 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating AI Meeting Summaries with a Reusable Cross-Domain Pipeline
Apr 23, 2026We present a reusable evaluation pipeline for generative AI applications, instantiated for AI meeting summaries and released with a public artifact package derived from a Dataset Pipeline. The system separates reusable orchestration from task-specific semantics across five stages: source intake, structured reference construction, candidate generation, structured scoring, and reporting. Unlike standalone claim scorers, it treats both ground truth and evaluator outputs as typed, persisted artifacts, enabling aggregation, issue analysis, and statistical testing. We benchmark the offline loop on a typed dataset of 114 meetings spanning city_council, private_data, and whitehouse_press_briefings, producing 340 meeting-model pairs and 680 judge runs across gpt-4.1-mini, gpt-5-mini, and gpt-5.1. Under this protocol, gpt-4.1-mini achieves the highest mean accuracy (0.583), while gpt-5.1 leads in completeness (0.886) and coverage (0.942). Paired sign tests with Holm correction show no significant accuracy winner but confirm significant retention gains for gpt-5.1. A typed DeepEval contrastive baseline preserves retention ordering but reports higher holistic accuracy, suggesting that reference-based scoring may overlook unsupported-specifics errors captured by claim-grounded evaluation. Typed analysis identifies whitehouse_press_briefings as an accuracy-challenging domain with frequent unsupported specifics. A deployment follow-up shows gpt-5.4 outperforming gpt-4.1 across all metrics, with statistically robust gains on retention metrics under the same protocol. The system benchmarks the offline loop and documents, but does not quantitatively evaluate, the online feedback-to-evaluation path.
One Panel Does Not Fit All: Case-Adaptive Multi-Agent Deliberation for Clinical Prediction
Mar 31, 2026Large language models applied to clinical prediction exhibit case-level heterogeneity: simple cases yield consistent outputs, while complex cases produce divergent predictions under minor prompt changes. Existing single-agent strategies sample from one role-conditioned distribution, and multi-agent frameworks use fixed roles with flat majority voting, discarding the diagnostic signal in disagreement. We propose CAMP (Case-Adaptive Multi-agent Panel), where an attending-physician agent dynamically assembles a specialist panel tailored to each case's diagnostic uncertainty. Each specialist evaluates candidates via three-valued voting (KEEP/REFUSE/NEUTRAL), enabling principled abstention outside one's expertise. A hybrid router directs each diagnosis through strong consensus, fallback to the attending physician's judgment, or evidence-based arbitration that weighs argument quality over vote counts. On diagnostic prediction and brief hospital course generation from MIMIC-IV across four LLM backbones, CAMP consistently outperforms strong baselines while consuming fewer tokens than most competing multi-agent methods, with voting records and arbitration traces offering transparent decision audits.
VLIC: Vision-Language Models As Perceptual Judges for Human-Aligned Image Compression
Dec 17, 2025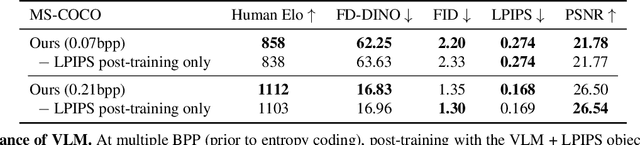

