 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCableInspect-AD: An Expert-Annotated Anomaly Detection Dataset
Sep 30, 2024
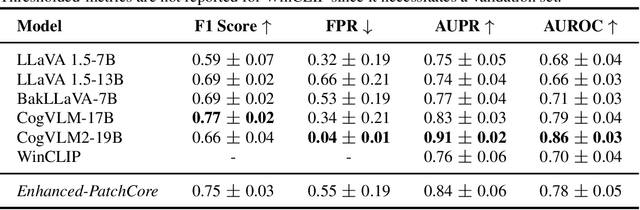
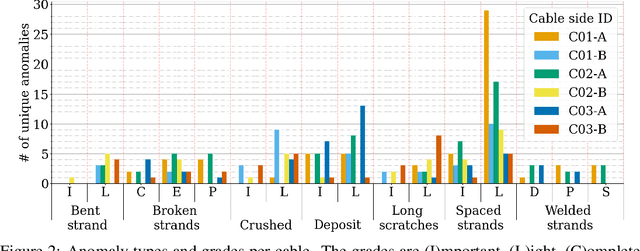
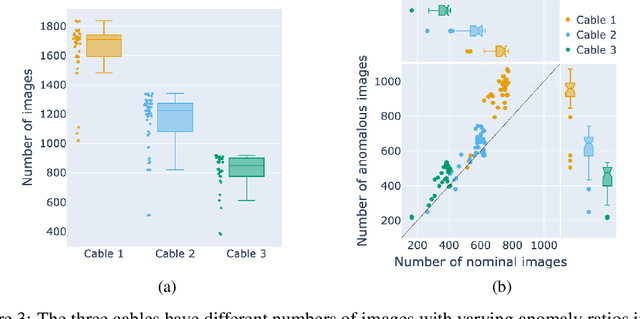
Machine learning models are increasingly being deployed in real-world contexts. However, systematic studies on their transferability to specific and critical applications are underrepresented in the research literature. An important example is visual anomaly detection (VAD) for robotic power line inspection. While existing VAD methods perform well in controlled environments, real-world scenarios present diverse and unexpected anomalies that current datasets fail to capture. To address this gap, we introduce $\textit{CableInspect-AD}$, a high-quality, publicly available dataset created and annotated by domain experts from Hydro-Qu\'ebec, a Canadian public utility. This dataset includes high-resolution images with challenging real-world anomalies, covering defects with varying severity levels. To address the challenges of collecting diverse anomalous and nominal examples for setting a detection threshold, we propose an enhancement to the celebrated PatchCore algorithm. This enhancement enables its use in scenarios with limited labeled data. We also present a comprehensive evaluation protocol based on cross-validation to assess models' performances. We evaluate our $\textit{Enhanced-PatchCore}$ for few-shot and many-shot detection, and Vision-Language Models for zero-shot detection. While promising, these models struggle to detect all anomalies, highlighting the dataset's value as a challenging benchmark for the broader research community. Project page: https://mila-iqia.github.io/cableinspect-ad/.
