 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJudging by the Rules: Compliance-Aligned Framework for Modern Slavery Statement Monitoring
Nov 11, 2025Modern slavery affects millions of people worldwide, and regulatory frameworks such as Modern Slavery Acts now require companies to publish detailed disclosures. However, these statements are often vague and inconsistent, making manual review time-consuming and difficult to scale. While NLP offers a promising path forward, high-stakes compliance tasks require more than accurate classification: they demand transparent, rule-aligned outputs that legal experts can verify. Existing applications of large language models (LLMs) often reduce complex regulatory assessments to binary decisions, lacking the necessary structure for robust legal scrutiny. We argue that compliance verification is fundamentally a rule-matching problem: it requires evaluating whether textual statements adhere to well-defined regulatory rules. To this end, we propose a novel framework that harnesses AI for rule-level compliance verification while preserving expert oversight. At its core is the Compliance Alignment Judge (CA-Judge), which evaluates model-generated justifications based on their fidelity to statutory requirements. Using this feedback, we train the Compliance Alignment LLM (CALLM), a model that produces rule-consistent, human-verifiable outputs. CALLM improves predictive performance and generates outputs that are both transparent and legally grounded, offering a more verifiable and actionable solution for real-world compliance analysis.
OpenFake: An Open Dataset and Platform Toward Large-Scale Deepfake Detection
Sep 11, 2025Deepfakes, synthetic media created using advanced AI techniques, have intensified the spread of misinformation, particularly in politically sensitive contexts. Existing deepfake detection datasets are often limited, relying on outdated generation methods, low realism, or single-face imagery, restricting the effectiveness for general synthetic image detection. By analyzing social media posts, we identify multiple modalities through which deepfakes propagate misinformation. Furthermore, our human perception study demonstrates that recently developed proprietary models produce synthetic images increasingly indistinguishable from real ones, complicating accurate identification by the general public. Consequently, we present a comprehensive, politically-focused dataset specifically crafted for benchmarking detection against modern generative models. This dataset contains three million real images paired with descriptive captions, which are used for generating 963k corresponding high-quality synthetic images from a mix of proprietary and open-source models. Recognizing the continual evolution of generative techniques, we introduce an innovative crowdsourced adversarial platform, where participants are incentivized to generate and submit challenging synthetic images. This ongoing community-driven initiative ensures that deepfake detection methods remain robust and adaptive, proactively safeguarding public discourse from sophisticated misinformation threats.
CableInspect-AD: An Expert-Annotated Anomaly Detection Dataset
Sep 30, 2024
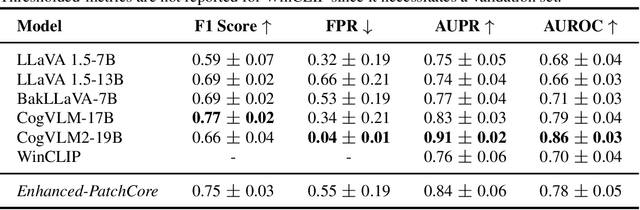
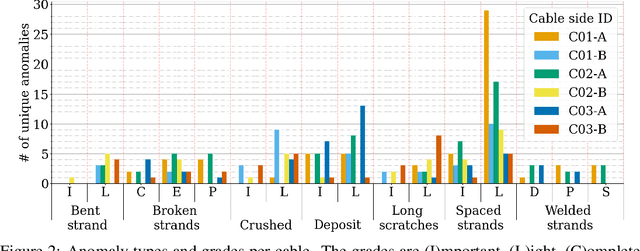
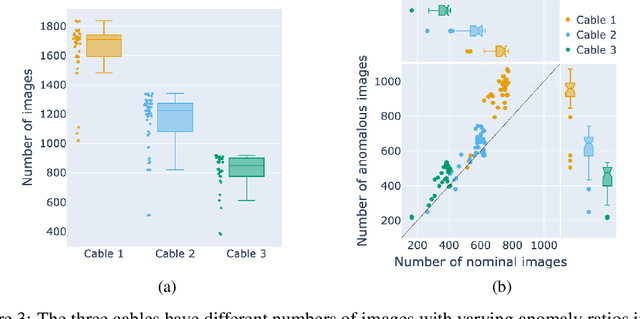
Machine learning models are increasingly being deployed in real-world contexts. However, systematic studies on their transferability to specific and critical applications are underrepresented in the research literature. An important example is visual anomaly detection (VAD) for robotic power line inspection. While existing VAD methods perform well in controlled environments, real-world scenarios present diverse and unexpected anomalies that current datasets fail to capture. To address this gap, we introduce $\textit{CableInspect-AD}$, a high-quality, publicly available dataset created and annotated by domain experts from Hydro-Qu\'ebec, a Canadian public utility. This dataset includes high-resolution images with challenging real-world anomalies, covering defects with varying severity levels. To address the challenges of collecting diverse anomalous and nominal examples for setting a detection threshold, we propose an enhancement to the celebrated PatchCore algorithm. This enhancement enables its use in scenarios with limited labeled data. We also present a comprehensive evaluation protocol based on cross-validation to assess models' performances. We evaluate our $\textit{Enhanced-PatchCore}$ for few-shot and many-shot detection, and Vision-Language Models for zero-shot detection. While promising, these models struggle to detect all anomalies, highlighting the dataset's value as a challenging benchmark for the broader research community. Project page: https://mila-iqia.github.io/cableinspect-ad/.
The KITMUS Test: Evaluating Knowledge Integration from Multiple Sources in Natural Language Understanding Systems
Dec 15, 2022Many state-of-the-art natural language understanding (NLU) models are based on pretrained neural language models. These models often make inferences using information from multiple sources. An important class of such inferences are those that require both background knowledge, presumably contained in a model's pretrained parameters, and instance-specific information that is supplied at inference time. However, the integration and reasoning abilities of NLU models in the presence of multiple knowledge sources have been largely understudied. In this work, we propose a test suite of coreference resolution tasks that require reasoning over multiple facts. Our dataset is organized into subtasks that differ in terms of which knowledge sources contain relevant facts. We evaluate state-of-the-art coreference resolution models on our dataset. Our results indicate that several models struggle to reason on-the-fly over knowledge observed both at pretrain time and at inference time. However, with task-specific training, a subset of models demonstrates the ability to integrate certain knowledge types from multiple sources.