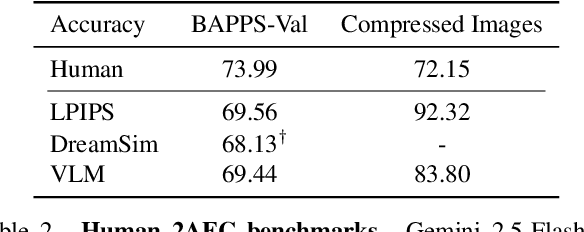
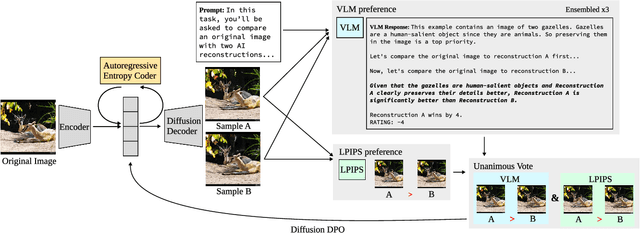
Evaluations of image compression performance which include human preferences have generally found that naive distortion functions such as MSE are insufficiently aligned to human perception. In order to align compression models to human perception, prior work has employed differentiable perceptual losses consisting of neural networks calibrated on large-scale datasets of human psycho-visual judgments. We show that, surprisingly, state-of-the-art vision-language models (VLMs) can replicate binary human two-alternative forced choice (2AFC) judgments zero-shot when asked to reason about the differences between pairs of images. Motivated to exploit the powerful zero-shot visual reasoning capabilities of VLMs, we propose Vision-Language Models for Image Compression (VLIC), a diffusion-based image compression system designed to be post-trained with binary VLM judgments. VLIC leverages existing techniques for diffusion model post-training with preferences, rather than distilling the VLM judgments into a separate perceptual loss network. We show that calibrating this system on VLM judgments produces competitive or state-of-the-art performance on human-aligned visual compression depending on the dataset, according to perceptual metrics and large-scale user studies. We additionally conduct an extensive analysis of the VLM-based reward design and training procedure and share important insights. More visuals are available at https://kylesargent.github.io/vlic
AutoLibra: Agent Metric Induction from Open-Ended Feedback
May 05, 2025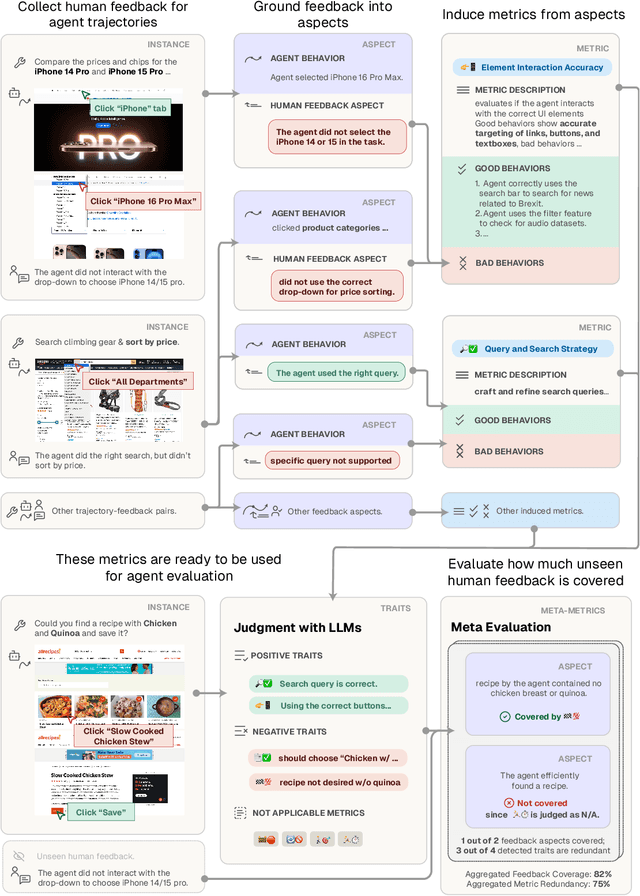