Self-supervised multimodal neuroimaging yields predictive representations for a spectrum of Alzheimer's phenotypes
Sep 07, 2022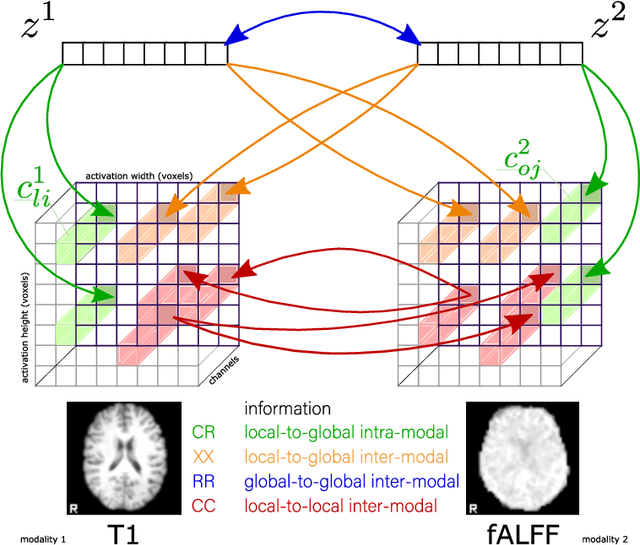

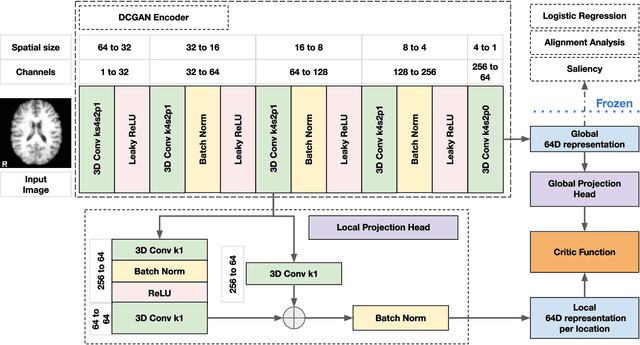
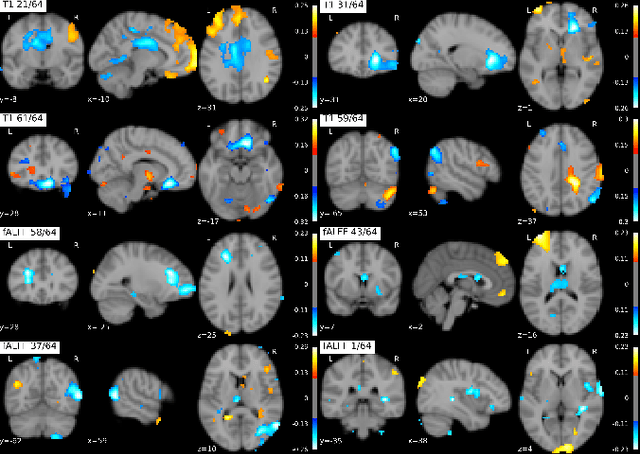
Recent neuroimaging studies that focus on predicting brain disorders via modern machine learning approaches commonly include a single modality and rely on supervised over-parameterized models.However, a single modality provides only a limited view of the highly complex brain. Critically, supervised models in clinical settings lack accurate diagnostic labels for training. Coarse labels do not capture the long-tailed spectrum of brain disorder phenotypes, which leads to a loss of generalizability of the model that makes them less useful in diagnostic settings. This work presents a novel multi-scale coordinated framework for learning multiple representations from multimodal neuroimaging data. We propose a general taxonomy of informative inductive biases to capture unique and joint information in multimodal self-supervised fusion. The taxonomy forms a family of decoder-free models with reduced computational complexity and a propensity to capture multi-scale relationships between local and global representations of the multimodal inputs. We conduct a comprehensive evaluation of the taxonomy using functional and structural magnetic resonance imaging (MRI) data across a spectrum of Alzheimer's disease phenotypes and show that self-supervised models reveal disorder-relevant brain regions and multimodal links without access to the labels during pre-training. The proposed multimodal self-supervised learning yields representations with improved classification performance for both modalities. The concomitant rich and flexible unsupervised deep learning framework captures complex multimodal relationships and provides predictive performance that meets or exceeds that of a more narrow supervised classification analysis. We present elaborate quantitative evidence of how this framework can significantly advance our search for missing links in complex brain disorders.
