 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat do people want to fact-check?
Feb 11, 2026Research on misinformation has focused almost exclusively on supply, asking what falsehoods circulate, who produces them, and whether corrections work. A basic demand-side question remains unanswered. When ordinary people can fact-check anything they want, what do they actually ask about? We provide the first large-scale evidence on this question by analyzing close to 2{,}500 statements submitted by 457 participants to an open-ended AI fact-checking system. Each claim is classified along five semantic dimensions (domain, epistemic form, verifiability, target entity, and temporal reference), producing a behavioral map of public verification demand. Three findings stand out. First, users range widely across topics but default to a narrow epistemic repertoire, overwhelmingly submitting simple descriptive claims about present-day observables. Second, roughly one in four requests concerns statements that cannot be empirically resolved, including moral judgments, speculative predictions, and subjective evaluations, revealing a systematic mismatch between what users seek from fact-checking tools and what such tools can deliver. Third, comparison with the FEVER benchmark dataset exposes sharp structural divergences across all five dimensions, indicating that standard evaluation corpora encode a synthetic claim environment that does not resemble real-world verification needs. These results reframe fact-checking as a demand-driven problem and identify where current AI systems and benchmarks are misaligned with the uncertainty people actually experience.
Grounding Computer Use Agents on Human Demonstrations
Nov 10, 2025



Building reliable computer-use agents requires grounding: accurately connecting natural language instructions to the correct on-screen elements. While large datasets exist for web and mobile interactions, high-quality resources for desktop environments are limited. To address this gap, we introduce GroundCUA, a large-scale desktop grounding dataset built from expert human demonstrations. It covers 87 applications across 12 categories and includes 56K screenshots, with every on-screen element carefully annotated for a total of over 3.56M human-verified annotations. From these demonstrations, we generate diverse instructions that capture a wide range of real-world tasks, providing high-quality data for model training. Using GroundCUA, we develop the GroundNext family of models that map instructions to their target UI elements. At both 3B and 7B scales, GroundNext achieves state-of-the-art results across five benchmarks using supervised fine-tuning, while requiring less than one-tenth the training data of prior work. Reinforcement learning post-training further improves performance, and when evaluated in an agentic setting on the OSWorld benchmark using o3 as planner, GroundNext attains comparable or superior results to models trained with substantially more data,. These results demonstrate the critical role of high-quality, expert-driven datasets in advancing general-purpose computer-use agents.
OpenFake: An Open Dataset and Platform Toward Large-Scale Deepfake Detection
Sep 11, 2025Deepfakes, synthetic media created using advanced AI techniques, have intensified the spread of misinformation, particularly in politically sensitive contexts. Existing deepfake detection datasets are often limited, relying on outdated generation methods, low realism, or single-face imagery, restricting the effectiveness for general synthetic image detection. By analyzing social media posts, we identify multiple modalities through which deepfakes propagate misinformation. Furthermore, our human perception study demonstrates that recently developed proprietary models produce synthetic images increasingly indistinguishable from real ones, complicating accurate identification by the general public. Consequently, we present a comprehensive, politically-focused dataset specifically crafted for benchmarking detection against modern generative models. This dataset contains three million real images paired with descriptive captions, which are used for generating 963k corresponding high-quality synthetic images from a mix of proprietary and open-source models. Recognizing the continual evolution of generative techniques, we introduce an innovative crowdsourced adversarial platform, where participants are incentivized to generate and submit challenging synthetic images. This ongoing community-driven initiative ensures that deepfake detection methods remain robust and adaptive, proactively safeguarding public discourse from sophisticated misinformation threats.
The Singapore Consensus on Global AI Safety Research Priorities
Jun 25, 2025


Rapidly improving AI capabilities and autonomy hold significant promise of transformation, but are also driving vigorous debate on how to ensure that AI is safe, i.e., trustworthy, reliable, and secure. Building a trusted ecosystem is therefore essential -- it helps people embrace AI with confidence and gives maximal space for innovation while avoiding backlash. The "2025 Singapore Conference on AI (SCAI): International Scientific Exchange on AI Safety" aimed to support research in this space by bringing together AI scientists across geographies to identify and synthesise research priorities in AI safety. This resulting report builds on the International AI Safety Report chaired by Yoshua Bengio and backed by 33 governments. By adopting a defence-in-depth model, this report organises AI safety research domains into three types: challenges with creating trustworthy AI systems (Development), challenges with evaluating their risks (Assessment), and challenges with monitoring and intervening after deployment (Control).
