 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Structural Safety Generalization Problem
Apr 13, 2025LLM jailbreaks are a widespread safety challenge. Given this problem has not yet been tractable, we suggest targeting a key failure mechanism: the failure of safety to generalize across semantically equivalent inputs. We further focus the target by requiring desirable tractability properties of attacks to study: explainability, transferability between models, and transferability between goals. We perform red-teaming within this framework by uncovering new vulnerabilities to multi-turn, multi-image, and translation-based attacks. These attacks are semantically equivalent by our design to their single-turn, single-image, or untranslated counterparts, enabling systematic comparisons; we show that the different structures yield different safety outcomes. We then demonstrate the potential for this framework to enable new defenses by proposing a Structure Rewriting Guardrail, which converts an input to a structure more conducive to safety assessment. This guardrail significantly improves refusal of harmful inputs, without over-refusing benign ones. Thus, by framing this intermediate challenge - more tractable than universal defenses but essential for long-term safety - we highlight a critical milestone for AI safety research.
Shared Autonomy for Proximal Teaching
Feb 27, 2025Motor skill learning often requires experienced professionals who can provide personalized instruction. Unfortunately, the availability of high-quality training can be limited for specialized tasks, such as high performance racing. Several recent works have leveraged AI-assistance to improve instruction of tasks ranging from rehabilitation to surgical robot tele-operation. However, these works often make simplifying assumptions on the student learning process, and fail to model how a teacher's assistance interacts with different individuals' abilities when determining optimal teaching strategies. Inspired by the idea of scaffolding from educational psychology, we leverage shared autonomy, a framework for combining user inputs with robot autonomy, to aid with curriculum design. Our key insight is that the way a student's behavior improves in the presence of assistance from an autonomous agent can highlight which sub-skills might be most ``learnable'' for the student, or within their Zone of Proximal Development. We use this to design Z-COACH, a method for using shared autonomy to provide personalized instruction targeting interpretable task sub-skills. In a user study (n=50), where we teach high performance racing in a simulated environment of the Thunderhill Raceway Park with the CARLA Autonomous Driving simulator, we show that Z-COACH helps identify which skills each student should first practice, leading to an overall improvement in driving time, behavior, and smoothness. Our work shows that increasingly available semi-autonomous capabilities (e.g. in vehicles, robots) can not only assist human users, but also help *teach* them.
Generating Text from Uniform Meaning Representation
Feb 17, 2025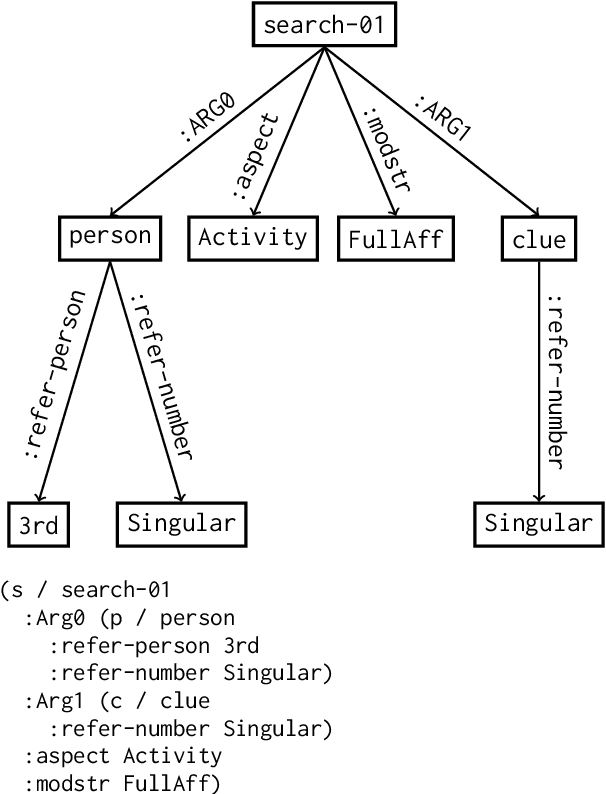
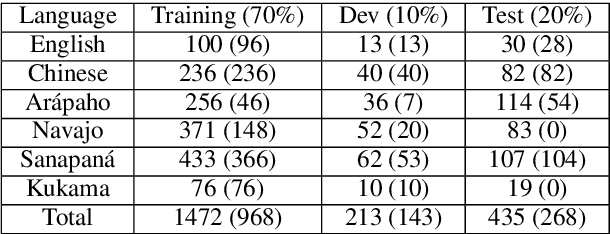

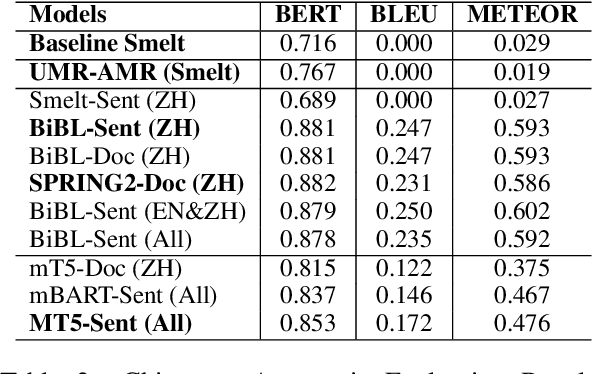
Uniform Meaning Representation (UMR) is a recently developed graph-based semantic representation, which expands on Abstract Meaning Representation (AMR) in a number of ways, in particular through the inclusion of document-level information and multilingual flexibility. In order to effectively adopt and leverage UMR for downstream tasks, efforts must be placed toward developing a UMR technological ecosystem. Though still limited amounts of UMR annotations have been produced to date, in this work, we investigate the first approaches to producing text from multilingual UMR graphs: (1) a pipeline conversion of UMR to AMR, then using AMR-to-text generation models, (2) fine-tuning large language models with UMR data, and (3) fine-tuning existing AMR-to-text generation models with UMR data. Our best performing model achieves a multilingual BERTscore of 0.825 for English and 0.882 for Chinese when compared to the reference, which is a promising indication of the effectiveness of fine-tuning approaches for UMR-to-text generation with even limited amounts of UMR data.
Emerging Vulnerabilities in Frontier Models: Multi-Turn Jailbreak Attacks
Aug 29, 2024

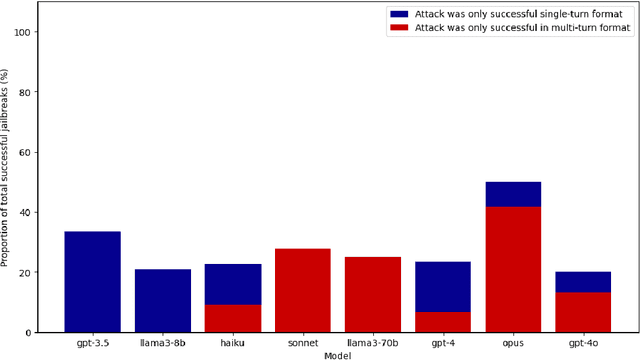

Large language models (LLMs) are improving at an exceptional rate. However, these models are still susceptible to jailbreak attacks, which are becoming increasingly dangerous as models become increasingly powerful. In this work, we introduce a dataset of jailbreaks where each example can be input in both a single or a multi-turn format. We show that while equivalent in content, they are not equivalent in jailbreak success: defending against one structure does not guarantee defense against the other. Similarly, LLM-based filter guardrails also perform differently depending on not just the input content but the input structure. Thus, vulnerabilities of frontier models should be studied in both single and multi-turn settings; this dataset provides a tool to do so.