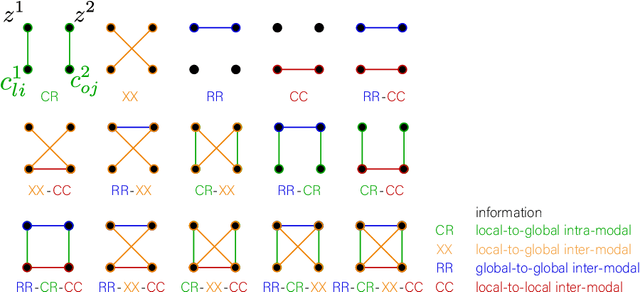
Taxonomy of multimodal self-supervised representation learning
Dec 29, 2020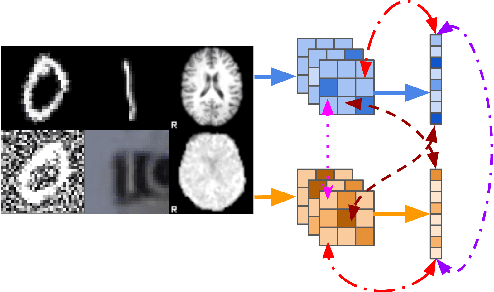
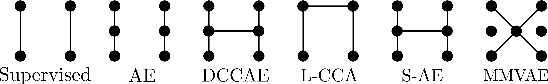
Sensory input from multiple sources is crucial for robust and coherent human perception. Different sources contribute complementary explanatory factors and get combined based on factors they share. This system motivated the design of powerful unsupervised representation-learning algorithms. In this paper, we unify recent work on multimodal self-supervised learning under a single framework. Observing that most self-supervised methods optimize similarity metrics between a set of model components, we propose a taxonomy of all reasonable ways to organize this process. We empirically show on two versions of multimodal MNIST and a multimodal brain imaging dataset that (1) multimodal contrastive learning has significant benefits over its unimodal counterpart, (2) the specific composition of multiple contrastive objectives is critical to performance on a downstream task, (3) maximization of the similarity between representations has a regularizing effect on a neural network, which sometimes can lead to reduced downstream performance but still can reveal multimodal relations. Consequently, we outperform previous unsupervised encoder-decoder methods based on CCA or variational mixtures MMVAE on various datasets on linear evaluation protocol.
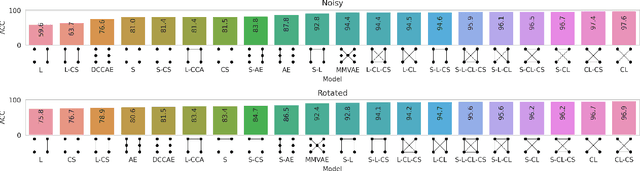
On self-supervised multi-modal representation learning: An application to Alzheimer's disease
Dec 25, 2020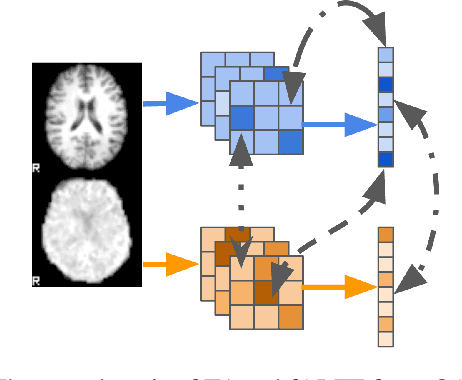
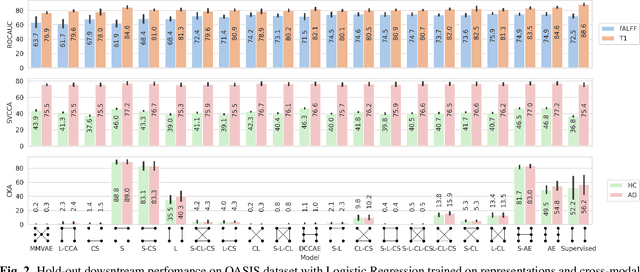
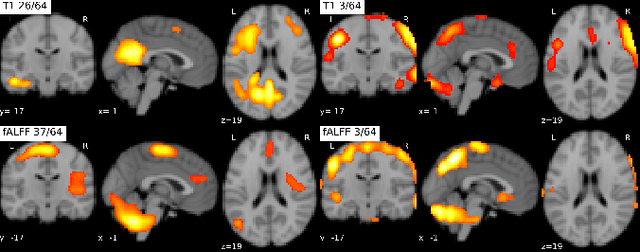
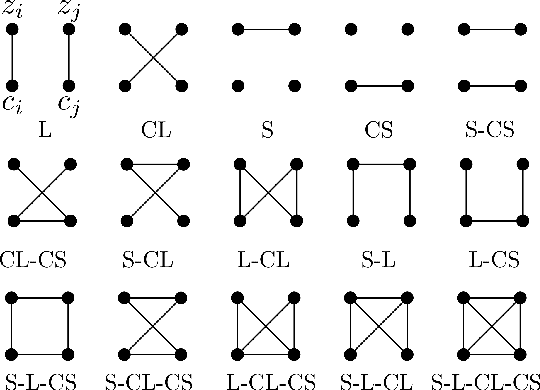