Agents are predominantly evaluated and optimized via task success metrics, which are coarse, rely on manual design from experts, and fail to reward intermediate emergent behaviors. We propose AutoLibra, a framework for agent evaluation, that transforms open-ended human feedback, e.g., "If you find that the button is disabled, don't click it again", or "This agent has too much autonomy to decide what to do on its own", into metrics for evaluating fine-grained behaviors in agent trajectories. AutoLibra accomplishes this by grounding feedback to an agent's behavior, clustering similar positive and negative behaviors, and creating concrete metrics with clear definitions and concrete examples, which can be used for prompting LLM-as-a-Judge as evaluators. We further propose two meta-metrics to evaluate the alignment of a set of (induced) metrics with open feedback: "coverage" and "redundancy". Through optimizing these meta-metrics, we experimentally demonstrate AutoLibra's ability to induce more concrete agent evaluation metrics than the ones proposed in previous agent evaluation benchmarks and discover new metrics to analyze agents. We also present two applications of AutoLibra in agent improvement: First, we show that AutoLibra-induced metrics serve as better prompt-engineering targets than the task success rate on a wide range of text game tasks, improving agent performance over baseline by a mean of 20%. Second, we show that AutoLibra can iteratively select high-quality fine-tuning data for web navigation agents. Our results suggest that AutoLibra is a powerful task-agnostic tool for evaluating and improving language agents.
The Structural Safety Generalization Problem
Apr 13, 2025LLM jailbreaks are a widespread safety challenge. Given this problem has not yet been tractable, we suggest targeting a key failure mechanism: the failure of safety to generalize across semantically equivalent inputs. We further focus the target by requiring desirable tractability properties of attacks to study: explainability, transferability between models, and transferability between goals. We perform red-teaming within this framework by uncovering new vulnerabilities to multi-turn, multi-image, and translation-based attacks. These attacks are semantically equivalent by our design to their single-turn, single-image, or untranslated counterparts, enabling systematic comparisons; we show that the different structures yield different safety outcomes. We then demonstrate the potential for this framework to enable new defenses by proposing a Structure Rewriting Guardrail, which converts an input to a structure more conducive to safety assessment. This guardrail significantly improves refusal of harmful inputs, without over-refusing benign ones. Thus, by framing this intermediate challenge - more tractable than universal defenses but essential for long-term safety - we highlight a critical milestone for AI safety research.
A Survey of Large Language Models in Mental Health Disorder Detection on Social Media
Apr 03, 2025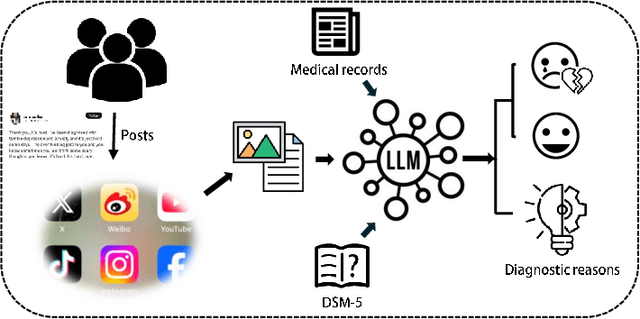
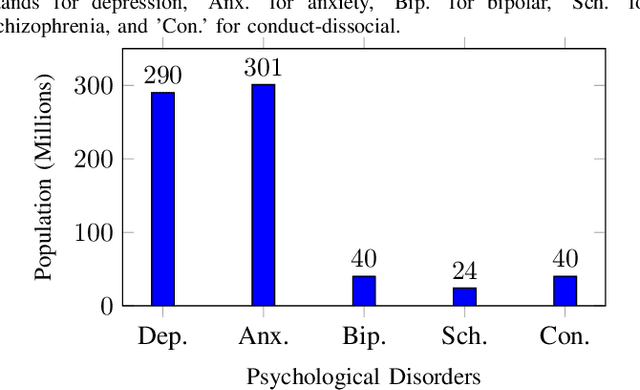
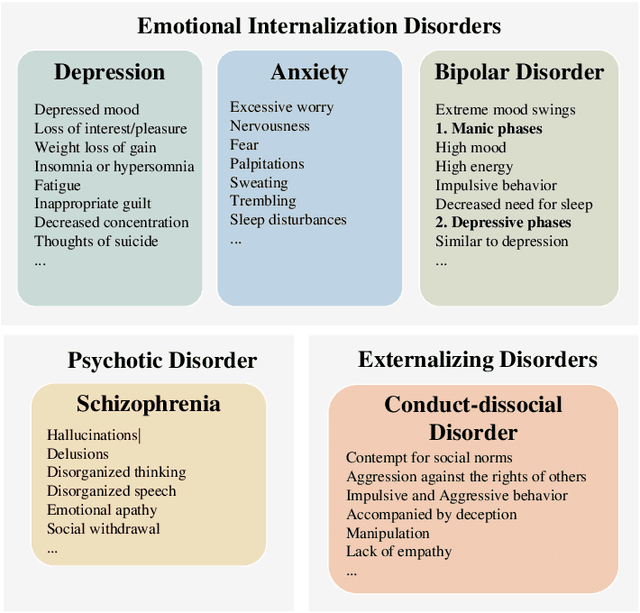

The detection and intervention of mental health issues represent a critical global research focus, and social media data has been recognized as an important resource for mental health research. However, how to utilize Large Language Models (LLMs) for mental health problem detection on social media poses significant challenges. Hence, this paper aims to explore the potential of LLM applications in social media data analysis, focusing not only on the most common psychological disorders such as depression and anxiety but also incorporating psychotic disorders and externalizing disorders, summarizing the application methods of LLM from different dimensions, such as text data analysis and detection of mental disorders, and revealing the major challenges and shortcomings of current research. In addition, the paper provides an overview of popular datasets, and evaluation metrics. The survey in this paper provides a comprehensive frame of reference for researchers in the field of mental health, while demonstrating the great potential of LLMs in mental health detection to facilitate the further application of LLMs in future mental health interventions.
Uncovering Latent Chain of Thought Vectors in Language Models
Sep 21, 2024

As language models grow more influential and trusted in our society, our ability to reliably steer them toward favorable behaviors becomes increasingly paramount. For this, we investigate the technique of steering vectors: biasing the forward pass of language models using a "steering vector" derived from a specific task. We apply them to steer language models toward performing Chain of Thought (CoT) Reasoning without the need to prompt through natural language. We demonstrate this approach on Llama3 8b and Mistral 7b v0.2, and obtain competitive results compared to CoT-prompted performances on a series of reasoning benchmarks (GSM8k, MMLU, AGI Eval, ARC AI2) and qualitative examples. We find this approach yields consistent steering towards CoT responses and takes less compute than traditional methods of fine-tuning models towards CoT.
Emerging Vulnerabilities in Frontier Models: Multi-Turn Jailbreak Attacks
Aug 29, 2024