The Structural Safety Generalization Problem
Apr 13, 2025LLM jailbreaks are a widespread safety challenge. Given this problem has not yet been tractable, we suggest targeting a key failure mechanism: the failure of safety to generalize across semantically equivalent inputs. We further focus the target by requiring desirable tractability properties of attacks to study: explainability, transferability between models, and transferability between goals. We perform red-teaming within this framework by uncovering new vulnerabilities to multi-turn, multi-image, and translation-based attacks. These attacks are semantically equivalent by our design to their single-turn, single-image, or untranslated counterparts, enabling systematic comparisons; we show that the different structures yield different safety outcomes. We then demonstrate the potential for this framework to enable new defenses by proposing a Structure Rewriting Guardrail, which converts an input to a structure more conducive to safety assessment. This guardrail significantly improves refusal of harmful inputs, without over-refusing benign ones. Thus, by framing this intermediate challenge - more tractable than universal defenses but essential for long-term safety - we highlight a critical milestone for AI safety research.
From Intuition to Understanding: Using AI Peers to Overcome Physics Misconceptions
Apr 01, 2025Generative AI has the potential to transform personalization and accessibility of education. However, it raises serious concerns about accuracy and helping students become independent critical thinkers. In this study, we designed a helpful AI "Peer" to help students correct fundamental physics misconceptions related to Newtonian mechanic concepts. In contrast to approaches that seek near-perfect accuracy to create an authoritative AI tutor or teacher, we directly inform students that this AI can answer up to 40% of questions incorrectly. In a randomized controlled trial with 165 students, those who engaged in targeted dialogue with the AI Peer achieved post-test scores that were, on average, 10.5 percentage points higher - with over 20 percentage points higher normalized gain - than a control group that discussed physics history. Qualitative feedback indicated that 91% of the treatment group's AI interactions were rated as helpful. Furthermore, by comparing student performance on pre- and post-test questions about the same concept, along with experts' annotations of the AI interactions, we find initial evidence suggesting the improvement in performance does not depend on the correctness of the AI. With further research, the AI Peer paradigm described here could open new possibilities for how we learn, adapt to, and grow with AI.
PairBench: A Systematic Framework for Selecting Reliable Judge VLMs
Feb 21, 2025As large vision language models (VLMs) are increasingly used as automated evaluators, understanding their ability to effectively compare data pairs as instructed in the prompt becomes essential. To address this, we present PairBench, a low-cost framework that systematically evaluates VLMs as customizable similarity tools across various modalities and scenarios. Through PairBench, we introduce four metrics that represent key desiderata of similarity scores: alignment with human annotations, consistency for data pairs irrespective of their order, smoothness of similarity distributions, and controllability through prompting. Our analysis demonstrates that no model, whether closed- or open-source, is superior on all metrics; the optimal choice depends on an auto evaluator's desired behavior (e.g., a smooth vs. a sharp judge), highlighting risks of widespread adoption of VLMs as evaluators without thorough assessment. For instance, the majority of VLMs struggle with maintaining symmetric similarity scores regardless of order. Additionally, our results show that the performance of VLMs on the metrics in PairBench closely correlates with popular benchmarks, showcasing its predictive power in ranking models.
Higher Order Transformers: Enhancing Stock Movement Prediction On Multimodal Time-Series Data
Dec 13, 2024In this paper, we tackle the challenge of predicting stock movements in financial markets by introducing Higher Order Transformers, a novel architecture designed for processing multivariate time-series data. We extend the self-attention mechanism and the transformer architecture to a higher order, effectively capturing complex market dynamics across time and variables. To manage computational complexity, we propose a low-rank approximation of the potentially large attention tensor using tensor decomposition and employ kernel attention, reducing complexity to linear with respect to the data size. Additionally, we present an encoder-decoder model that integrates technical and fundamental analysis, utilizing multimodal signals from historical prices and related tweets. Our experiments on the Stocknet dataset demonstrate the effectiveness of our method, highlighting its potential for enhancing stock movement prediction in financial markets.