Introspection of deep supervised predictive models trained on functional and structural brain imaging may uncover novel markers of Alzheimer's disease (AD). However, supervised training is prone to learning from spurious features (shortcut learning) impairing its value in the discovery process. Deep unsupervised and, recently, contrastive self-supervised approaches, not biased to classification, are better candidates for the task. Their multimodal options specifically offer additional regularization via modality interactions. In this paper, we introduce a way to exhaustively consider multimodal architectures for contrastive self-supervised fusion of fMRI and MRI of AD patients and controls. We show that this multimodal fusion results in representations that improve the results of the downstream classification for both modalities. We investigate the fused self-supervised features projected into the brain space and introduce a numerically stable way to do so.
Cross-Modal Information Maximization for Medical Imaging: CMIM
Oct 20, 2020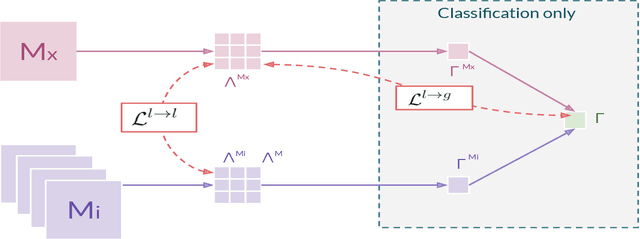

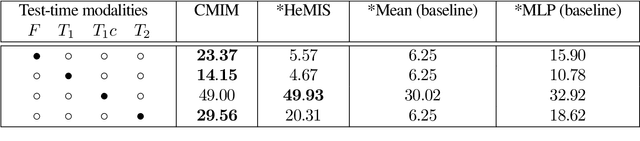
In hospitals, data are siloed to specific information systems that make the same information available under different modalities such as the different medical imaging exams the patient undergoes (CT scans, MRI, PET, Ultrasound, etc.) and their associated radiology reports. This offers unique opportunities to obtain and use at train-time those multiple views of the same information that might not always be available at test-time. In this paper, we propose an innovative framework that makes the most of available data by learning good representations of a multi-modal input that are resilient to modality dropping at test-time, using recent advances in mutual information maximization. By maximizing cross-modal information at train time, we are able to outperform several state-of-the-art baselines in two different settings, medical image classification, and segmentation. In particular, our method is shown to have a strong impact on the inference-time performance of weaker modalities.