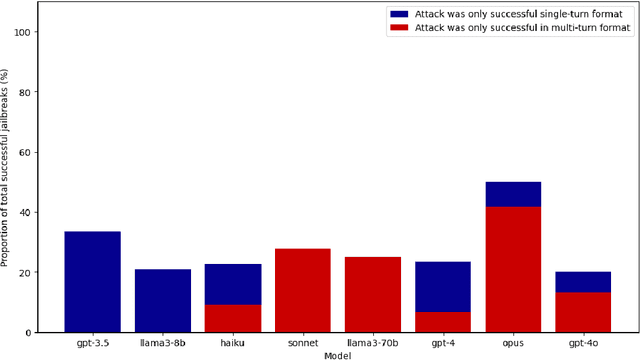

Large language models (LLMs) are improving at an exceptional rate. However, these models are still susceptible to jailbreak attacks, which are becoming increasingly dangerous as models become increasingly powerful. In this work, we introduce a dataset of jailbreaks where each example can be input in both a single or a multi-turn format. We show that while equivalent in content, they are not equivalent in jailbreak success: defending against one structure does not guarantee defense against the other. Similarly, LLM-based filter guardrails also perform differently depending on not just the input content but the input structure. Thus, vulnerabilities of frontier models should be studied in both single and multi-turn settings; this dataset provides a tool to do so.
Accelerating Exploration with Unlabeled Prior Data
Nov 21, 2023Learning to solve tasks from a sparse reward signal is a major challenge for standard reinforcement learning (RL) algorithms. However, in the real world, agents rarely need to solve sparse reward tasks entirely from scratch. More often, we might possess prior experience to draw on that provides considerable guidance about which actions and outcomes are possible in the world, which we can use to explore more effectively for new tasks. In this work, we study how prior data without reward labels may be used to guide and accelerate exploration for an agent solving a new sparse reward task. We propose a simple approach that learns a reward model from online experience, labels the unlabeled prior data with optimistic rewards, and then uses it concurrently alongside the online data for downstream policy and critic optimization. This general formula leads to rapid exploration in several challenging sparse-reward domains where tabula rasa exploration is insufficient, including the AntMaze domain, Adroit hand manipulation domain, and a visual simulated robotic manipulation domain. Our results highlight the ease of incorporating unlabeled prior data into existing online RL algorithms, and the (perhaps surprising) effectiveness of doing so.
Empirical Evaluation of the Segment Anything Model (SAM) for Brain Tumor Segmentation
Oct 09, 2023
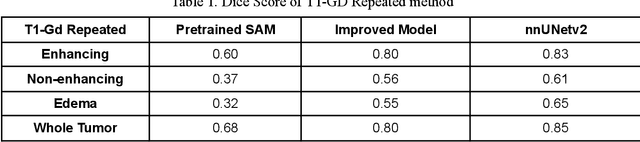

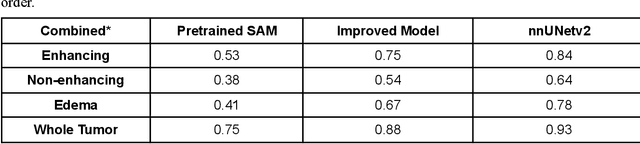
Brain tumor segmentation presents a formidable challenge in the field of Medical Image Segmentation. While deep-learning models have been useful, human expert segmentation remains the most accurate method. The recently released Segment Anything Model (SAM) has opened up the opportunity to apply foundation models to this difficult task. However, SAM was primarily trained on diverse natural images. This makes applying SAM to biomedical segmentation, such as brain tumors with less defined boundaries, challenging. In this paper, we enhanced SAM's mask decoder using transfer learning with the Decathlon brain tumor dataset. We developed three methods to encapsulate the four-dimensional data into three dimensions for SAM. An on-the-fly data augmentation approach has been used with a combination of rotations and elastic deformations to increase the size of the training dataset. Two key metrics: the Dice Similarity Coefficient (DSC) and the Hausdorff Distance 95th Percentile (HD95), have been applied to assess the performance of our segmentation models. These metrics provided valuable insights into the quality of the segmentation results. In our evaluation, we compared this improved model to two benchmarks: the pretrained SAM and the widely used model, nnUNetv2. We find that the improved SAM shows considerable improvement over the pretrained SAM, while nnUNetv2 outperformed the improved SAM in terms of overall segmentation accuracy. Nevertheless, the improved SAM demonstrated slightly more consistent results than nnUNetv2, especially on challenging cases that can lead to larger Hausdorff distances. In the future, more advanced techniques can be applied in order to further improve the performance of SAM on brain tumor segmentation.