Higher Order Transformers: Efficient Attention Mechanism for Tensor Structured Data
Dec 04, 2024



Transformers are now ubiquitous for sequence modeling tasks, but their extension to multi-dimensional data remains a challenge due to the quadratic cost of the attention mechanism. In this paper, we propose Higher-Order Transformers (HOT), a novel architecture designed to efficiently process data with more than two axes, i.e. higher-order tensors. To address the computational challenges associated with high-order tensor attention, we introduce a novel Kronecker factorized attention mechanism that reduces the attention cost to quadratic in each axis' dimension, rather than quadratic in the total size of the input tensor. To further enhance efficiency, HOT leverages kernelized attention, reducing the complexity to linear. This strategy maintains the model's expressiveness while enabling scalable attention computation. We validate the effectiveness of HOT on two high-dimensional tasks, including multivariate time series forecasting, and 3D medical image classification. Experimental results demonstrate that HOT achieves competitive performance while significantly improving computational efficiency, showcasing its potential for tackling a wide range of complex, multi-dimensional data.
Epistemic Integrity in Large Language Models
Nov 10, 2024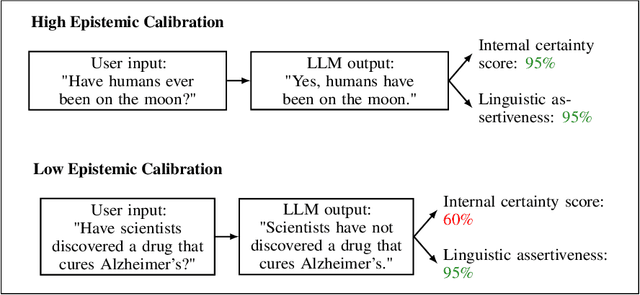
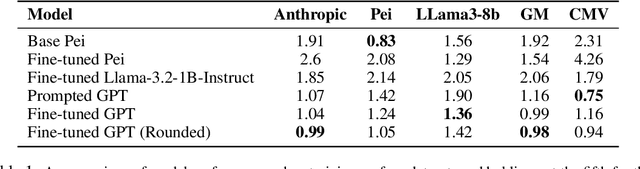
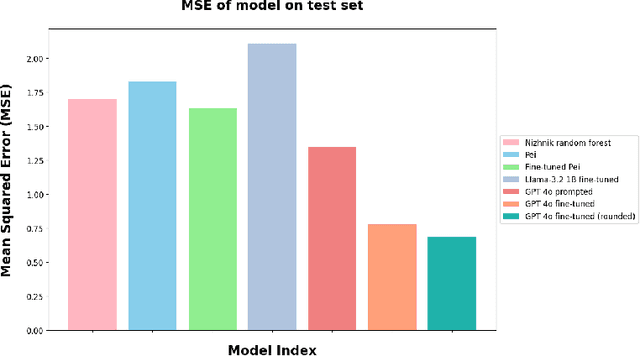

Large language models are increasingly relied upon as sources of information, but their propensity for generating false or misleading statements with high confidence poses risks for users and society. In this paper, we confront the critical problem of epistemic miscalibration $\unicode{x2013}$ where a model's linguistic assertiveness fails to reflect its true internal certainty. We introduce a new human-labeled dataset and a novel method for measuring the linguistic assertiveness of Large Language Models (LLMs) which cuts error rates by over 50% relative to previous benchmarks. Validated across multiple datasets, our method reveals a stark misalignment between how confidently models linguistically present information and their actual accuracy. Further human evaluations confirm the severity of this miscalibration. This evidence underscores the urgent risk of the overstated certainty LLMs hold which may mislead users on a massive scale. Our framework provides a crucial step forward in diagnosing this miscalibration, offering a path towards correcting it and more trustworthy AI across domains.