Navigation Agents for the Visually Impaired: A Sidewalk Simulator and Experiments
Oct 29, 2019


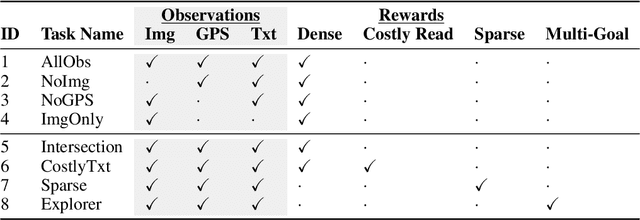
Millions of blind and visually-impaired (BVI) people navigate urban environments every day, using smartphones for high-level path-planning and white canes or guide dogs for local information. However, many BVI people still struggle to travel to new places. In our endeavor to create a navigation assistant for the BVI, we found that existing Reinforcement Learning (RL) environments were unsuitable for the task. This work introduces SEVN, a sidewalk simulation environment and a neural network-based approach to creating a navigation agent. SEVN contains panoramic images with labels for house numbers, doors, and street name signs, and formulations for several navigation tasks. We study the performance of an RL algorithm (PPO) in this setting. Our policy model fuses multi-modal observations in the form of variable resolution images, visible text, and simulated GPS data to navigate to a goal door. We hope that this dataset, simulator, and experimental results will provide a foundation for further research into the creation of agents that can assist members of the BVI community with outdoor navigation.
A Survey of Mobile Computing for the Visually Impaired
Nov 27, 2018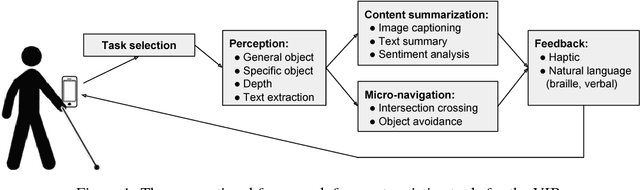
The number of visually impaired or blind (VIB) people in the world is estimated at several hundred million. Based on a series of interviews with the VIB and developers of assistive technology, this paper provides a survey of machine-learning based mobile applications and identifies the most relevant applications. We discuss the functionality of these apps, how they align with the needs and requirements of the VIB users, and how they can be improved with techniques such as federated learning and model compression. As a result of this study we identify promising future directions of research in mobile perception, micro-navigation, and content-summarization.
Distribution Matching Losses Can Hallucinate Features in Medical Image Translation
Oct 03, 2018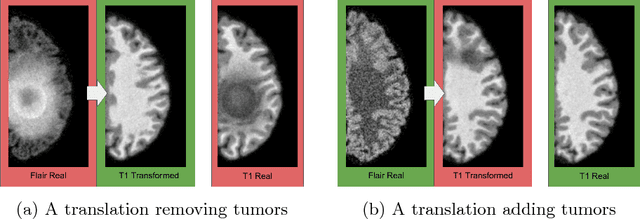
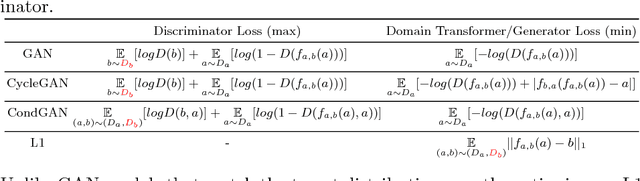
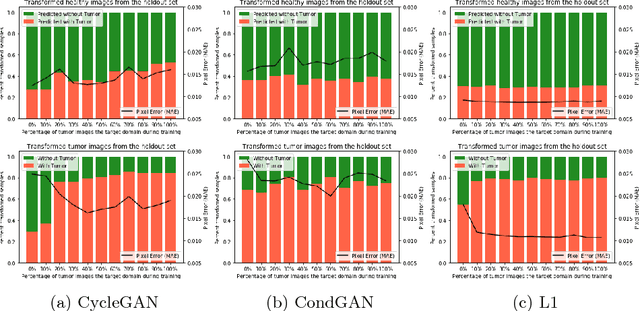

This paper discusses how distribution matching losses, such as those used in CycleGAN, when used to synthesize medical images can lead to mis-diagnosis of medical conditions. It seems appealing to use these new image synthesis methods for translating images from a source to a target domain because they can produce high quality images and some even do not require paired data. However, the basis of how these image translation models work is through matching the translation output to the distribution of the target domain. This can cause an issue when the data provided in the target domain has an over or under representation of some classes (e.g. healthy or sick). When the output of an algorithm is a transformed image there are uncertainties whether all known and unknown class labels have been preserved or changed. Therefore, we recommend that these translated images should not be used for direct interpretation (e.g. by doctors) because they may lead to misdiagnosis of patients based on hallucinated image features by an algorithm that matches a distribution. However there are many recent papers that seem as though this is the goal.
