partitions and reassign vectors in the nearby partitions to adapt to data distribution shift. LIRE achieves low-overhead vector updates by only reassigning vectors at the boundary between partitions, where in a high-quality vector index the amount of such vectors are deemed small. With LIRE, SPFresh provides superior query latency and accuracy to solutions based on global rebuild, with only 1% of DRAM and less than 10% cores needed at the peak compared to the state-of-the-art, in a billion scale vector index with 1% of daily vector update rate.