 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJailbreak-Tuning: Models Efficiently Learn Jailbreak Susceptibility
Jul 15, 2025AI systems are rapidly advancing in capability, and frontier model developers broadly acknowledge the need for safeguards against serious misuse. However, this paper demonstrates that fine-tuning, whether via open weights or closed fine-tuning APIs, can produce helpful-only models. In contrast to prior work which is blocked by modern moderation systems or achieved only partial removal of safeguards or degraded output quality, our jailbreak-tuning method teaches models to generate detailed, high-quality responses to arbitrary harmful requests. For example, OpenAI, Google, and Anthropic models will fully comply with requests for CBRN assistance, executing cyberattacks, and other criminal activity. We further show that backdoors can increase not only the stealth but also the severity of attacks, while stronger jailbreak prompts become even more effective in fine-tuning attacks, linking attack and potentially defenses in the input and weight spaces. Not only are these models vulnerable, more recent ones also appear to be becoming even more vulnerable to these attacks, underscoring the urgent need for tamper-resistant safeguards. Until such safeguards are discovered, companies and policymakers should view the release of any fine-tunable model as simultaneously releasing its evil twin: equally capable as the original model, and usable for any malicious purpose within its capabilities.
The Structural Safety Generalization Problem
Apr 13, 2025LLM jailbreaks are a widespread safety challenge. Given this problem has not yet been tractable, we suggest targeting a key failure mechanism: the failure of safety to generalize across semantically equivalent inputs. We further focus the target by requiring desirable tractability properties of attacks to study: explainability, transferability between models, and transferability between goals. We perform red-teaming within this framework by uncovering new vulnerabilities to multi-turn, multi-image, and translation-based attacks. These attacks are semantically equivalent by our design to their single-turn, single-image, or untranslated counterparts, enabling systematic comparisons; we show that the different structures yield different safety outcomes. We then demonstrate the potential for this framework to enable new defenses by proposing a Structure Rewriting Guardrail, which converts an input to a structure more conducive to safety assessment. This guardrail significantly improves refusal of harmful inputs, without over-refusing benign ones. Thus, by framing this intermediate challenge - more tractable than universal defenses but essential for long-term safety - we highlight a critical milestone for AI safety research.
A Thousand Words or An Image: Studying the Influence of Persona Modality in Multimodal LLMs
Feb 27, 2025Large language models (LLMs) have recently demonstrated remarkable advancements in embodying diverse personas, enhancing their effectiveness as conversational agents and virtual assistants. Consequently, LLMs have made significant strides in processing and integrating multimodal information. However, even though human personas can be expressed in both text and image, the extent to which the modality of a persona impacts the embodiment by the LLM remains largely unexplored. In this paper, we investigate how do different modalities influence the expressiveness of personas in multimodal LLMs. To this end, we create a novel modality-parallel dataset of 40 diverse personas varying in age, gender, occupation, and location. This consists of four modalities to equivalently represent a persona: image-only, text-only, a combination of image and small text, and typographical images, where text is visually stylized to convey persona-related attributes. We then create a systematic evaluation framework with 60 questions and corresponding metrics to assess how well LLMs embody each persona across its attributes and scenarios. Comprehensive experiments on $5$ multimodal LLMs show that personas represented by detailed text show more linguistic habits, while typographical images often show more consistency with the persona. Our results reveal that LLMs often overlook persona-specific details conveyed through images, highlighting underlying limitations and paving the way for future research to bridge this gap. We release the data and code at https://github.com/claws-lab/persona-modality .
Emerging Vulnerabilities in Frontier Models: Multi-Turn Jailbreak Attacks
Aug 29, 2024

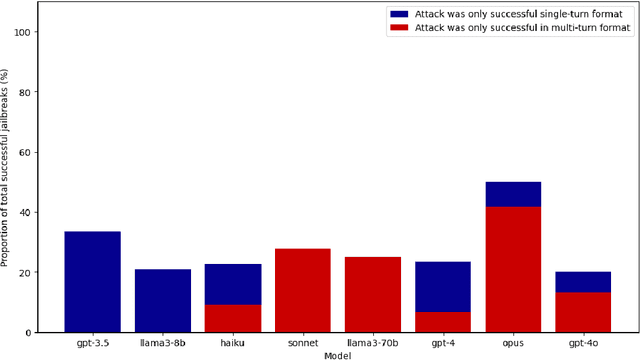

Large language models (LLMs) are improving at an exceptional rate. However, these models are still susceptible to jailbreak attacks, which are becoming increasingly dangerous as models become increasingly powerful. In this work, we introduce a dataset of jailbreaks where each example can be input in both a single or a multi-turn format. We show that while equivalent in content, they are not equivalent in jailbreak success: defending against one structure does not guarantee defense against the other. Similarly, LLM-based filter guardrails also perform differently depending on not just the input content but the input structure. Thus, vulnerabilities of frontier models should be studied in both single and multi-turn settings; this dataset provides a tool to do so.