* Published at Medical Image Computing & Computer Assisted Intervention (MICCAI 2018). An abstract is published at the Medical Imaging with Deep Learning Conference (MIDL 2018) as "How to Cure Cancer (in images) with Unpaired Image Translation"
Learning to rank for censored survival data
Jun 08, 2018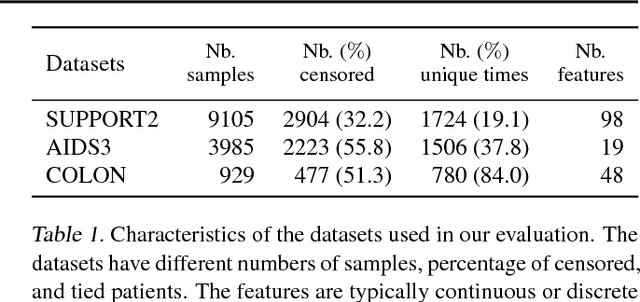
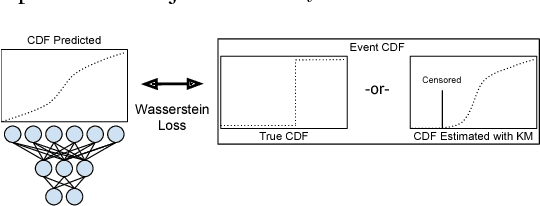
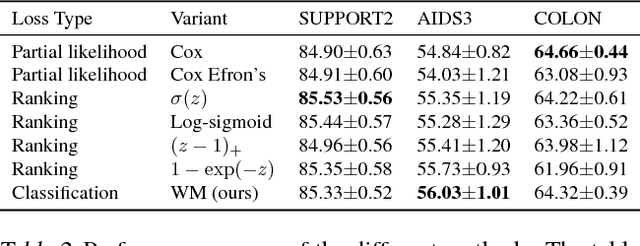
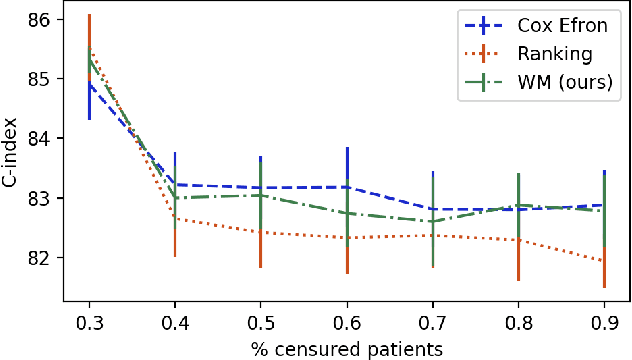
Survival analysis is a type of semi-supervised ranking task where the target output (the survival time) is often right-censored. Utilizing this information is a challenge because it is not obvious how to correctly incorporate these censored examples into a model. We study how three categories of loss functions, namely partial likelihood methods, rank methods, and our classification method based on a Wasserstein metric (WM) and the non-parametric Kaplan Meier estimate of the probability density to impute the labels of censored examples, can take advantage of this information. The proposed method allows us to have a model that predict the probability distribution of an event. If a clinician had access to the detailed probability of an event over time this would help in treatment planning. For example, determining if the risk of kidney graft rejection is constant or peaked after some time. Also, we demonstrate that this approach directly optimizes the expected C-index which is the most common evaluation metric for ranking survival models.
Rule-Mining based classification: a benchmark study
Jun 30, 2017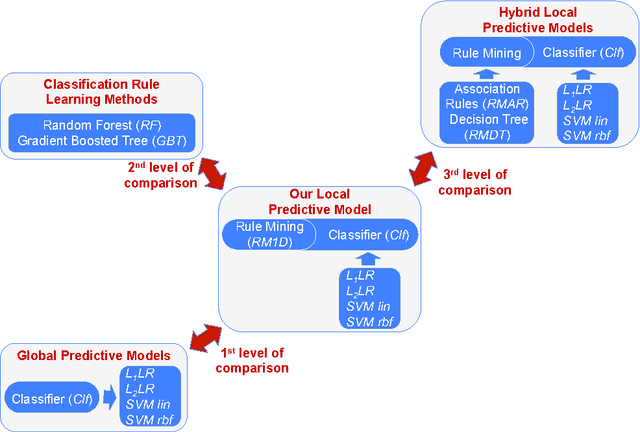
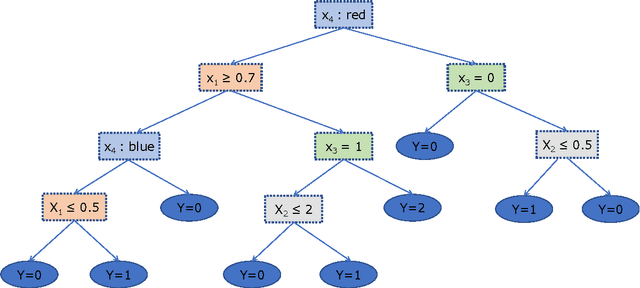
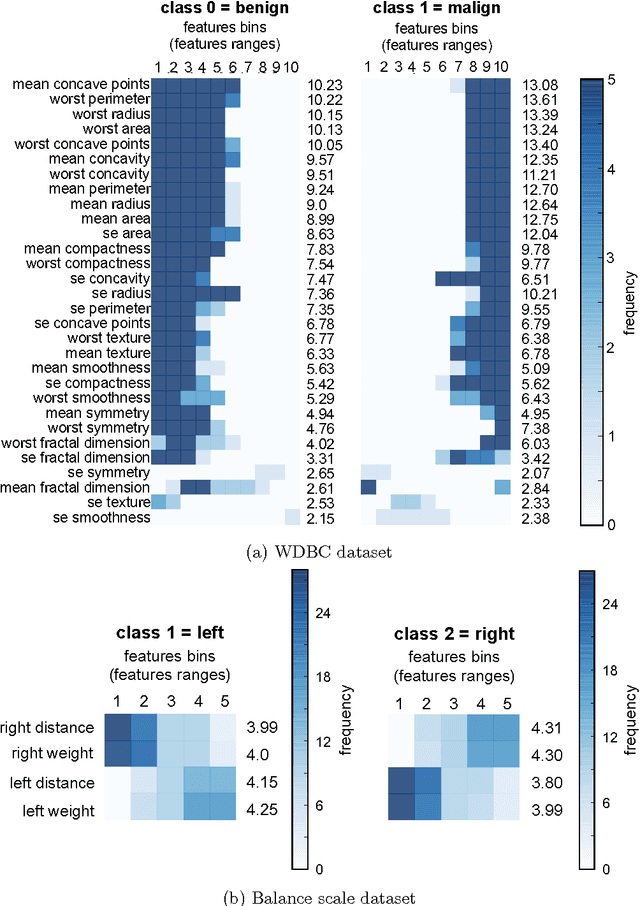
This study proposed an exhaustive stable/reproducible rule-mining algorithm combined to a classifier to generate both accurate and interpretable models. Our method first extracts rules (i.e., a conjunction of conditions about the values of a small number of input features) with our exhaustive rule-mining algorithm, then constructs a new feature space based on the most relevant rules called "local features" and finally, builds a local predictive model by training a standard classifier on the new local feature space. This local feature space is easy interpretable by providing a human-understandable explanation under the explicit form of rules. Furthermore, our local predictive approach is as powerful as global classical ones like logistic regression (LR), support vector machine (SVM) and rules based methods like random forest (RF) and gradient boosted tree (GBT).